Python爬虫实战(一) — Pixabay图片下载器
前言
最近学习数据分析的时候,突然对网络爬虫有了兴趣,经过一些练习和资料的参考,编写了一些简单的爬虫代码,今天,我们来爬取Pixabay网站的图片。
Pixabay我最常用的一家图片网站,可以说是全球最大的免费图片网站了。图多而且种类足够丰富。最重要的是这些图片没有版权问题,可以放心使用。
本篇目标
- 提取指定关键词下的图片,并实现自动下载。
- 实现将自动下载的图片保存到指定文件夹下,并自动命名
- 实现指定下载图片范围
Pixabay是不需要登录的,所以也没必要用到Cookie,而且Pixabay网站对于爬虫者比较仁慈,没有使用太高的反爬虫技术,但是依照我现有的能力,只能爬取缩略图,而原始图片,因为Pixabay有异步加载技术,所以只能静态爬取,等以后我学会了PhantonJ和Selenium再重新编写动态爬取代码。
好,现在我们尝试爬取一下Pixabay网站的图片吧。
1.确定URL并抓取页面代码
首先我们确定好页面的URL是https://pixabay.com/zh/photos/?q=Apple&image_type=&cat=&min_height=&min_width=&order=popular&pagi=1
可以观察到Apple使我们需要查找的关键词,pagi对应当前页数
下面我们首先定义一个类,然后定义init方法
class Spider():
def __init__(self):
self.keyword = input('请输入搜索关键词(推荐输入英文):')
self.siteURL = 'http://pixabay.com/zh/photos/?image_type=&cat=&min_width=&min_height=&q=' + str(self.keyword) + '&order=popular'
2.定义一个获取页源码的方法
def getSource(self, url):
result = requests.get(url).text
return result
然后我们获取图片的页数,点击F12打开控制台,我们发现图片总页数所对应的代码位置
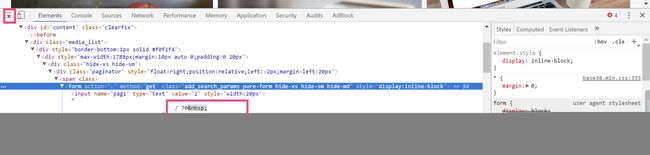
可以很容易的写出对应的正则表达式
re.compile('.*?/ (.*?) .*?', re.S)
items = re.search(pattern, result)
return items
3.提取图片网址
下面,我们就需要提取页面图片的网址了,经过查看源码发现,其中图片对应于两种网址,前16张是一种,后面的是另外一种


接下来,我们设计两种匹配模式
re.compile('
-(.*?)__340.*?')</code></li>)
继续完善我们的代码
def getItem1(self, url):
result = self.getSource(url)
pattern1 = re.compile('![]()
-(.*?)__340.*?')
4.保存图片
这里讲一下思路,首先自动创建一个文件夹,将图片按页码的不同分别放入不同的文件夹下,自动命名图片并保存。
完整代码如下
请查看我的
Github
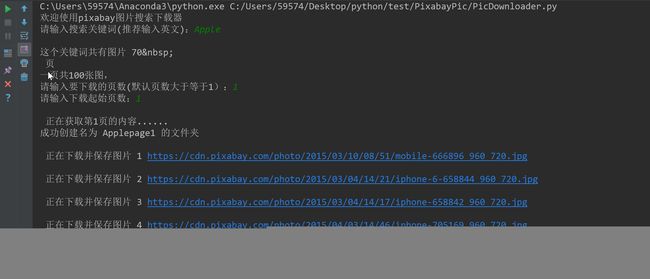
运行结果
控制台界面
文件夹下内容

小结
快要开学了,时间越来越少,以后更新的时间可能会延长,这些天几乎一天一篇,工作量有点大,也希望大家多多支持,同时也希望大家都能尊重我的付出,转载我的文章请注明出处。
最后,也希望大家关注我的个人博客 HD Blog
谢谢~