主题模型lda源码阅读
最近一段时间学习了主题模型,主要是plsa和lda,本来打算也写一下plsa的,不过发现网上有一篇非常好的博文就直接转载了(还是懒。。),然后就只写下lda吧。。
lda的开源代码比较出名的一个是python的ariddell/lda,另一个是GibbsLDA++,这两个都大致浏览了一下。下面主要说下python版的。
首先看下初始化部分的代码
def _initialize(self, X):
D, W = X.shape
N = int(X.sum())
n_topics = self.n_topics
n_iter = self.n_iter
logger.info("n_documents: {}".format(D))
logger.info("vocab_size: {}".format(W))
logger.info("n_words: {}".format(N))
logger.info("n_topics: {}".format(n_topics))
logger.info("n_iter: {}".format(n_iter))
self.nzw_ = nzw_ = np.zeros((n_topics, W), dtype=np.intc)
self.ndz_ = ndz_ = np.zeros((D, n_topics), dtype=np.intc)
self.nz_ = nz_ = np.zeros(n_topics, dtype=np.intc)
self.WS, self.DS = WS, DS = lda.utils.matrix_to_lists(X)
self.ZS = ZS = np.empty_like(self.WS, dtype=np.intc)
np.testing.assert_equal(N, len(WS))
for i in range(N):
w, d = WS[i], DS[i]
z_new = i % n_topics
ZS[i] = z_new
ndz_[d, z_new] += 1
nzw_[z_new, w] += 1
nz_[z_new] += 1
self.loglikelihoods_ = []解释下这句话WS, DS = lda.utils.matrix_to_lists(X),WS为长度为N的array,WS[i]表示语料库中第i个词对应的id,DS也是长度为N的array,DS[i]表示语料库中第i个词对应的doc的id,接下来的ZS也是长度为N的array,ZS[i]表示第i个词的topic id。nz是一个长度为K的array,nz[i]代表第i个主题下出现词的个数。
初始化的工作就是随机指定语料库中每个词的主题并计算出上述的几个矩阵和数组。
def _sample_topics(int[:] WS, int[:] DS, int[:] ZS, int[:, :] nzw, int[:, :] ndz, int[:] nz,
double[:] alpha, double[:] eta, double[:] rands):
cdef int i, k, w, d, z, z_new
cdef double r, dist_cum
cdef int N = WS.shape[0]
cdef int n_rand = rands.shape[0]
cdef int n_topics = nz.shape[0]
cdef double eta_sum = 0
cdef double* dist_sum = malloc(n_topics * sizeof(double))
if dist_sum is NULL:
raise MemoryError("Could not allocate memory during sampling.")
with nogil:
for i in range(eta.shape[0]):
eta_sum += eta[i]
for i in range(N):
w = WS[i]
d = DS[i]
z = ZS[i]
dec(nzw[z, w])
dec(ndz[d, z])
dec(nz[z])
dist_cum = 0
for k in range(n_topics):
# eta is a double so cdivision yields a double
dist_cum += (nzw[k, w] + eta[w]) / (nz[k] + eta_sum) * (ndz[d, k] + alpha[k])
dist_sum[k] = dist_cum
r = rands[i % n_rand] * dist_cum # dist_cum == dist_sum[-1]
z_new = searchsorted(dist_sum, n_topics, r)
ZS[i] = z_new
inc(nzw[z_new, w])
inc(ndz[d, z_new])
inc(nz[z_new])
free(dist_sum) 然后就到了gibbs采样部分代码了,采样所做的工作就是对于当前第i号词,固定其他词对应的主题,求p(zi=k | *)的概率,由采样公式
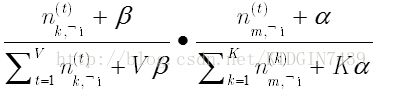
可以知道,对于每个词做如下操作,首先在nzw,ndz,nz矩阵中去除当前词的影响,即代码中自减操作,然后遍历K个topic,根据上述公式计算p(zi=k | *),其中dist_sum[i]表示前i个主题的概率,采样新主题的时候先rand一个随机数r,然后通过searchsorted函数在dist_sum数组中二分查找第一个概率大于该随机数r对应的主题作为该词的新主题。最后更新nzw,ndz,nz矩阵。
注意上图公式中右下角的式子不管当前词属于哪个词,这个式子都是一个定值,所以一般代码实现只计算其他三个式子即可。
事实上,上图对每个词进行采样的公式的物理意义就是p(w|z)*p(z|d),可以直观的表示为路径选择的过程
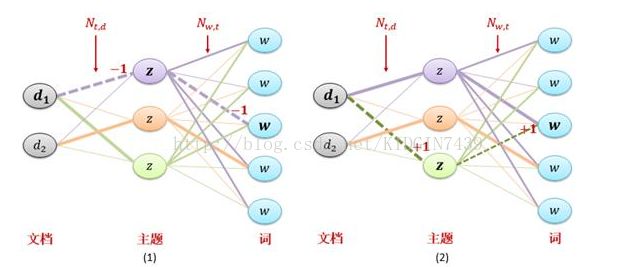
首先,对当前文档d中词w,如图1中粗体表示,词w的旧主题给出了d-z-w的一条路径,如图1虚线表示。
然后去除词w对应旧主题z,更新ndz和nzw矩阵计数(在旧路径中对应的两条边上做减一操作),对应图中的N(t, d)和N(w, t)。
然后极端d-z-w的每一条可能路径的概率,d-z-w路径的概率就等于d-z和z-w两部分路径概率的乘积即P(z|d)P(w|z)。
然后一句概率对d-z-w路径重新采样,得到词w的新主题,入图2虚线。
最后依据新主题更新ndz和nzw矩阵计数(在新路径中对应的两条边上做加一操作)。
在经过多次采样收敛之后,就可根据期望公式计算Θ矩阵和φ矩阵了,如下图


代码实现如下
self.components_ = (self.nzw_ + self.eta).astype(float)
self.components_ /= np.sum(self.components_, axis=1)[:, np.newaxis]
self.topic_word_ = self.components_
self.doc_topic_ = (self.ndz_ + self.alpha).astype(float)
self.doc_topic_ /= np.sum(self.doc_topic_, axis=1)[:, np.newaxis]对于预测新的文档的topic分布步骤如下

ariddell/lda的预测部分没有太看明白,所以这里截取了gibbslda++中的inference过程来看
int model::inf_sampling(int m, int n) {
// remove z_i from the count variables
int topic = newz[m][n];
int w = pnewdata->docs[m]->words[n];
int _w = pnewdata->_docs[m]->words[n];
newnw[_w][topic] -= 1;
newnd[m][topic] -= 1;
newnwsum[topic] -= 1;
newndsum[m] -= 1;
double Vbeta = V * beta;
double Kalpha = K * alpha;
// do multinomial sampling via cumulative method
for (int k = 0; k < K; k++) {
p[k] = (nw[w][k] + newnw[_w][k] + beta) / (nwsum[k] + newnwsum[k] + Vbeta) *
(newnd[m][k] + alpha) / (newndsum[m] + Kalpha);
}
// cumulate multinomial parameters
for (int k = 1; k < K; k++) {
p[k] += p[k - 1];
}
// scaled sample because of unnormalized p[]
double u = ((double)random() / RAND_MAX) * p[K - 1];
for (topic = 0; topic < K; topic++) {
if (p[topic] > u) {
break;
}
}
// add newly estimated z_i to count variables
newnw[_w][topic] += 1;
newnd[m][topic] += 1;
newnwsum[topic] += 1;
newndsum[m] += 1;
return topic;
}由代码可以看出,其实和训练过程基本一致,唯一的不同就是在采样计算p[k]的时候将训练过程中得到的词分布矩阵加入到了先验分布之中,更新过程只更新新文档的词分布newnw和newnd。
参考:
LDA漫游指南
火光摇曳