Python数据扩展包之Pandas
官方文档:http://pandas.pydata.org/pandas-docs/stable/io.html
如果用 python 的列表和字典来作比较, 那么可以说 Numpy 是列表形式的,没有数值标签,而 Pandas 就是字典形式。Pandas是基于Numpy构建的,让Numpy为中心的应用变得更加简单。
pandas主要的数据结构:Series和DataFrame。
部分笔记:
与python的集合不同,pandas的Index可以包含重复的标签:
基本介绍:
import pandas as pd
import numpy as np
s = pd.Series([1,3,6,np.NaN,44,1])
dates = pd.date_range('20171113',periods=6)
pd.DataFrame(np.random.randn(6,4),index = dates ,columns=['a','b','c','d'])
df1 = pd.DataFrame(np.arange(12).reshape(3,4))
df2 = pd.DataFrame({'A': 1.,
'B': pd.Timestamp('20130102'),
'C': pd.Series(1, index=list(range(4)), dtype='float32'),
'D': np.array([3] * 4, dtype='int32'),
'E': pd.Categorical(["test", "train", "test", "train"]),
'F': 'foo'})
print "df2:",df2,"\n"
print"------------------------------------cutting line---------------------------------"
#类型、行索引、列索引、值
print df2.dtypes,"\n",df2.index,df2.columns,df2.values,"\n"
print"------------------------------------cutting line---------------------------------"
#数据的总结
print df2.describe
print"------------------------------------cutting line---------------------------------"
#转置
print df2.transpose
print"------------------------------------cutting line---------------------------------"
print df2.T
print"------------------------------------cutting line---------------------------------"
#对索引排序输出
print df2.sort_index(axis = 1,ascending=False) #1 : row
#对值排序输出
print df2.sort_values(by='E')选择数据:
import pandas as pd
import numpy as np
dates = pd.date_range("20171113",periods=6)
df = pd.DataFrame(np.arange(24).reshape(6,4),index = dates,columns=['A','B','C','D'])
print df
print "------------------------------------------------cutting line------------------------------------------"
choose1 = df.A
choose2 = df['A']
choose3 = df[2:4] #row
choose4 = df['20171113':'20171115']
print choose1,choose2,choose3,choose4
print "------------------------------------------------cutting line------------------------------------------"
#根据标签筛选
choose5 = df.loc['20171113']
choose6 = df.loc[:,['A','C']]
print choose5,choose6
print "------------------------------------------------cutting line------------------------------------------"
choose7 = df.iloc[[1,3,5],[0,3]] #根据序列筛选
choose8 = df.ix[[1,3],['A','C']] #混合筛选
choose9 = df[df.A > 10] #条件筛选
print choose7, choose8, choose9设置值:
import pandas as pd
import numpy as np
dates = pd.date_range('20171113',periods=6)
df = pd.DataFrame(np.arange(24).reshape(6,4),index=dates,columns=['A','B','C','D'])
print df
print "------------------------------cutting line------------------------------"
df.loc['20171117']=40
df.iloc[2,2] =50
df.D[df.D<10] = 0
df['F']=np.nan
df['G'] =pd.Series([6,7,8,9,10,3],index=dates)
df['H'] = pd.Series([1,2,3,4,5,6], index=pd.date_range('20171113',periods=6))
print df处理丢失数据:
import pandas as pd
import numpy as np
dates = pd.date_range('20171113',periods=6)
df = pd.DataFrame(np.arange(24).reshape(6,4),index=dates,columns=['A','B','C','D'])
#置空
df.iloc[2,2] =np.nan
df.iloc[0,1] = np.nan
df.iloc[1,2] = np.nan
#axis为行,去掉有Nan的行
print df.dropna(
axis = 0, #0:行,1:列
how='any' #只要存在就drop,‘all’全部是Nan才drop
)
#用0代替Nan
print df.fillna(value = 0)
#判断是否有缺失值Nan,True为有
print df.isnull()
#检测数据中是否存在Nan,存在就返回True
print np.any(df.isnull())==True
#judge the column
print df.isnull().any()
print df.isnull().any().all()导入导出:
Pandas可以读取与存取的资料格式有很多种,比如csv、excel、json、html、pickle等…官方文件


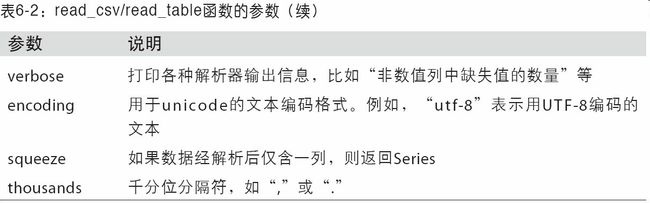
| Format Type | Data Description | Reader | Writer |
|---|---|---|---|
| text | CSV | read_csv | to_csv |
| text | JSON | read_json | to_json |
| text | HTML | read_html | to_html |
| text | Local clipboard | read_clipboard | to_clipboard |
| binary | MS Excel | read_excel | to_excel |
| binary | HDF5 Format | read_hdf | to_hdf |
| binary | Feather Format | read_feather | to_feather |
| binary | Parquet Format | read_parquet | to_parquet |
| binary | Msgpack | read_msgpack | to_msgpack |
| binary | Stata | read_stata | to_stata |
| binary | SAS | read_sas | |
| binary | Python Pickle Format | read_pickle | to_pickle |
| SQL | SQL | read_sql | to_sql |
| SQL | Google Big Query | read_gbq | to_gbq |
import pandas as pd
#读取csv
data = pd.read_csv('students.csv')
print data
#存为pickle
data.to_pickle('student.pickle')合并:
- Concat
import pandas as pd
import numpy as np
# concatenating
# ignore index
df1 = pd.DataFrame(np.ones((3,4))*0, columns=['a','b','c','d'])
df2 = pd.DataFrame(np.ones((3,4))*1, columns=['a','b','c','d'])
df3 = pd.DataFrame(np.ones((3,4))*2, columns=['a','b','c','d'])
res = pd.concat([df1, df2, df3], axis=0, ignore_index=True)
#axis :0->纵向;1->横向
# join, ('inner', 'outer')
df1 = pd.DataFrame(np.ones((3,4))*0, columns=['a','b','c','d'], index=[1,2,3])
df2 = pd.DataFrame(np.ones((3,4))*1, columns=['b','c','d', 'e'], index=[2,3,4])
res = pd.concat([df1, df2], axis=1, join='outer') #纵向‘外’合并,column方式:扩张,不是共同的Nan填充
res = pd.concat([df1, df2], axis=1, join='inner') #纵向‘内’合并column方式:扩张,不是共同的删除
# join_axes:按照df1.index横向合并
res = pd.concat([df1, df2], axis=1, join_axes=[df1.index])
# append:只有纵向合并没有横向合并
df1 = pd.DataFrame(np.ones((3,4))*0, columns=['a','b','c','d'])
df2 = pd.DataFrame(np.ones((3,4))*1, columns=['a','b','c','d'])
df2 = pd.DataFrame(np.ones((3,4))*1, columns=['b','c','d', 'e'], index=[2,3,4])
res = df1.append(df2, ignore_index=True)
res = df1.append([df2, df3])
s1 = pd.Series([1,2,3,4], index=['a','b','c','d'])
res = df1.append(s1, ignore_index=True)
print(res)- merge
用于两组有key column的数据,统一索引的数据. 通常也被用在Database的处理当中.
import pandas as pd
# merging two df by key/keys. (may be used in database)
left = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
print(left)
print(right)
res = pd.merge(left, right, on='key')
print(res)
# consider two keys
left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'],
'key2': ['K0', 'K1', 'K0', 'K1'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],
'key2': ['K0', 'K0', 'K0', 'K0'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
print(left)
print(right)
res = pd.merge(left, right, on=['key1', 'key2'], how='inner') # default for how='inner'
# how = ['left', 'right', 'outer', 'inner']
res = pd.merge(left, right, on=['key1', 'key2'], how='left')
print(res)
# indicator
df1 = pd.DataFrame({'col1':[0,1], 'col_left':['a','b']})
df2 = pd.DataFrame({'col1':[1,2,2],'col_right':[2,2,2]})
print(df1)
print(df2)
res = pd.merge(df1, df2, on='col1', how='outer', indicator=True)#True:合并的一组放在新的一列
# give the indicator a custom name
res = pd.merge(df1, df2, on='col1', how='outer', indicator='indicator_column')
# merged by index
left = pd.DataFrame({'A': ['A0', 'A1', 'A2'],
'B': ['B0', 'B1', 'B2']},
index=['K0', 'K1', 'K2'])
right = pd.DataFrame({'C': ['C0', 'C2', 'C3'],
'D': ['D0', 'D2', 'D3']},
index=['K0', 'K2', 'K3'])
print(left)
print(right)
# left_index and right_index
res = pd.merge(left, right, left_index=True, right_index=True, how='outer')
res = pd.merge(left, right, left_index=True, right_index=True, how='inner')
# overlapping : suffixes
boys = pd.DataFrame({'k': ['K0', 'K1', 'K2'], 'age': [1, 2, 3]})
girls = pd.DataFrame({'k': ['K0', 'K0', 'K3'], 'age': [4, 5, 6]})
res = pd.merge(boys, girls, on='k', suffixes=['_boy', '_girl'], how='inner')
print(res)画图
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
#create Series
data = pd.Series(np.random.randn(1000), index=np.arange(1000))
data = data.cumsum()
#线性
data.plot()
plt.show()
# create DataFrame
data = pd.DataFrame(np.random.randn(1000, 4), index=np.arange(1000), columns=list("ABCD"))
data = data.cumsum()
# plot methods: 'bar', 'hist', 'box', 'kde', 'area', scatter', hexbin', 'pie'
#散点图
data.plot.scatter(x='A', y='C', color='LightGreen', label='Class 2', ax=ax)plt.show()pandas常用函数:
Series
- Series是一种类似于一维数组的对象,它由一组数据(各种NumPy数据类型)以及一组与之相关的数据标签(即索引)组成。仅由一组数据即可产生最简单的Series。Series的字符串表现形式为:索引在左边,值在右边。由于我们没有为数据指定索引,于是会自动创建一个0到N-1(N为数据的长度)的整数型索引。你可以通过Series 的values和index属性获取其数组表示形式和索引对象:
-
还可以将Series看成是一个定长的有序字典,因为它是索引值到数据值的一个映射。它可以用在许多原本需要字典参数的函数中。如果只传入一个字典,则结果Series中的索引就是原字典的键(有序排列)。可以传入排好序的字典的键以改变顺序:
-
NaN(即“非数字”(not a number),在pandas中,它用于表示缺失或NA值。
-
Series最重要的一个功能是,它会根据运算的索引标签自动对齐数据:
Series可以运用ndarray或字典的几乎所有索引操作和函数,融合了字典和ndarray的优点。
| 属性 | 说明 |
| values | 获取数组 |
| index | 获取索引 |
| name | values的name |
| index.name | 索引的name |

Series常用属性
| 函数 | 说明 |
| Series([x,y,...])Series({'a':x,'b':y,...}, index=param1) | 生成一个Series,带有一个可以对各个数据点进行标记的索引 |
| Series.copy() | 复制一个Series |
| Series.drop(index) | 丢弃指定项 |
| Series.map(f) | 应用元素级函数 |
| 排序函数 | 说明 |
| Series.sort_index(ascending=True) | 根据索引返回已排序的新对象 |
| Series.sort_values(ascending=True) | 根据值排序,任何缺失值默认都会被放到Series的末尾: |
| Series.order(ascending=True) | 根据值返回已排序的对象,NaN值在末尾 |
| Series.rank(method='average', ascending=True, axis=0) | 为各组分配一个平均排名 |
|
|
|
| df.argmax() df.argmin() |
返回含有最大值的索引位置 返回含有最小值的索引位置 |
| Series.reindex([x,y,...], fill_value=NaN) Series.reindex([x,y,...], method=NaN) Series.reindex(columns=[x,y,...])
|
重返回一个适应新索引的新对象,将缺失值填充为fill_value 返回适应新索引的新对象,填充方式为method 对列进行重新索引 |


Series常用函数
reindex的method选项:
ffill, bfill 向前填充/向后填充
pad, backfill 向前搬运,向后搬运
fillvalue 填充值
rank的method选项
'average' 在相等分组中,为各个值分配平均排名
'max','min' 使用整个分组中的最小排名
'first' 按值在原始数据中出现的顺序排名
案例:
对于时间序列这样的有序数据,重新索引时可能需要做一些插值处理。method选项即可达到此目的,例如,使用ffill可以实现前向值填充:
In [95]: obj3 = pd.Series(['blue', 'purple', 'yellow'], index=[0, 2, 4])
In [96]: obj3
Out[96]:
0 blue
2 purple
4 yellow
dtype: object
In [97]: obj3.reindex(range(6), method='ffill')
Out[97]:
0 blue
1 blue
2 purple
3 purple
4 yellow
5 yellow
dtype: object借助DataFrame,reindex可以修改(行)索引和列。只传递一个序列时,会重新索引结果的行:
In [98]: frame = pd.DataFrame(np.arange(9).reshape((3, 3)),
....: index=['a', 'c', 'd'],
....: columns=['Ohio', 'Texas', 'California'])
In [99]: frame
Out[99]:
Ohio Texas California
a 0 1 2
c 3 4 5
d 6 7 8
In [100]: frame2 = frame.reindex(['a', 'b', 'c', 'd'])
In [101]: frame2
Out[101]:
Ohio Texas California
a 0.0 1.0 2.0
b NaN NaN NaN
c 3.0 4.0 5.0
d 6.0 7.0 8.0DataFrame
DataFrame是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔值等)。DataFrame既有行索引也有列索引,它可以被看做由Series组成的字典(共用同一个索引)。
DataFrame可以通过类似字典的方式或者.columnname的方式将列获取为一个Series。行也可以通过位置或名称的方式进行获取。
为不存在的列赋值会创建新列。
>>> del frame[column] # 删除列
| 属性 | 说明 |
| values | DataFrame的值 |
| index | 行索引 |
| index.name | 行索引的名字 |
| columns | 列索引 |
| columns.name | 列索引的名字 |
| ix | 返回行的DataFrame |
| ix[[x,y,...], [x,y,...]] | 对行重新索引,然后对列重新索引 |
| T | frame行列转置 |
DataFrame常用属性
- 通过类似字典标记a[colum]的方式或属性a.column的方式,可以将DataFrame的列获取为一个Series列;
- 行也可以通过位置a.loc[index]或名称的方式进行获取,比如用loc属性(稍后将对此进行详细讲解):
| 函数 | 说明 |
| DataFrame(dict, columns=dict.index, index=[dict.columnnum]) DataFrame(二维ndarray) DataFrame(由数组、列表或元组组成的字典) DataFrame(NumPy的结构化/记录数组) DataFrame(由Series组成的字典) DataFrame(由字典组成的字典) DataFrame(字典或Series的列表) DataFrame(由列表或元组组成的列表) DataFrame(DataFrame) DataFrame(NumPy的MaskedArray) |
构建DataFrame 数据矩阵,还可以传入行标和列标 每个序列会变成DataFrame的一列。所有序列的长度必须相同 类似于“由数组组成的字典” 每个Series会成为一列。如果没有显式制定索引,则各Series的索引会被合并成结果的行索引 各内层字典会成为一列。键会被合并成结果的行索引。 各项将会成为DataFrame的一行。索引的并集会成为DataFrame的列标。 类似于二维ndarray 沿用DataFrame 类似于二维ndarray,但掩码结果会变成NA/缺失值
|
| df.reindex([x,y,...], fill_value=NaN, limit) df.reindex([x,y,...], method=NaN) df.reindex([x,y,...], columns=[x,y,...],copy=True) |
返回一个适应新索引的新对象,将缺失值填充为fill_value,最大填充量为limit 返回适应新索引的新对象,填充方式为method 同时对行和列进行重新索引,默认复制新对象。 |
| df.drop(index, axis=0) | 丢弃指定轴上的指定项。 |
| 排序函数 | 说明 |
| df.sort_index(axis=0, ascending=True) df.sort_index(by=[a,b,...]) |
根据索引排序 |
| 汇总统计函数 | 说明 |
|
|
|
| df.count() | 非NaN的数量 |
| df.describe() | 一次性产生多个汇总统计 |
| df.min() df.max() |
最小值 最大值 |
| df.idxmax(axis=0, skipna=True) df.idxmin(axis=0, skipna=True) |
返回含有最大值的index的Series 返回含有最小值的index的Series |
| df.quantile(axis=0) | 计算样本的分位数 |
| df.sum(axis=0, skipna=True, level=NaN)
df.mean(axis=0, skipna=True, level=NaN)
df.median(axis=0, skipna=True, level=NaN)
df.mad(axis=0, skipna=True, level=NaN)
df.var(axis=0, skipna=True, level=NaN)
df.std(axis=0, skipna=True, level=NaN)
df.skew(axis=0, skipna=True, level=NaN) df.kurt(axis=0, skipna=True, level=NaN)
df.cumsum(axis=0, skipna=True, level=NaN)
df.cummin(axis=0, skipna=True, level=NaN)
df.cummax(axis=0, skipna=True, level=NaN)
df.cumprod(axis=0, skipna=True, level=NaN)
df.diff(axis=0)
df.pct_change(axis=0) |
返回一个含有求和小计的Series,,NA值会自动被排除,除非整个切片(这里指的是行或列)都是NA。通过skipna选项可以禁用该功能。有些方法(如idxmin和idxmax)返回的是间接统计(比如达到最小值或最大值的索引)
返回一个含有平均值的Series 返回一个含有算术中位数的Series 返回一个根据平均值计算平均绝对离差的Series 返回一个方差的Series 返回一个标准差的Series 返回样本值的偏度(三阶距) 返回样本值的峰度(四阶距) 返回样本的累计和 返回样本的累计最大值 返回样本的累计最小值 返回样本的累计积 返回样本的一阶差分 返回样本的百分比数变化 |
|
|
|
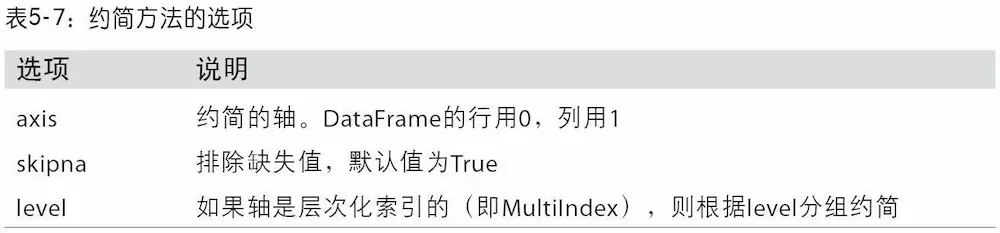
| Series和DataFrame的算术方法。它们每个都有一个副本,以字母r开头,它会翻转参数。因此这两个语句是等价的:
|
|
| 计算函数 | 说明 |
| df.add(df2, fill_value=NaN, axist=1) df.sub(df2, fill_value=NaN, axist=1) df.div(df2, fill_value=NaN, axist=1) df.mul(df2, fill_value=NaN, axist=1) |
元素级相加,对齐时找不到元素默认用fill_value 元素级相减,对齐时找不到元素默认用fill_value 元素级相除,对齐时找不到元素默认用fill_value 元素级相乘,对齐时找不到元素默认用fill_value |
| df.apply(f, axis=0) | 将f函数应用到由各行各列所形成的一维数组上 |
| df.applymap(f) | 将f函数应用到各个元素上 |
| df.cumsum(axis=0, skipna=True) | 累加,返回累加后的dataframe |

Dataframe常用函数
笔记:在一开始设计pandas时,我觉得用frame[:, col]选取列过于繁琐(也容易出错),因为列的选择是非常常见的操作。我做了些取舍,将花式索引的功能(标签和整数)放到了ix运算符中。在实践中,这会导致许多边缘情况,数据的轴标签是整数,所以pandas团队决定创造loc和iloc运算符分别处理严格基于标签和整数的索引。
ix运算符仍然可用,但并不推荐。
| 索引方式 | 说明 |
| df[val] | 选取DataFrame的单个列或一组列 |
| df.ix[val] | 选取Dataframe的单个行或一组行 |
| df.ix[:,val] | 选取单个列或列子集 |
| df.ix[val1,val2] | 将一个或多个轴匹配到新索引 |
| reindex方法 | 将一个或多个轴匹配到新索引 |
| xs方法 | 根据标签选取单行或者单列,返回一个Series |
| icol、irow方法 | 根据整数位置选取单列或单行,并返回一个Series |
| get_value、set_value | 根据行标签和列标签选取单个值 |
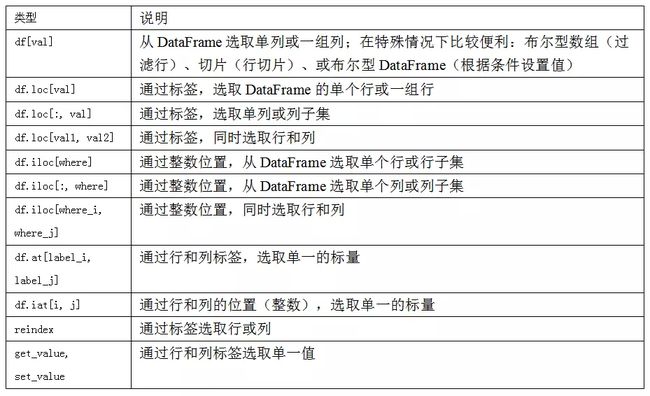
Dataframe常用索引方式
运算:默认情况下,Dataframe和Series之间的算术运算会将Series的索引匹配到的Dataframe的列,沿着列一直向下传播。若索引找不到,则会重新索引产生并集。
pandas的索引对象负责管理轴标签和其他元数据(比如轴名称等)。构建Series或DataFrame时,所用到的任何数组或其他序列的标签都会被转换成一个Index
D.Index
pandas的索引对象负责管理轴标签和其他元数据(比如轴名称等)。构建Series或DataFrame时,所用到的任何数组或其他序列的标签都会被转换成一个Index。Index对象不可修改,从而在多个数据结构之间安全共享。
| 主要的Index对象 | 说明 |
| Index | 最广泛的Index对象,将轴标签表示为一个由Python对象组成的NumPy数组 |
| Int64Index | 针对整数的特殊Index |
| MultiIndex | “层次化”索引对象,表示单个轴上的多层索引。可以看做由元组组成的数组 |
| DatetimeIndex | 存储纳秒级时间戳(用NumPy的Datetime64类型表示) |
| PeriodIndex | 针对Period数据(时间间隔)的特殊Index |
主要的Index属性
| 函数 | 说明 |
| Index([x,y,...]) | 创建索引 |
| append(Index) | 连接另一个Index对象,产生一个新的Index |
| diff(Index) | 计算差集,产生一个新的Index |
| intersection(Index) | 计算交集 |
| union(Index) | 计算并集 |
| isin(Index) | 检查是否存在与参数索引中,返回bool型数组 |
| delete(i) | 删除索引i处元素,得到新的Index |
| drop(str) | 删除传入的值,得到新Index |
| insert(i,str) | 将元素插入到索引i处,得到新Index |
| is_monotonic() | 当各元素大于前一个元素时,返回true |
| is_unique() | 当Index没有重复值时,返回true |
| unique() | 计算Index中唯一值的数组 |
用loc和iloc进行选取
对于DataFrame的行的标签索引,引入了特殊的标签运算符loc和iloc。它们可以让你用类似NumPy的标记,使用轴标签(loc)或整数索引(iloc),从DataFrame选择行和列的子集。
通过标签选择一行和多列:
In [137]: data.loc['Colorado', ['two', 'three']]
Out[137]:
two 5
three 6
Name: Colorado, dtype: int64
然后用iloc和整数进行选取:
In [138]: data.iloc[2, [3, 0, 1]]
Out[138]:
four 11
one 8
two 9
Name: Utah, dtype: int64
In [139]: data.iloc[2]
Out[139]:
one 8
two 9
three 10
four 11
Name: Utah, dtype: int64
In [140]: data.iloc[[1, 2], [3, 0, 1]]
Out[140]:
four one two
Colorado 7 0 5
Utah 11 8 9DataFrame和Series之间的运算
跟不同维度的NumPy数组一样,DataFrame和Series之间算术运算也是有明确规定的。先来看一个具有启发性的例子,计算一个二维数组与其某行之间的差:
In [175]: arr = np.arange(12.).reshape((3, 4))
In [176]: arr
Out[176]:
array([[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.]])
In [177]: arr[0]
Out[177]: array([ 0., 1., 2., 3.])
In [178]: arr - arr[0]
Out[178]:
array([[ 0., 0., 0., 0.],
[ 4., 4., 4., 4.],
[ 8., 8., 8., 8.]])
当我们从arr减去arr[0],每一行都会执行这个操作。这就叫做广播(broadcasting)。
In [179]: frame = pd.DataFrame(np.arange(12.).reshape((4, 3)),
.....: columns=list('bde'),
.....: index=['Utah', 'Ohio', 'Texas', 'Oregon'])
In [180]: series = frame.iloc[0]
In [181]: frame
Out[181]:
b d e
Utah 0.0 1.0 2.0
Ohio 3.0 4.0 5.0
Texas 6.0 7.0 8.0
Oregon 9.0 10.0 11.0
In [182]: series
Out[182]:
b 0.0
d 1.0
e 2.0
Name: Utah, dtype: float64
默认情况下,DataFrame和Series之间的算术运算会将Series的索引匹配到DataFrame的列,然后沿着行一直向下广播:
In [183]: frame - series
Out[183]:
b d e
Utah 0.0 0.0 0.0
Ohio 3.0 3.0 3.0
Texas 6.0 6.0 6.0
Oregon 9.0 9.0 9.0
如果某个索引值在DataFrame的列或Series的索引中找不到,则参与运算的两个对象就会被重新索引以形成并集:
In [184]: series2 = pd.Series(range(3), index=['b', 'e', 'f'])
In [185]: frame + series2
Out[185]:
b d e f
Utah 0.0 NaN 3.0 NaN
Ohio 3.0 NaN 6.0 NaN
Texas 6.0 NaN 9.0 NaN
Oregon 9.0 NaN 12.0 NaN
如果你希望匹配行且在列上广播,则必须使用算术运算方法。例如:
In [186]: series3 = frame['d']
In [187]: frame
Out[187]:
b d e
Utah 0.0 1.0 2.0
Ohio 3.0 4.0 5.0
Texas 6.0 7.0 8.0
Oregon 9.0 10.0 11.0
In [188]: series3
Out[188]:
Utah 1.0
Ohio 4.0
Texas 7.0
Oregon 10.0
Name: d, dtype: float64
In [189]: frame.sub(series3, axis='index')
Out[189]:
b d e
Utah -1.0 0.0 1.0
Ohio -1.0 0.0 1.0
Texas -1.0 0.0 1.0
Oregon -1.0 0.0 1.0
传入的轴号就是希望匹配的轴。在本例中,我们的目的是匹配DataFrame的行索引(axis='index' or axis=0)并进行广播。
函数应用和映射
NumPy的ufuncs(元素级数组方法)也可用于操作pandas对象:
In [190]: frame = pd.DataFrame(np.random.randn(4, 3), columns=list('bde'),
.....: index=['Utah', 'Ohio', 'Texas', 'Oregon'])
In [191]: frame
Out[191]:
b d e
Utah -0.204708 0.478943 -0.519439
Ohio -0.555730 1.965781 1.393406
Texas 0.092908 0.281746 0.769023
Oregon 1.246435 1.007189 -1.296221
In [192]: np.abs(frame)
Out[192]:
b d e
Utah 0.204708 0.478943 0.519439
Ohio 0.555730 1.965781 1.393406
Texas 0.092908 0.281746 0.769023
Oregon 1.246435 1.007189 1.296221
另一个常见的操作是,将函数应用到由各列或行所形成的一维数组上。DataFrame的apply方法即可实现此功能:
In [193]: f = lambda x: x.max() - x.min()
In [194]: frame.apply(f)
Out[194]:
b 1.802165
d 1.684034
e 2.689627
dtype: float64
这里的函数f,计算了一个Series的最大值和最小值的差,在frame的每列都执行了一次。结果是一个Series,使用frame的列作为索引。
如果传递axis='columns'到apply,这个函数会在每行执行:
In [195]: frame.apply(f, axis='columns')
Out[195]:
Utah 0.998382
Ohio 2.521511
Texas 0.676115
Oregon 2.542656
dtype: float64
许多最为常见的数组统计功能都被实现成DataFrame的方法(如sum和mean),因此无需使用apply方法。
传递到apply的函数不是必须返回一个标量,还可以返回由多个值组成的Series:
In [196]: def f(x):
.....: return pd.Series([x.min(), x.max()], index=['min', 'max'])
In [197]: frame.apply(f)
Out[197]:
b d e
min -0.555730 0.281746 -1.296221
max 1.246435 1.965781 1.393406
元素级的Python函数也是可以用的。假如你想得到frame中各个浮点值的格式化字符串,使用applymap即可:
In [198]: format = lambda x: '%.2f' % x
In [199]: frame.applymap(format)
Out[199]:
b d e
Utah -0.20 0.48 -0.52
Ohio -0.56 1.97 1.39
Texas 0.09 0.28 0.77
Oregon 1.25 1.01 -1.30
之所以叫做applymap,是因为Series有一个用于应用元素级函数的map方法:
In [200]: frame['e'].map(format)
Out[200]:
Utah -0.52
Ohio 1.39
Texas 0.77
Oregon -1.30
Name: e, dtype: object相关系数与协方差
有些汇总统计(如相关系数和协方差)是通过参数对计算出来的。我们来看几个DataFrame,它们的数据来自Yahoo!Finance的股票价格和成交量,使用的是pandas-datareader包(可以用conda或pip安装):
conda install pandas-datareader
使用pandas_datareader模块下载了一些股票数据:
import pandas_datareader.data as web
all_data = {ticker: web.get_data_yahoo(ticker)
for ticker in ['AAPL', 'IBM', 'MSFT', 'GOOG']}
price = pd.DataFrame({ticker: data['Adj Close']
for ticker, data in all_data.items()})
volume = pd.DataFrame({ticker: data['Volume']
for ticker, data in all_data.items()})
注意:此时Yahoo! Finance已经不存在了,因为2017年Yahoo!被Verizon收购了。参阅pandas-datareader文档,可以学习最新的功能。
现在计算价格的百分数变化:
In [242]: returns = price.pct_change()
In [243]: returns.tail()
Out[243]:
AAPL GOOG IBM MSFT
Date
2016-10-17 -0.000680 0.001837 0.002072 -0.003483
2016-10-18 -0.000681 0.019616 -0.026168 0.007690
2016-10-19 -0.002979 0.007846 0.003583 -0.002255
2016-10-20 -0.000512 -0.005652 0.001719 -0.004867
2016-10-21 -0.003930 0.003011 -0.012474 0.042096
Series的corr方法用于计算两个Series中重叠的、非NA的、按索引对齐的值的相关系数。与此类似,cov用于计算协方差:
In [244]: returns['MSFT'].corr(returns['IBM'])
Out[244]: 0.49976361144151144
In [245]: returns['MSFT'].cov(returns['IBM'])
Out[245]: 8.8706554797035462e-05
因为MSTF是一个合理的Python属性,我们还可以用更简洁的语法选择列:
In [246]: returns.MSFT.corr(returns.IBM)
Out[246]: 0.49976361144151144
另一方面,DataFrame的corr和cov方法将以DataFrame的形式分别返回完整的相关系数或协方差矩阵:
In [247]: returns.corr()
Out[247]:
AAPL GOOG IBM MSFT
AAPL 1.000000 0.407919 0.386817 0.389695
GOOG 0.407919 1.000000 0.405099 0.465919
IBM 0.386817 0.405099 1.000000 0.499764
MSFT 0.389695 0.465919 0.499764 1.000000
In [248]: returns.cov()
Out[248]:
AAPL GOOG IBM MSFT
AAPL 0.000277 0.000107 0.000078 0.000095
GOOG 0.000107 0.000251 0.000078 0.000108
IBM 0.000078 0.000078 0.000146 0.000089
MSFT 0.000095 0.000108 0.000089 0.000215
利用DataFrame的corrwith方法,你可以计算其列或行跟另一个Series或DataFrame之间的相关系数。传入一个Series将会返回一个相关系数值Series(针对各列进行计算):
In [249]: returns.corrwith(returns.IBM)
Out[249]:
AAPL 0.386817
GOOG 0.405099
IBM 1.000000
MSFT 0.499764
dtype: float64
传入一个DataFrame则会计算按列名配对的相关系数。这里,我计算百分比变化与成交量的相关系数:
In [250]: returns.corrwith(volume)
Out[250]:
AAPL -0.075565
GOOG -0.007067
IBM -0.204849
MSFT -0.092950
dtype: float64
传入axis='columns'即可按行进行计算。无论如何,在计算相关系数之前,所有的数据项都会按标签对齐。
唯一值、值计数以及成员资格
还有一类方法可以从一维Series的值中抽取信息。看下面的例子:
In [251]: obj = pd.Series(['c', 'a', 'd', 'a', 'a', 'b', 'b', 'c', 'c'])
第一个函数是unique,它可以得到Series中的唯一值数组:
In [252]: uniques = obj.unique()
In [253]: uniques
Out[253]: array(['c', 'a', 'd', 'b'], dtype=object)
返回的唯一值是未排序的,如果需要的话,可以对结果再次进行排序(uniques.sort())。相似的,value_counts用于计算一个Series中各值出现的频率:
In [254]: obj.value_counts()
Out[254]:
c 3
a 3
b 2
d 1
dtype: int64
为了便于查看,结果Series是按值频率降序排列的。value_counts还是一个顶级pandas方法,可用于任何数组或序列:
In [255]: pd.value_counts(obj.values, sort=False)
Out[255]:
a 3
b 2
c 3
d 1
dtype: int64
isin用于判断矢量化集合的成员资格,可用于过滤Series中或DataFrame列中数据的子集:
In [256]: obj
Out[256]:
0 c
1 a
2 d
3 a
4 a
5 b
6 b
7 c
8 c
dtype: object
In [257]: mask = obj.isin(['b', 'c'])
In [258]: mask
Out[258]:
0 True
1 False
2 False
3 False
4 False
5 True
6 True
7 True
8 True
dtype: bool
In [259]: obj[mask]
Out[259]:
0 c
5 b
6 b
7 c
8 c
dtype: object
与isin类似的是Index.get_indexer方法,它可以给你一个索引数组,从可能包含重复值的数组到另一个不同值的数组:
In [260]: to_match = pd.Series(['c', 'a', 'b', 'b', 'c', 'a'])
In [261]: unique_vals = pd.Series(['c', 'b', 'a'])
In [262]: pd.Index(unique_vals).get_indexer(to_match)
Out[262]: array([0, 2, 1, 1, 0, 2])
表5-9给出了这几个方法的一些参考信息。

表5-9 唯一值、值计数、成员资格方法
有时,你可能希望得到DataFrame中多个相关列的一张柱状图。例如:
In [263]: data = pd.DataFrame({'Qu1': [1, 3, 4, 3, 4],
.....: 'Qu2': [2, 3, 1, 2, 3],
.....: 'Qu3': [1, 5, 2, 4, 4]})
In [264]: data
Out[264]:
Qu1 Qu2 Qu3
0 1 2 1
1 3 3 5
2 4 1 2
3 3 2 4
4 4 3 4
将pandas.value_counts传给该DataFrame的apply函数,就会出现:
In [265]: result = data.apply(pd.value_counts).fillna(0)
In [266]: result
Out[266]:
Qu1 Qu2 Qu3
1 1.0 1.0 1.0
2 0.0 2.0 1.0
3 2.0 2.0 0.0
4 2.0 0.0 2.0
5 0.0 0.0 1.0
这里,结果中的行标签是所有列的唯一值。后面的频率值是每个列中这些值的相应计数。