pandas数据清洗常用操作总结 (一)
文章目录
- 操作环境: pandas-0.24.2, jupyter notebook
- 1 读取数据、查看数据信息
- 2 查看数据内容
- 3 数据描述
- 4 添加标签
- 5 插入操作
- 6 删除操作
- 7 取列和行
- 8 取单元格数据
操作环境: pandas-0.24.2, jupyter notebook
本教程以加拿大University of New Brunswick的NSL-KDD数据集为操作对象,来进行pandas常用操作总结
包含了数据清理过程中的常用操作, 有些操作只是罗列出来,(需要使用的)对照本教程到pandas官网文档查询。
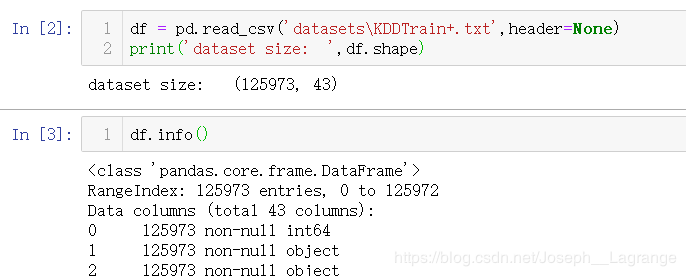
1 读取数据、查看数据信息
df.info()
样本数量:125973, 特征数量:43
non-null表明没有缺失值
43个特征数据类型:15(float) + 24(int) + 4(object)

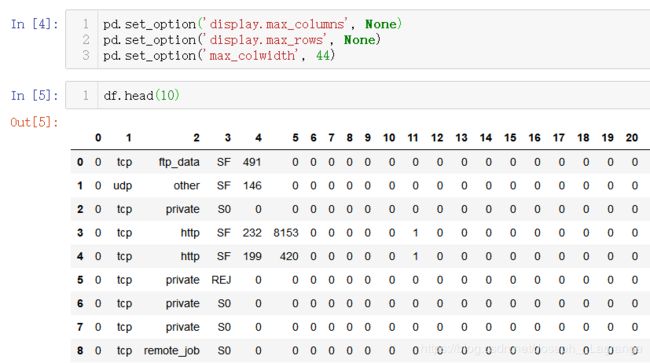
2 查看数据内容
pd.set_option(‘display.max_columns’, None)
pd.set_option(‘display.max_rows’, None)
pd.set_option(‘max_colwidth’, 44)
df.head(10)
3 数据描述
df.describe()
数量、平均值、标准差、最小值、最大值、中值、第二、四分位数

4 添加标签
自定义一个columns和index列表
df.columns = columns
df.index=index
df.rename(index={ }, columns={ }, inplace=True)

5 插入操作
append、concat、join、merge、
DataFrame.append(other, ignore_index=False, verify_integrity=False, sort=None)
pandas.concat(objs, axis=0, join=‘outer’, join_axes=None, ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False, sort=None, copy=True)
DataFrame.join(other, on=None, how=‘left’, lsuffix=’’, rsuffix=’’, sort=False)
DataFrame.merge(right, how=‘inner’, on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=(’_x’, ‘_y’), copy=True, indicator=False, validate=None)
函数可以到pandas官网去查询用法
另外,还可以直接用标签插入一列 df.[‘new_label’]
6 删除操作
drop
DataFrame.drop(labels=None, axis=0, index=None, columns=None, level=None, inplace=False, errors=‘raise’)
drop 可以按索引删除,也可以按标签删除
7 取列和行
(1)取行 (‘a’,‘b’,‘c’为行标签)
-------------索引操作
取’a’行:df.iloc[[0], :]
取’a’行:df[:0]只能切片
------------标签操作
取’a’行:df.loc[‘a’]
(2)取列 (‘‘A’,‘B’,'C’为列标签)
----索引操作
取‘A’列:df.iloc[:,[0]]
----标签操作
取‘A’列:df.loc[:, [‘A’]], df[‘A’]
8 取单元格数据
df.iat[0,0]
df.at[‘a’, ‘A’]
对于数据集中的缺失值、字符串数据、无意义的离散值数据处理操作,可参照 pandas数据清洗常用操作总结(二)