HDFS高级
namenode文件租约分析LeaseManager
文件租约就是将操作的文件和操作它的客户端进行绑定,若文件不存在一个租约,则说明该文件当前没有被任何客户端写,否则,就表示它正在被该文件租约中 的客户端holder写。这中间可能会发生一些意想不到的异常情况,比如正在对某个文件进行写操作的客户端突然宕机了,那么与这个文件相关的租约会迟迟得 不到客户端的续租而过期,那么NameNode会释放这些过期的租约,好让其它的客户端能及时的操作该租约对应文件。
Lease内部类:一个用来表示租约的实体类org.apache.hadoop.hdfs.server.namenode.LeaseManager.Lease
因为文件系统客户端需要向Namenode请求写数据(向Namenode结点写数据块),因此一个文件系统客户端必须持有一个Lease实例。该 Lease实例包含文件系统客户端的持有身份(客户端名称)、最后更新Lease时间(用于判断是否超时)、所要写数据的路径(应该与指定的 Datanode上文件系统的Path相关)。对于每一个文件系统客户端,都应该持有一个Lease,Lease管理一个客户端的全部锁(写锁),其中 Lease中包含的最后更新时间需要文件系统客户端周期地检查来实现更新,这样写数据才不会因为超时而放弃一个Lease。当然,如果一个文件系统客户端 发生故障,或者它不需要持有该Lease,也就是不需要执行文件的写操作,那么它会释放掉由它所持有的Lease管理的全部的锁,以便满足其它客户端的请求。
Monitor内部线程类:一个内部线程类 org.apache.hadoop.hdfs.server.namenode.LeaseManager.Monitor
它是用来周期性地(每2s 检查一次),检查LeaseManager管理器所维护的Lease列表中是否有Lease过期的文件系统客户端,如果过期则从Lease列表中删除掉。基本可以清楚LeaseManager的是如何管理Lease,其中LeaseManager还提供了向它维护的列表中添加Lease、删除Lease、更新Lease等等操作。
重要数据结构:
//保存了LeaseHolder到Lease的映射。
private SortedMap leases = new TreeMap();
// Set of: Lease保存了所有lease
private SortedSet sortedLeases = new TreeSet();
//保存了path到Lease的映射。
private SortedMap sortedLeasesByPath = new TreeMap(); (1)租约 Lease
一个租约由一个holder(客户端名),lastUpdate(上次更新时间)和paths(该客户端操作的文件集合)构成。
(2)过期检查
NameNode通过后台工作线程LeaseManager$Monitor来定期检查LeaseManager中的文件租约是否过期,如果过期就释放该文件租约。
class Monitor implements Runnable {
final String name = getClass().getSimpleName();
/** Check leases periodically. */
public void run() {
for(; fsnamesystem.isRunning(); ) {
synchronized(fsnamesystem) {
//检查租约是否过期,过期则internalReleaseLeaseOne和removeLease
checkLeases();
}
try {
Thread.sleep(2000);
} catch(InterruptedException ie) {
if (LOG.isDebugEnabled()) {
LOG.debug(name + " is interrupted", ie);
}
}
}
}
} (3)释放租约
租约有两个超时时间,一个被称为软超时(1分钟),另一个是硬超时(1小时)。如果租 约软超时,那么就会触发internalReleaseLease方法。检查src对应的INodeFile,如果不存在,不处于构造状态,返回;文件处 于构造状态,而文件目标DataNode为空,而且没有数据块,则finalize该文件(该过程在completeFileInternal中已经讨论 过,租约在过程中被释放),并返回;文件处于构造状态,而文件目标DataNode为空,数据块非空,则将最后一个数据块存放的DataNode目标取出 (在BlocksMap中),然后设置为文件现在的目标DataNode;
调用INodeFileUnderConstruction.assignPrimaryDatanode,该过程会挑选一个目前还活着的DataNode, 作为租约的主节点,并把
租约创建到移除的过程
第一步:客户端创建了DFSOutputStream文件流之后,然后把文件路径名和对应的文件流存入LeaseChecker中。
public FSDataOutputStream create(Path f, FsPermission permission,
boolean overwrite,
int bufferSize, short replication, long blockSize,
Progressable progress) throws IOException {
statistics.incrementWriteOps(1);
return new FSDataOutputStream
(dfs.create(getPathName(f), permission,
overwrite, true, replication, blockSize, progress, bufferSize),
statistics);
}
public OutputStream create(String src,
FsPermission permission,
boolean overwrite,
boolean createParent,
short replication,
long blockSize,
Progressable progress,
int buffersize
) throws IOException {
checkOpen();
if (permission == null) {
permission = FsPermission.getDefault();
}
FsPermission masked = permission.applyUMask(FsPermission.getUMask(conf));
LOG.debug(src + ": masked=" + masked);
OutputStream result = new DFSOutputStream(src, masked,
overwrite, createParent, replication, blockSize, progress, buffersize,
conf.getInt("io.bytes.per.checksum", 512));
leasechecker.put(src, result);
return result;
} 关于LeaseChecker:如果是第一次leasechecker.put(src, result),将会启动LeaseChecker这个守护线程)。这个过程是一个同步调用的过程。文件create成功之后,守护线程 LeaseChecker会每30s, 通过rpc调用renew一下 该DFSClient所拥有的lease。
第二步:新增租约
Client与NameNode通信,调用NameNode中的create方 法,NameNode的create方法调用FSNameSystem的startFile方法,startFile调用 startFileInternal方法,startFileInternal检查src对应的INodeFIle是否存在,如果存在检查该 INodeFIle的租约情况,如果有client持有该INodeFile租约不同于操作发起的client,检查租约是否过期 (expiredSoftLimit),如果过期调用internalReleaseLease方法。如果不存在该文件则新增文件并添加租约。 LeaseManager的线程Monitor会循环检测该租约是否过期。创建一个新的文件,状态为under construction,没有任何data block与之对应。
INodeFileUnderConstruction newNode = dir.addFile(src, permissions,replication, blockSize, holder, clientMachine, clientNode, genstamp);
新增租约
leaseManager.addLease(newNode.clientName, src);第三步:完成文件写入,移除租约
DFSClient调用ClientProtocol的远程方法complete,向NameNode节点解除文件src的租约。
释放租约;
//将对应的INodeFileUnderConstruction对象转换为INodeFile对象,并在FSDirectory进行替换;
//调用FSDirectory.closeFile关闭文件,其中会写日志logCloseFile(path, file)。
//检查副本数,如果副本数小于INodeFile中的目标数,那么添加数据块复制任务。
private void finalizeINodeFileUnderConstruction(String src,
INodeFileUnderConstruction pendingFile) throws IOException {
NameNode.stateChangeLog.info("Removing lease on file " + src +
" from client " + pendingFile.clientName);
leaseManager.removeLease(pendingFile.clientName, src);
// The file is no longer pending.
// Create permanent INode, update blockmap
INodeFile newFile = pendingFile.convertToInodeFile();
dir.replaceNode(src, pendingFile, newFile);
// close file and persist block allocations for this file
dir.closeFile(src, newFile);
checkReplicationFactor(newFile);
} DfsClient之文件写入过程解析
HDFS写文件是整个Hadoop中最为复杂的流程之一,它涉及到HDFS中NameNode、DataNode、DFSClient等众多角色的分工与合作。
客户端是如何写文件的:
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
Path file = new Path("demo.txt");
FSDataOutputStream outStream = fs.create(file);
out.write("Welcome to HDFS Java API !!!".getBytes("UTF-8"));
outStream.close(); 只有简单的6行代码,客户端封装的如此简洁,各组件间的RPC调用、异常处理、容错等均对客户端透明。
总体来说, HDFS写文件大体流程如下:
1、客户端获取文件系统实例FileSyStem,并通过其create()方法获取文件系统输出流outputStream;
1.1、首先会联系名字节点NameNode,通过ClientProtocol.create()RPC调用,在名字节点上创建文件元数据,并获取文件状态FileStatus;
1.2、通过文件状态FileStatus构造文件系统输出流outputStream;
2、通过文件系统输出流outputStream写入数据;
2.1、首次写入会首先向名字节点申请数据块,名字节点能够掌握集群DataNode整体状况,分配数据块后,连同DataNode列表信息返回给客户端;
2.2、客户端采用流式管道的方式写入数据节点列表中的第一个DataNode,并由列表中的前一个DataNode将数据转发给后面一个DataNode;
2.3、确认数据包由DataNode经过管道依次返回给上游DataNode和客户端;
2.4、写满一个数据块后,向名字节点提交一个数据;
2.5、再次重复2.1-2.4过程;
3、向名字节点提交文件(complete file),即告知名字节点文件已写完,然后关闭文件系统输出流outputStream等释放资源。可以看出,在不考虑异常等的情况下,上述过程还是比较复杂的。本文,我将着重阐述下HDFS写数据时,客户端是如何实现的.
二、实现分析
我们将带着以下问题来分析客户端写入数据过程:
1、如何获取数据输出流?
2、如何通过数据输出流写入数据?
3、数据输出流关闭时都做了什么?
4、如果发生异常怎么办?即如何容错?
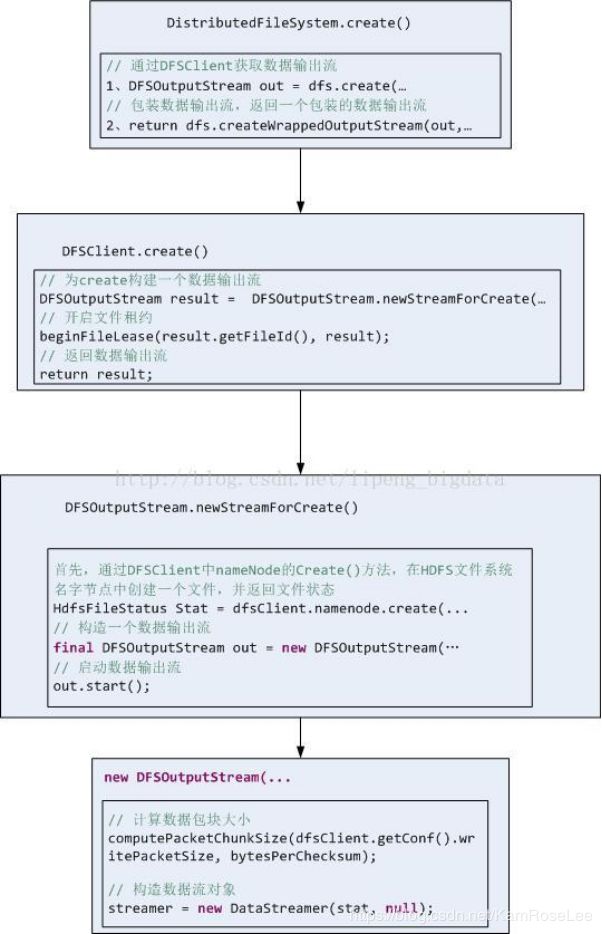
(一)如何获取数据输出流?
HDFS客户端获取数据流是一个复杂的过程,流程图如下:
以DistributedFileSystem为例,create()是其入口方法,DistributedFileSystem内部封装了一个DFS的客户端,如下:
[java] view plain copy
DFSClient dfs;
在DistributedFileSystem的初始化方法initialize()中,会构造这个文件系统客户端,如下:
[java] view plain copy
this.dfs = new DFSClient(uri, conf, statistics);
而create()方法就是通过这个文件系统客户端dfs获取数据输出流的,如下:
[java] view plain copy
@Override
public FSDataOutputStream create(final Path f, final FsPermission permission,
final EnumSet cflags, final int bufferSize,
final short replication, final long blockSize, final Progressable progress,
final ChecksumOpt checksumOpt) throws IOException {
statistics.incrementWriteOps(1);
Path absF = fixRelativePart(f);
return new FileSystemLinkResolver() {
/*
* 创建文件系统数据输出流
*/
@Override
public FSDataOutputStream doCall(final Path p)
throws IOException, UnresolvedLinkException {
// 调用create()方法创建文件,并获取文件系统输出流
final DFSOutputStream dfsos = dfs.create(getPathName(p), permission,
cflags, replication, blockSize, progress, bufferSize,
checksumOpt);
return dfs.createWrappedOutputStream(dfsos, statistics);
}
@Override
public FSDataOutputStream next(final FileSystem fs, final Path p)
throws IOException {
return fs.create(p, permission, cflags, bufferSize,
replication, blockSize, progress, checksumOpt);
}
}.resolve(this, absF);
} FileSystemLinkResolver是一个文件系统链接解析器(抽象类),我们待会再分析它,这里只要知道,该抽象类实例化后会通过resolve()方法--doCall()方法得到数据输出流即可。接着往下DFSClient的create()方法,省略部分代码,如下:
// 为create构建一个数据输出流
final DFSOutputStream result = DFSOutputStream.newStreamForCreate(this,
src, masked, flag, createParent, replication, blockSize, progress,
buffersize, dfsClientConf.createChecksum(checksumOpt),
getFavoredNodesStr(favoredNodes));
// 开启文件租约
beginFileLease(result.getFileId(), result);
return result;
实际上,它又通过DFSOutputStream的newStreamForCreate()方法来获取数据输出流,并开启文件租约。租约的内容我们后续再讲,继续看下如何获取文件输出流的,如下:
/**
* 为创建文件构造一个新的输出流
*/
static DFSOutputStream newStreamForCreate(DFSClient dfsClient, String src,
FsPermission masked, EnumSet flag, boolean createParent,
short replication, long blockSize, Progressable progress, int buffersize,
DataChecksum checksum, String[] favoredNodes) throws IOException {
TraceScope scope =
dfsClient.getPathTraceScope("newStreamForCreate", src);
try {
HdfsFileStatus stat = null;
// Retry the create if we get a RetryStartFileException up to a maximum
// number of times
boolean shouldRetry = true;
int retryCount = CREATE_RETRY_COUNT;
while (shouldRetry) {
shouldRetry = false;
try {
// 首先,通过DFSClient中nameNode的Create()方法,在HDFS文件系统名字节点中创建一个文件,并返回文件状态
stat = dfsClient.namenode.create(src, masked, dfsClient.clientName,
new EnumSetWritable(flag), createParent, replication,
blockSize, SUPPORTED_CRYPTO_VERSIONS);
break;
} catch (RemoteException re) {
IOException e = re.unwrapRemoteException(
AccessControlException.class,
DSQuotaExceededException.class,
FileAlreadyExistsException.class,
FileNotFoundException.class,
ParentNotDirectoryException.class,
NSQuotaExceededException.class,
RetryStartFileException.class,
SafeModeException.class,
UnresolvedPathException.class,
SnapshotAccessControlException.class,
UnknownCryptoProtocolVersionException.class);
if (e instanceof RetryStartFileException) {
if (retryCount > 0) {
shouldRetry = true;
retryCount--;
} else {
throw new IOException("Too many retries because of encryption" +
" zone operations", e);
}
} else {
throw e;
}
}
}
Preconditions.checkNotNull(stat, "HdfsFileStatus should not be null!");
// 构造一个数据输出流
final DFSOutputStream out = new DFSOutputStream(dfsClient, src, stat,
flag, progress, checksum, favoredNodes);
// 启动数据输出流
out.start();
return out;
} finally {
scope.close();
}
} 大体可以分为三步:
1、首先,通过DFSClient中nameNode的Create()方法,在HDFS文件系统名字节点中创建一个文件,并返回文件状态HdfsFileStatus;
2、构造一个数据输出流;
3、启动数据输出流。
上述连接NameNode节点创建文件的过程中,如果发生瞬时错误,会充分利用重试机制,增加系统容错性。DFSClient中nameNode的Create()方法,实际上是调用的是客户端与名字节点间的RPC--ClientProtocol的create()方法,该方法的作用即是在NameNode上创建一个空文件,并返回文件状态。文件状态主要包括以下信息:
// 符号连接
private final byte[] symlink; // symlink target encoded in java UTF8 or null
private final long length;// 文件长度
private final boolean isdir;// 是否为目录
private final short block_replication;// 数据块副本数
private final long blocksize;// 数据块大小
private final long modification_time;// 修改时间
private final long access_time;// 访问时间
private final FsPermission permission;// 权限
private final String owner;// 文件所有者
private final String group;// 文件所属组
private final long fileId;// 文件ID
继续看如何构造一个数据输出流,实际上它是通过构造DFSOutputStream实例获取的,而DFSOutputStream的构造方法如下:
[java] view plain copy
/** Construct a new output stream for creating a file. */
private DFSOutputStream(DFSClient dfsClient, String src, HdfsFileStatus stat,
EnumSet flag, Progressable progress,
DataChecksum checksum, String[] favoredNodes) throws IOException {
this(dfsClient, src, progress, stat, checksum);
this.shouldSyncBlock = flag.contains(CreateFlag.SYNC_BLOCK);
// 计算数据包块大小
computePacketChunkSize(dfsClient.getConf().writePacketSize, bytesPerChecksum);
// 构造数据流对象
streamer = new DataStreamer(stat, null);
if (favoredNodes != null && favoredNodes.length != 0) {
streamer.setFavoredNodes(favoredNodes);
}
} 首先计算数据包块大小,然后构造数据流对象,后续就依靠这个数据流对象来通过管道发送流式数据。接下来便是启动数据输出流,如下:
private synchronized void start() {
streamer.start();
}
很简单,实际上也就是启动数据流对象,通过这个数据流对象实现数据的发送。
中间为什么会有计算数据包块大小这一步呢?原来,数据的发送是通过一个个数据包发送出去的,而不是通过数据块发送的。设想下,如果按照一个数据块(默认128M)大小发送数据,合理吗?至于数据包大小是如何确定的,我们后续再讲。
(二)如何通过数据输出流写入数据?
下面,该看看如何通过数据输出流写入数据了。要解决这个问题,首先分析下DFSOutputStream和DataStreamer是什么。
- DFSOutputStream
DFSOutputStream是分布式文件系统输出流,它内部封装了两个队列:发送数据包队列和确认数据包队列,如下:
// 发送数据包队列
private final LinkedList
// 确认数据包队列
private final LinkedList
客户端写入的数据,会addLast入发送数据包队列dataQueue,然后交给DataStreamer处理。
2、DataStreamer
DataStreamer是一个后台工作线程,它负责在数据流管道中往DataNode发送数据包。它从NameNode申请获取一个新的数据块ID和数据块位置,然后开始往DataNode的管道写入流式数据包。每个数据包都有一个序列号sequence number。当一个数据块所有的数据包被发送出去,并且每个数据包的确认信息acks被接收到的话,DataStreamer关闭当前数据块,然后再向NameNode申请下一个数据块。
所以,才会有上述发送数据包和确认数据包这两个队列。
DataStreamer内部有很多变量,大体如下:
// streamer关闭标志位
private volatile boolean streamerClosed = false;
// 扩展块,它的长度是已经确认ack的bytes大小
private ExtendedBlock block; // its length is number of bytes acked
private Token accessToken;
// 数据输出流
private DataOutputStream blockStream;
// 数据输入流:即回复流
private DataInputStream blockReplyStream;
// 响应处理器
private ResponseProcessor response = null;
// 当前块的数据块列表
private volatile DatanodeInfo[] nodes = null; // list of targets for current block
// 存储类型
private volatile StorageType[] storageTypes = null;
// 存储ID
private volatile String[] storageIDs = null;
// 需要排除的节点
private final LoadingCache excludedNodes =
CacheBuilder.newBuilder()
.expireAfterWrite(
dfsClient.getConf().excludedNodesCacheExpiry,
TimeUnit.MILLISECONDS)
.removalListener(new RemovalListener() {
@Override
public void onRemoval(
RemovalNotification notification) {
DFSClient.LOG.info("Removing node " +
notification.getKey() + " from the excluded nodes list");
}
})
.build(new CacheLoader() {
@Override
public DatanodeInfo load(DatanodeInfo key) throws Exception {
return key;
}
});
// 优先节点
private String[] favoredNodes;
// 是否存在错误
volatile boolean hasError = false;
volatile int errorIndex = -1;
// Restarting node index
// 从哪个节点重试的索引
AtomicInteger restartingNodeIndex = new AtomicInteger(-1);
private long restartDeadline = 0; // Deadline of DN restart
// 当前数据块构造阶段
private BlockConstructionStage stage; // block construction stage
// 已发送数据大小
private long bytesSent = 0; // number of bytes that've been sent
private final boolean isLazyPersistFile;
/** Nodes have been used in the pipeline before and have failed. */
private final List failed = new ArrayList();
/** The last ack sequence number before pipeline failure. */
// 管道pipeline失败前的最后一个确认包序列号
private long lastAckedSeqnoBeforeFailure = -1;
// 管道恢复次数
private int pipelineRecoveryCount = 0;
/** Has the current block been hflushed? */
// 当前数据块是否已被Hflushed
private boolean isHflushed = false;
/** Append on an existing block? */
// 是否需要在现有块上append
private final boolean isAppend; 有很多比较简单,不再赘述。这里只讲解几个比较重要的:
1、BlockConstructionStage stage
当前数据块构造阶段。针对create()这种写入 来说,开始时默认是BlockConstructionStage.PIPELINE_SETUP_CREATE,即管道初始化时需要向NameNode申请数据块及所在数据节点的状态,这个很容易理解。有了数据块和其所在数据节点所在列表,才能形成管道列表不是?在数据流传输过程中,即一个数据块写入的过程中,虽然有多次数据包写入,但状态始终为DATA_STREAMING,即正在流式写入的阶段。而当发生异常时,则是PIPELINE_SETUP_STREAMING_RECOVERY状态,即需要从流式数据中进行恢复,如果一个数据块写满,则会进入下一个周期,PIPELINE_SETUP_CREATE->DATA_STREAMING,最后数据全部写完后,状态会变成PIPELINE_CLOSE,并且如果发生异常的话,会有一个特殊状态对应,即PIPELINE_CLOSE_RECOVERY。而append开始时则是对应的状态PIPELINE_SETUP_APPEND及异常状态PIPELINE_SETUP_APPEND_RECOVERY,其它则一致。
2、volatile boolean hasError = false
这个状态位用来标记数据写入过程中,是否存在错误,方便进行容错。
3、ResponseProcessor response
响应处理器。这个也是后台工作线程,它会处理来自DataNode回复流中的确认包,确认数据是否发送成功,如果成功,将确认包从确认数据包队列中移除,否则进行容错处理。
create()模式下的DataStreamer构造比较简单,如下:
private DataStreamer(HdfsFileStatus stat, ExtendedBlock block) {
isAppend = false;
isLazyPersistFile = isLazyPersist(stat);
this.block = block;
stage = BlockConstructionStage.PIPELINE_SETUP_CREATE;
}
isAppend设置为false,即不是append写入,BlockConstructionStage默认为PIPELINE_SETUP_CREATE,即需要向NameNode写入数据块。
我们首先看下DataStreamer是如何发送数据的。上面讲到过,DFSOutputStream中包括两个队列:发送数据包队列和确认数据包队列。这类似于两个生产者消--费者模型。针对发送数据包队列,外部写入者为生产者,DataStreamer为消费者。外部持续写入数据至发送数据包队列,DataStreamer则从中消费数据,判断是否需要申请数据块,然后写入数据节点流式管道。而确认数据包队列,DataStreamer为生产者,ResponseProcessor为消费者。首先,确认数据包队列数据的产生,是DataStreamer发送数据给DataNode后,从发送数据包队列挪过来的,而当ResponseProcessor线程确认接收到数据节点的ack确认包后,再从数据确认队列中删除。
数据写入过程之DataStreamer
首先看DataStreamer的run()方法,它会在数据流没有关闭,且dfs客户端正在运行的情况下,一直循环,循环内处理的大体流程如下:
1、如果遇到一个错误(hasErro),且响应器尚未关闭,关闭响应器,使之join等待;
2、如果有DataNode相关IO错误,先预先处理,初始化一些管道和流的信息,并决定外部是否等待,等待意即可以进行容错处理,不等待则数目错误比较严重,无法进行容错处理:这里还判断了errorIndex标志位和restartingNodeIndex的大小,意思是是否是由某个具体数据节点引起的错误,如果是的话,这种错误理论上是可以处理的;
3、没有数据时,等待一个数据包发送:等待的条件是:当前流没有关闭(!streamerClosed)、没有错误(hasError)、dfs客户端正在 运行(dfsClient.clientRunning )、dataQueue队列大小为0,且当前阶段不是DATA_STREAMING,或者在需要sleep(doSleep)或者上次发包距离本次时间未超过阈值的情况下为DATA_STREAMING,意思是各种标记为正常,数据流处于正常发送的过程或者可控的非正常发送过程中,可控表现在状态位doSleep,即上传错误检查中认为理论上可以进行修复,但是需要sleep已完成recovery的初始化,或者距离上次发送未超过时间的阈值等。
4、如果数据流关闭、存在错误、客户端正常运行标志位异常时,执行continue:这个应该是对容错等的处理,让程序及时响应错误;
5、获取将要发送的数据包:
如果数据发送队列为空,构造一个心跳包;否则,取出队列中第一个元素,即待发送数据包。
6、如果当前阶段是PIPELINE_SETUP_CREATE,申请数据块,设置pipeline,初始化数据流:append的setup阶段则是通过setupPipelineForAppendOrRecovery()方法完成的,并同样会初始化数据流;
7、获取数据块中的上次数据位置lastByteOffsetInBlock,如果超过数据块大小,报错;
8、 如果是数据块的最后一个包:等待所有的数据包被确认,即等待datanodes的确认包acks,如果数据流关闭,或者数据节点IO存在错误,或者客户端不再正常运行,continue,设置阶段为pipeline关闭
9、发送数据包:将数据包从dataQueue队列挪至ackQueue队列,通知dataQueue的所有等待者,将数据写入远端的DataNode节点,并flush,如果发生异常,尝试标记主要的数据节点错误,方便容错处理;
10、更新已发送数据大小:可以看出,数据包中存储了其在数据块中的位置LastByteOffsetBlock,也就标记了已经发送数据的总大小;
11、数据块写满了吗?如果是最后一个数据块,等待确认包,调用endBlock()方法结束一个数据块 ;
如果上述流程发生错误,hasError标志位设置为true,并且如果不是一个DataNode引起的原因,流关闭标志设置为true。
最后,没有数据需要发送,或者发生致命错误的情况下,调用closeInternal()方法关闭内部资源。
DataNode之BlockReport解析
数据节点DataNode周期性发送心跳给名字节点NameNode的BPServiceActor工作线程,了解了它实现心跳的大体流程:
1、与NameNode握手:
1.1、第一阶段:获取命名空间信息并验证、设置;
1.2、第二阶段:DataNode注册;
2、周期性调用sendHeartBeat()方法发送心跳信息,并处理来自心跳响应中的命令;
3、调用reportReceivedDeletedBlocks()方法发送数据库增量汇报:包括正在接收的、已接收的和已删除的数据块;
4、调用blockReport()方法周期性进行数据块汇报,并处理返回的相关命令。
数据块增量汇报是负责向NameNode发送心跳信息工作线程BPServiceActor中周期性的一个工作,它负责向NameNode及时汇报DataNode节点上数据块的变化情况,比如数据块正在接收、已接收或者已被删除。它的工作周期要小于正常的数据块汇报,目的就是为了能够让NameNode及时掌握DataNode上数据块变化情况,以便HDFS系统运行正常,略显机智!而且,当数据块增量汇报不成功时,下一个循环会接着立即发送数据块增量汇报,而不是等其下一个周期的到来,这显示了HDFS良好的容错性.
文件拷贝方案讨论及分析
一、distcp
DistCp(Distributed Copy)是用于大规模集群内部或者集群之间的高性能拷贝工具。 它使用Map/Reduce实现文件分发,错误处理和恢复,以及报告生成。 它把文件和目录的列表作为map任务的输入,每个任务会完成源列表中部分文件的拷贝。
DistCp是Apache Hadoop自带的工具,目前存在两个版本,DistCp1和DistCp2,FastCopy是Facebook Hadoop中自带的,相比于Distcp,它能明显加快同节点数据拷贝速度,尤其是Hadoop 2.0稳定版(第一个稳定版为2.2.0,该版本包含的特性可参考我的这篇文章:Hadoop 2.0稳定版本2.2.0新特性剖析)发布后,当需要在不同NameNode间(HDFS Federation)迁移数据时,FastCopy将发挥它的最大用武之地。
DistCp第一版使用了MapReduce并发拷贝数据,它将整个数据拷贝过程转化为一个map-only Job以加快拷贝速度。由于DistCp本质上是一个MapReduce作业,它需要保证文件中各个block的有序性,因此它的最小数据切分粒度是文件,也就是说,一个文件不能被切分成不同部分让多个任务并行拷贝,最小只能做到一个文件交给一个任务。
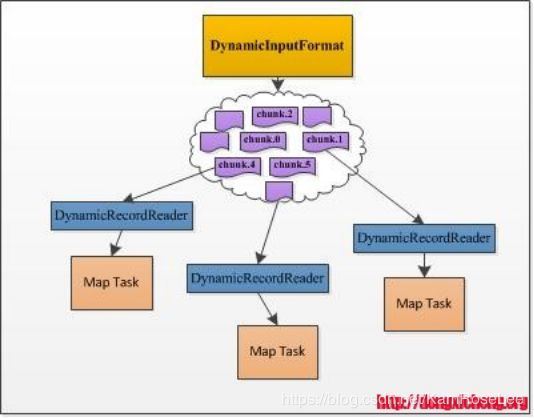
DistCp2针对DistCp1在易用性和性能等方面的不足,提出了一系列改进点,包括通过去掉不必要的检查缩短了目录扫描时间、动态分配各个Map Task的数据量、可对拷贝限速避免占用过多网络流量、支持HSFTP等。尤其值得一说的是动态分配Map Task处理数据量。DistCp1的实现跟我们平时写的大部分MapReduce程序一样,每个Map Task的待处理数据量在作业开始运行前已经静态分配好了,这就出现了我们经常看到的拖后腿的现象:由于一个Map Task分配的数据量过多,运行非常缓慢,所有Reduce Task都在等待这个Map Task运行完成。而对于DistCp而言,该现象更加常见,因为最小的数据划分单位是文件,文件有大有小,分到大文件的Map Task将运行的非常慢,比如你有两个待拷贝的文件,一个大小为1GB,另一个大小为1TB,如果你指定了超过2个的Map Task,则该DistCp只会启动两个Map Task,其中一个负责拷贝1GB的文件,另一个负责拷贝1TB的文件,可以想象其中一个任务将运行的非常慢。DistCp2通过动态分配Map Task数据量解决了该问题,它实现了一个DynamicInputFormat,该InputFormat将待拷贝的目录文件分解成很多的chunk,其中每个chunk的信息(位置,文件名等)写到一个以“.chunk.K”(K是一个数字)结尾的HDFS文件中,这样,每个文件可看做一份“任务”,“任务”数目要远大于启动的Map Task数目,运行快的Map Task能够多领取一些“任务”,而运行慢得则领取少一些,进而提高数据拷贝速度。尽管DistCp1中Map Task拷贝数据最小单位仍是文件,但相比于DistCp1,则要高效得多,尤其是在文件数据庞大,且大小差距较大的情况下。
不管是DistCp1还是DistCp2,在数据拷贝过程中均存在数据低效问题,尤其在Hadoop 2.0时代表现突出。Hadoop 2.0引入了HDFS Federation(什么是HDFS Federation,可参考:HDFS Federation设计动机与基本原理),当我们进行Hadoop(1.0升级到2.0)升级或者将一个NameNode扩展到多个NameNode时,需将集群中的单个NameNode上的部分数据迁移到其他NameNode上,此时就需要用到DistCp这样的工具。在HDFS Federation设计中,一个HDFS集群中可以有多个NameNode,但DataNode是共享的,因此,在数据迁移过程中,大部分数据所在的节点不会变(在同一个DataNode上),只需将其指向新的NameNode(即数据位置不变,元数据转移到其他NameNode上)。如果使用DistCp,则需要将数据重新通过网络拷贝一份,然后将旧的删除,性能十分低下。考虑到数据仍在同一个节点上,则采用文件硬链接.
二、FastCopy
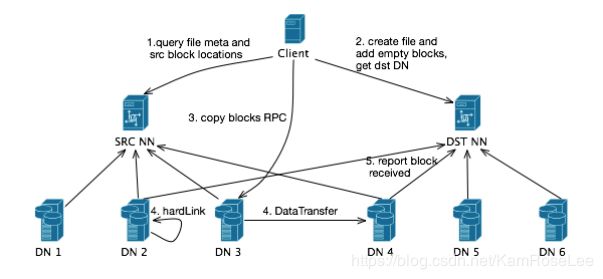
基于linux系统ln 本地创建文件的硬链接方式,提升拷贝速度。流程如下:
1、查询源NS中文件的meta信息,获取源文件所有的block信息
2、对于每个Block,获取其在原集群中的location信息
3、对于源文件中的每个block,在目标NS中的文件上添加空的block信息
4、对于所有的源Block,通过DN的copyBlock接口实现local copy
5、每个目标DN在完成block的copy之后向目标NS的NN中报告接收的Block
6、等待所有的block都copy完成后推出 基本结构如下:
详细介绍
1、File Meta复制
FastCopy首先获取源文件的meta信息(FileStatus)和blocks locations(LocatedBlocks)信息
检查源文件是否处于构建中,LocatedBlocks.isUnderConstruction(),如果是则跳过该文件
在目标NS中创建目标文件, 副本数,permission, blockSize等信息与源文件一致,为避免目标文件已存在,默认使用覆写模式创建
2、Block 复制
对于源文件的LocatedBlocks中所有的block信息,进行Block复制:
通过向目标NS中addBlock获取目标NS中block的DN 列表
对源block的DN列表和目标Block的DN列表进行排序对齐,使相同的DN在各自的列表中的位置相同
通过源Datanode的copyBlock()接口实现想目标DN的block数据复制DataNode.copyBlock()的具体实现分为三种情况:
a、同一DN实例
这种情况存在于Federation中同一DN节点服务于两个NS的情况,事实上只需要为源Block的文件创建一个HardLink指向目标block
b、同一节点上不通DN实例
(云梯中暂时不存在这种单节点多DN实例的情况) 这种情况实际上文件位于同一台物理节点上,也可以通过HardLink完成,但由于两个DN实例维护不不同的VolumeMap,因此,需要源DN实例调用目标DN的copyBlockLocal()接口实现,copyBlockLocal本质上也是使用HardLink来完成copy
c、不同DN节点
通常源DN和目标DN都是位于不同节点上的,需要通过网络传输block数据,这个传输过程与client向DN写入Block数据基本一致,因此可以直接使用DataTransfer来完成。
3、Lease更新
由于FastCopy在复制过程中需要对目标文件进行写入,但不是使用FileSystem的API(HDFS默认的lease机制是位于DFSClient中),因此FastCopy需要自己完成Lease的更新。对于每个copy的文件,FastCopy都需要启用一个LeaseChecker线程定期更新lease,保证数据写入的一致性。
4、复制状态监控
批量的文件copy是异步执行的,FastCopy内部通过一个fileStatusMap维护所有需要复制的文件,文件的状态中包括文件名,文件的block数以及已经完成复制的block, 以及一个blocksStatusMap维护每个需要复制的block的状态,block的状态包括block的副本总数,已经写入成功的副本数,以及写入失败的副本数。
三、fastcopy实现
1、类图结构
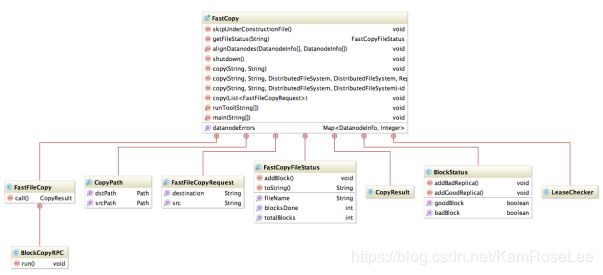
2、实现逻辑
FastCopy首先处理命令行参数,提取源文件和目标文件path,为每一个src:dst对构建FastCopyFileRequest
构建FastCopy实例处理FastCopyFileRequest
FastCopy内部的调度处理通过ExecutorService维护一个线程池(线程池大小可以通过命令行-t 参数来控制,默认是5),每个线程是由实现了Future接口的FastFileCopy来对每个文件的copy进行处理。
FastFileCopy内部实现上述设计文档描述的一个文件元信息copy的流程,并通过BlockCopyRpc异步调用DN的copyBlock接口实现block的复制
FastCopy为每个文件的copy维护一个LeaseChecker,更新lease信息。
同时FastCopy通过内部维护fileStatusMap和blocksStatusMap来对copy过程状态进行管理
Hdfs跨机房部署方案介绍及讨论
跨机房带宽限制、分配
不同机房客户端选择分配数据写入datanode节点
Hdfs数据读写瓶颈点分析
带宽
副本复制
磁盘io
工厂应用
重点使用Federation
在Hadoop 1.0中,HDFS的单NameNode设计带来诸多问题,包括单点故障、内存受限制约集群扩展性和缺乏隔离机制(不同业务使用同一个NameNode导致业务相互影响)等,为了解决这些问题,Hadoop 2.0引入了基于共享存储的HA解决方案和HDFS Federation,本文重点介绍HDFS Federation。
HDFS Federation是指HDFS集群可同时存在多个NameNode,这些NameNode分别管理一部分数据,且共享所有DataNode的存储资源。这种设计可解决单NameNode存在的以下几个问题:
(1)HDFS集群扩展性。多个NameNode分管一部分目录,使得一个集群可以扩展到更多节点,不再像1.0中那样由于内存的限制制约文件存储数目。
(2)性能更高效。多个NameNode管理不同的数据,且同时对外提供服务,将为用户提供更高的读写吞吐率。
(3)良好的隔离性。用户可根据需要将不同业务数据交由不同NameNode管理,这样不同业务之间影响很小。
需要注意的,HDFS Federation并不能解决单点故障问题,也就是说,每个NameNode都存在在单点故障问题,你需要为每个namenode部署一个backup namenode以应对NameNode挂掉对业务产生的影响。
使用策略:
1、按照业务进行Federation拆分
2、根据rpc、jvm监控nn压力,进行紧急拆