大数据解决方案:实时日志处理系统架构及整体思路
1.实时日志处理系统架构及整体思路
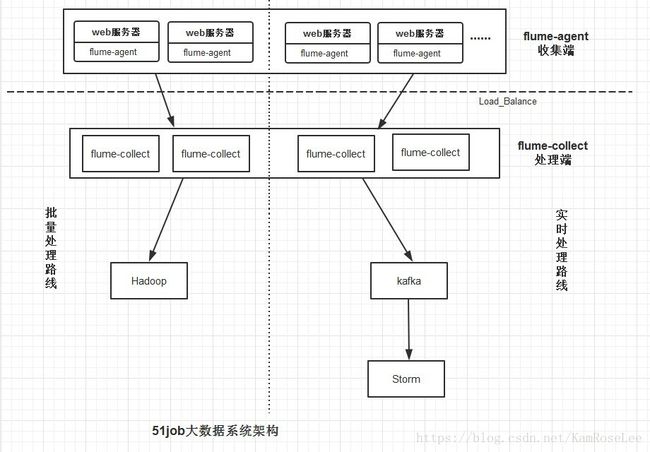
整个系统分为三层:收集(Agent)层,汇总(Collector)层和处理层。
其中Agent层采用flume收集日志,每个机器部署一个进程,负责对单机的日志收集工作;
Collector层flume部署在后端服务器上,负责接收Agent层发送的日志,汇总并决定最终流向;
对于单个日志文件的服务器,flume采用传统的source-channel-sink配置,而对于有多个日志的服务器,flume采用开启多个源的方式来进行监控,流程为sources-channel-sink。
处理层主要负责接受Collector传来的日志,经由kafka,给Storm系统提供实时日志流。
Agent到Collector使用LoadBalance策略,将所有的日志均衡地发到所有的Collector上,达到负载均衡的目标,同时并处理单个Collector失效的问题。
架构设计考虑:
- 可用性
1.1 Agent死掉
Agent死掉分为两种情况:机器死机或者Agent进程死掉。
对于机器死机的情况来说,由于产生日志的进程也同样会死掉,所以不会再产生新的日志,不存在不提供服务的情况。
对于Agent进程死掉的情况来说,由于采用了filechannel的方式,虽然降低了传输速率,但是在进程死掉重启后,可以通过检查点来接着读取。
1.2 Collector死掉
由于中心服务器提供的是对等的且无差别的服务,且Agent访问Collector做了LoadBalance机制。所以当某个Collector无法提供服务时,Agent的重试策略会将数据发送到其它可用的Collector上面。所以整个服务不受影响。
- 可靠性
对Flume来说,所有的events都被保存在Agent的Channel中,然后被发送到数据流中的下一个Agent或者最终的存储服务中。当且仅当它们被保存到下一个Agent的Channel中或者被保存到最终的存储服务中。这就是Flume提供数据流中点到点的可靠性保证的最基本的单跳消息传递语义。
那么Flume是如何做到上述最基本的消息传递语义呢?
首先,Agent间的事务交换。Flume使用事务的办法来保证event的可靠传递。Source和Sink分别被封装在事务中,这些事务由保存event的存储提供或者由Channel提供。这就保证了event在数据流的点对点传输中是可靠的。在多级数据流中,如下图,上一级的Sink和下一级的Source都被包含在事务中,保证数据可靠地从一个Channel到另一个Channel转移。
其次,我们采用FileChannel是持久性的,提供类似mysql的日志机制,保证数据不丢失。
- 可扩展性
3.1 Agent层
对于Agent这一层来说,每个机器部署一个Agent,可以水平扩展,不受限制。一个方面,Agent收集日志的能力受限于机器的性能,正常情况下一个Agent可以为单机提供足够服务。另一方面,如果机器比较多,可能受限于后端Collector提供的服务,但Agent到Collector是有Load Balance机制,使得Collector可以线性扩展提高能力。
3.2 Collector层
对于Collector这一层,Agent到Collector是有Load Balance机制,并且Collector提供无差别服务,所以可以线性扩展。
具体模块分解图:

agent的source端采用exec执行linux中的tail命令的方式来监控日志数据,对于这种方式flume默认不会开启失败重试因此会造成数据丢失情况严重,而开启后数据几乎不会丢失。
agent的sink端采用thrift,flume提供了avro和thrift两种方式进行传输,经过测试avro在load banlance机制中可能会发生数据重复发送的问题,因此我们采用thrift的方式进行传输。
我们的channel统一采用file channel的方式,flume提供了memory channel和file channel的方式,采用file channel的方式牺牲了一定的传输性能,但是保证了数据的完整性。
2.Flume部署手册
1.安装前准备
解压flume-agent.tar/flume-collect.tar至安装目录下
相关命令:tar zvxf flume-agent.tar –C /usr/local/hadoop(安装目录,可自定义)
2.配置jdk环境变量
Vi /etc/profile
修改相应的JAVA_HOME和PATH
3.Flume的agent端(日志收集端)部署步骤
修改conf/tailSource_avro.conf文件相关配置选项:
- 修改agent.sources.r1.command为要监控的日志文件,默认为/var/www/logs/access_log
(2)修改agent.channels.c1.checkpointDir为保存检查点的文件夹地址,默认/hadoop/flume/checkpointdir
(3)修改agent.channels.c1.dataDirs为保存缓存文件的文件夹地址,默认为/hadoop/flume/datadirs
(4)修改agent.sources.r1.interceptors.i1.value为频道名加分隔符(!`@`!),例如:searchweb!`@`!
flume的agent分为单个源文件和多个源文件
整体参考配置见附录。
4.Flume的collect端(处理端)部署步骤
修改conf/avro_hdfs.conf文件:
(1)修改agent.channels.c1.checkpointDir为保存检查点的文件夹地址,默认/hadoop/flume/checkpointdir
(2)修改agent.channels.c1.dataDirs为保存缓存文件的文件夹地址,默认为/hadoop/flume/datadirs
(3)修改agent.sinks.s1.hdfs.rollInterval为想要往HDFS保存的间隔,默认20分钟(1200)
5.修改bin/flume-start.sh
把所有的/hadoop/flume改为flume安装路径

6.Flume启动
启动顺序:先启动collector端,再启动agent端
启动命令:执行bin/flume-start.sh
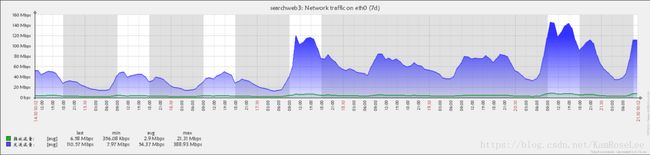
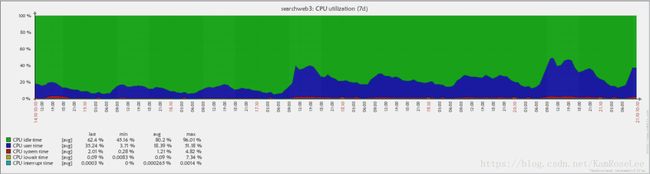
7.Flume agent端压力测试结果
2014-10-17上午9点将searchweb3机器的权重调为原来的3倍,并部署flume收集日志,最近7天(2014-10-14---2014-10-21)结果如下:
网卡流量:
CPU Load:

CPU利用率:
内存使用情况:

7.Flume 数据完整性测试结果
抽取了其中半天的日志(00:00:00—11:59:59)做对比
原始日志条数:1208097
Flume收集条数:1208102
相差5条
3.Kafka部署手册
1.解压安装包
tar zxvf kafka_2.9.2-0.8.1.1.tgz –C /hadoop
mv kafka_2.9.2-0.8.1.1/ kafka
2.编译kafka
cd /hadoop/kafka
sbt update
sbt package
sbt assembly-package-dependency
sbt sbt-dependency
3.修改server.properties使用自己的zookeeper
具体配置参加附录
4.拷贝kafka到各主机
scp –r kafka/ hadoop19:/hadoop/
scp –r kafka/ hadoop20:/hadoop/
scp –r kafka/ hadoop21:/hadoop/
修改相应的server.properties配置
Broker.id=2
advertised.host.name=hadoop20
5.启动kafka
kafka-server-start.sh $KAFKA_HOME/config/server.properties > /dev/null 2>&1 &
4.flume-Kafka整合
1.拷贝flumeng-kafka-plugin-master/flumeng-kafka-plugin中的lib和package文件夹中的jar包到flume/lib中
这些jar包是:
kafka-2.9.2-0.8.0-beta1
metrics-annotation-2.2.0
metrics-core-2.2.0
scala-compiler-2.9.2
scala-library-2.9.2
zkclient-0.1
flumeng-kafka-plugin.jar
2.配置文件参考flume-collector端配置文件
5.storm部署
1.安装zeromq
yum install gcc-c++ libuuid-devel
tar zvxf zeromq-3.2.4.tar.gz –C /hadoop
mv zeromq-3.2.4 zeromq
cd zeromq
./autogen.sh
./configure
make && make install
2.安装jzmq
yum install git libtool
unzip jzmq-master.zip –d /hadoop
mv jzmq-master jzmq
cd jzmq
./autogen.sh
./configure
make && make install
- 安装storm
(1)解压
tar zxvf apache-storm-0.9.2-incubating.tar.gz –C /hadoop
mv storm-0.9.2-incubating storm
- 修改conf/storm.yaml配置文件
4.修改/etc/profile
增加STORM_HOME=/hadoop/storm
在PATH中增加$STORM_HOME/bin
5.拷贝到其他机器
scp –r storm hadoop19:/hadoop
scp –r storm hadoop20:/hadoop
scp –r storm hadoop21:/hadoop
6.启动storm
启动zk:zkServer.sh start
启动nimbus:storm nimbus >/dev/null 2>&1 &
启动supervisor:storm supervisor >/dev/null 2>&1 &
启动ui :storm ui >/dev/null 2>&1 &
6.storm和kafka整合
1.拷贝jar包到storm/lib下
这些jar为:
storm-kafka-0.9.2-incubating.jar
kafka_2.9.2-0.8.1.1.jar
metrics-core-2.2.0.jar
scala-library-2.9.2.jar
2.重启storm
7.曾经遇到的问题
1.类冲突
问题描述:采用自定义source在1.5版本时会出现类冲突错误
问题原因:自定义的jar与官方jar包的类有冲突
解决思路:换一种source
目前方案:放弃使用自定义方案,采用官方exec模式
2.采用exec模式会出现丢数据现象
问题描述:采用官方exec模式做为source端有时会出现严重的丢数据现象
问题原因:exec source在执行Tail的时候,put数据到channel,当一直未获取到channel lock超时后,exec source会退出,而默认行为是不自动恢复重试
解决思路:开启flume提供快速恢复的机制
目前方案:在配置文件中加上这三个参数:restartThrottle,restart,logStdErr解决
3.flume重复收集日志
问题:采用自定义tail配合avro方式传递日志后曾发现flume会多收集日志,误差率2%左右。
问题原因:
flume-agent与flume-collector会出现短暂的断开连接,此时这条日志会发送失败,而后flume-agent会向剩余的机器都发送这条数据。
解决思路:在FileChannel中添加相关的事务配置
目前方案:
采用exec模式配合thrift同时在FileChannel中增加事务配置解决,收集结果如下:
原始日志条数:1208097
Flume收集条数:1208102
相差5条
附录
Flume-agent端收集单个日志参考配置如下:
agent.sources = r1
agent.sinks=s1 s2 s3
agent.channels=c1
#Configure source
agent.sources.r1.type=exec
agent.sources.r1.command=tail -F /var/www/logs/access_log
agent.sources.r1.restart=true
agent.sources.r1.logStdErr=true
agent.sources.r1.restartThrottle=5000
agent.sources.r1.channels = c1
agent.sources.r1.interceptors=i1
agent.sources.r1.interceptors.i1.type=org.apache.flume.interceptor.ValueBodyInterceptor$Builder
agent.sources.r1.interceptors.i1.value=searchweb!`@`!
#Configure sink
agent.sinkgroups=g1
agent.sinkgroups.g1.sinks=s1 s2 s3
agent.sinkgroups.g1.processor.type=load_balance
agent.sinkgroups.g1.processor.backoff=true
agent.sinkgroups.g1.processor.selector=round_robin
agent.sinks.s1.type=thrift
agent.sinks.s1.hostname=192.168.4.181
agent.sinks.s1.port=44444
agent.sinks.s1.channel=c1
agent.sinks.s2.type=thrift
agent.sinks.s2.hostname=192.168.4.180
agent.sinks.s2.port=44444
agent.sinks.s2.channel=c1
agent.sinks.s3.type=thrift
agent.sinks.s3.hostname=192.168.4.179
agent.sinks.s3.port=44444
agent.sinks.s3.channel=c1
#Configure c1
agent.channels.c1.type=file
agent.channels.c1.checkpointDir=/usr/local/hadoop/flume/checkpointdir
agent.channels.c1.dataDirs=/usr/local/hadoop/flume/datadirs
agent.channels.c1.transactionCapacity=10000
agent.channels.c1.checkpointInterval=30000
Flume-agent端收集多个日志参考配置如下:
agent.sources = r1 r2
agent.sinks=s1 s2 s3
agent.channels=c1
#Configure source
agent.sources.r1.type=exec
agent.sources.r1.command=tail -F /var/www/logs/access_5linux_log
agent.sources.r1.restart=true
agent.sources.r1.logStdErr=true
agent.sources.r1.restartThrottle=5000
agent.sources.r1.channels = c1
agent.sources.r1.interceptors=i1
agent.sources.r1.interceptors.i1.type=org.apache.flume.interceptor.ValueBodyInterceptor$Builder
agent.sources.r1.interceptors.i1.value=5linux!`@`!
agent.sources.r2.type=exec
agent.sources.r2.command=tail -F /var/www/logs/access_3g_log
agent.sources.r2.restart=true
agent.sources.r2.logStdErr=true
agent.sources.r2.restartThrottle=5000
agent.sources.r2.channels = c1
agent.sources.r2.interceptors=i2
agent.sources.r2.interceptors.i2.type=org.apache.flume.interceptor.ValueBodyInterceptor$Builder
agent.sources.r2.interceptors.i2.value=3g!`@`!
#Configure sink
agent.sinkgroups=g1
agent.sinkgroups.g1.sinks=s1 s2 s3
agent.sinkgroups.g1.processor.type=load_balance
agent.sinkgroups.g1.processor.backoff=true
agent.sinkgroups.g1.processor.selector=round_robin
agent.sinks.s1.type=thrift
agent.sinks.s1.hostname=192.168.4.181
agent.sinks.s1.port=44444
agent.sinks.s1.channel=c1
agent.sinks.s2.type=thrift
agent.sinks.s2.hostname=192.168.4.180
agent.sinks.s2.port=44444
agent.sinks.s2.channel=c1
agent.sinks.s3.type=thrift
agent.sinks.s3.hostname=192.168.4.179
agent.sinks.s3.port=44444
agent.sinks.s3.channel=c1
#Configure c1
agent.channels.c1.type=file
agent.channels.c1.checkpointDir=/usr/local/hadoop/flume/checkpointdir
agent.channels.c1.dataDirs=/usr/local/hadoop/flume/datadirs
agent.channels.c1.transactionCapacity=10000
agent.channels.c1.checkpointInterval=30000
Flume-collect参考配置如下:
agent.sources = r1
agent.sinks=s1 s2
agent.channels=c1 c2
#Configure source
agent.sources.r1.type = thrift
agent.sources.r1.channels = c1 c2
agent.sources.r1.bind=0.0.0.0
agent.sources.r1.port=44444
agent.sources.r1.selector.type = replicating
#Configure s1
agent.sinks.s1.type=hdfs
agent.sinks.s1.hdfs.path=hdfs://ns1/flume/tmp2/%m%d%H
agent.sinks.s1.hdfs.fileType=DataStream
agent.sinks.s1.hdfs.useLocalTimeStamp=true
agent.sinks.s1.hdfs.writeFormat=TEXT
#agent.sinks.s1.hdfs.round=true
agent.sinks.s1.hdfs.rollInterval=1200
agent.sinks.s1.hdfs.rollSize=50000000
agent.sinks.s1.hdfs.rollCount=1000000
agent.sinks.s1.hdfs.batchSize=1000
#agent.sinks.s1.hdfs.roundUnit=minute
#agent.sinks.s1.hdfs.roundValue=1
agent.sinks.s1.channel=c1
#Configure c1
agent.channels.c1.type=file
agent.channels.c1.checkpointDir=/hadoop/flume/checkpointdir
agent.channels.c1.dataDirs=/hadoop/flume/datadirs
agent.channels.c1.transactionCapacity=10000
agent.channels.c1.checkpointInterval=30000
####
agent.channels.c2.type=file
agent.channels.c2.checkpointDir=/hadoop/flume/kafka/check
agent.channels.c2.dataDirs=/hadoop/flume/kafka/data
agent.channels.c2.transactionCapacity=10000
agent.channels.c2.checkpointInterval=30000
agent.sinks.s2.type = org.apache.flume.plugins.KafkaSink
agent.sinks.s2.metadata.broker.list=127.0.0.1:9092
agent.sinks.s2.partition.key=0
agent.sinks.s2.partitioner.class=org.apache.flume.plugins.SinglePartition
agent.sinks.s2.serializer.class=kafka.serializer.StringEncoder
agent.sinks.s2.request.required.acks=0
agent.sinks.s2.max.message.size=1000000
agent.sinks.s2.producer.type=sync
agent.sinks.s2.custom.encoding=UTF-8
agent.sinks.s2.custom.topic.name=kafka
agent.sinks.s2.channel=c2
Kafka参考配置:
broker.id=2
port=9092
advertised.host.name=hadoop20
num.network.threads=2
num.io.threads=8
socket.send.buffer.bytes=1048576
socket.receive.buffer.bytes=1048576
socket.request.max.bytes=104857600
log.dirs=/hadoop/kafka/logs
num.partitions=2
log.retention.hours=168
log.segment.bytes=536870912
Log.retention.check.interval.ms=60000
Log.cleaner.enable=false
zookeeper.connect=hadoop19:2181,hadoop20:2181,hadoop21:2181
zookeeper.connect.timeout.ms=1000000
Storm参考配置:
storm.zookeeper.servers:
- "hadoop21"
- "hadoop20"
- "hadoop19"
nimbus.host: "hadoop22"
storm.local.dir: "/hadoop/storm/data"
ui.port: 8080