深度学习(1)-深度学习中的核函数(激活函数)
1.核函数的作用
激活函数、核函数(kernel method,kernel trick)是机器学习中一种重要的方法。一般定义是将原始表达转换到一个隐式特征空间去,该空间具有更好的特征可分性质。
在机器学习中,(一层线性卷积结构+一层核函数)*N的特殊结构,能拟合任何函数的原因。但如果只有N层的线性结构,那最后的组合还是线性结构,就相当于以前的感知机(perceptron)。使得类似神经网络结构从线性变成非线性的,就是每一层后加的核函数/激活函数。
在普通优化问题中,为了抑制outlier对结果影响太大,往往需要加一个核函数,来禁止或降低那些离散点对最终结果的影响。
从上边我们可以看出,核函数的作用,是将原始结果空间映射到一个新的输出空间,在这个映射过程中可以进行滤波,转换后的空间具有更好的特征可分性质。
一些概念
回归分析(regression analysis):找到自变量和因变量之间的关系。回归,就是测量一些独立自变量变化下因变量的平均值。回归模型的价值函数往往是一个值。回归方式有很多种,比如线性回归,逻辑回归。
线性回归是用自变量线性组合的方式去拟合输出,从而得到一个比较好的线性模型。
逻辑回归处理二分类问题,输出只有两种可能:是,不是;能,不能;做,不做…….。逻辑回顾会使用一个将原始结果映射到只有两个可能性的逻辑空间,最后得到的模型相当于一个边界,将输入分成2个部分。如二分类的softmax和二分类的SVM,都是常用的逻辑回归方法。
分类
分类重预测结果。分类模型的价值函数往往得到几个可能性,找出可能性最大的那个结果。
为了便于理解,我们以下只讲分类问题,认为所有结果是Nx1维的向量,其中正确结果为 [0,0...,0,1,0,...,0]T(1的位置是第i位) [ 0 , 0... , 0 , 1 , 0 , . . . , 0 ] T ( 1 的 位 置 是 第 i 位 )
2.Sigmoid函数
Sigmoid函数其实是一类函数。顾名思义,是指这一类函数都是S曲线的。它们都是将输入映射到[0,1]或[-1,1]这个区间上。
2.1 logistic function
常见的有sigmoid logistic function(以下简称此为sigmoid函数),它的输出可以表示概率(毕竟0-1)
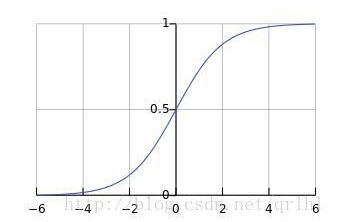
对它求导:
对应图:
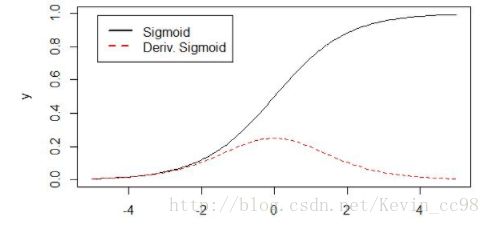
优点:[0,1]区间;类似神经元的放电饱和现象。
缺点:
随着输入增大,输出迅速减少,造成梯度饱和(梯度消失)现象;为了避免饱和,初始w时必须很小心地初始化以使得wx的值不会太大。
输出不是以0为中心(输出可能作为其他层的输入,对于所有输入,应该满足零均值化)
此外,exp计算量比较大。
3.4 tanh函数
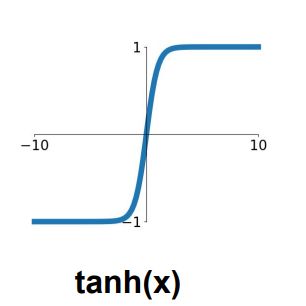
tanh函数的真实面目是缩放后的sigmoid函数:tanh(x)=2σ(2x)−1
优点:零均值化,[-1,1]之间
缺点:饱和问题,当x太大时梯度消失。
但
而ReLU就是解决这种情况的。
3.深度神经网络中用到的激活函数举例
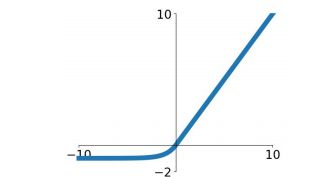
3.1Relu(Rectified Linear Unit)**;
此处的 Δ Δ 可以称为hinge loss(max-margin loss),是为了避免噪声对结果的影响,多分类中,正确类别的score必须超过错误的类别至少 Δ Δ ,才能使得对应的loss为0。这使得结果更加鲁邦。
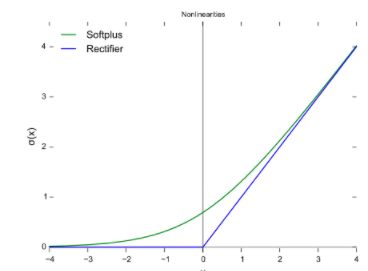
优点:ReLu求导很好求解,且没有梯度消散的问题;相比指数运算,计算量更少。
缺点:
非零均值化。求导时,只有正方向会update,负方向不会update。
3.2 Leaky ReLU
解决ReLU负方向不update的缺点。其中a值一般设为比较小,比如0.01。但a怎么设置以及这样设置的效果却不稳定;有人将其设为每个神经元自带的个性化参数,但这种方式的效果尚待进一步观察。
3.3 Exponential Linear Units (ELU)
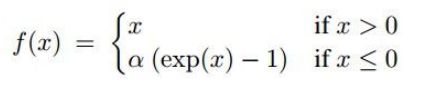
优点是:分布更接近于0,某种程度上达到了batch normalization的效果。ELU的提出者发现增加batch normalization对ELU没有什么效果,并且ELU>batch normalization+Relu。
但指数运算量比较大
3.4 Maxout
其实relu是这种形式 w1,b1=0 w 1 , b 1 = 0 时的特殊情况。
但maxout相比relu,参数数目增大了一倍。
4.Multiclass SVM:
支持向量机是由几个支持向量决定
典型的SVM分类器损失函数形如:
第i个example的loss:
其中 Δ Δ 是即为 hinge loss,是一个预设值。监督训练时,已知 yi y i 是正确label,那么这个loss function会保证经过线性变化后,如果W足够好,那么只有当正确的类别对应的第 yi y i 维的score至少比所有不正确的类别 sj s j 大 Δ Δ ,那样所有其他 sj−syi+Δ s j − s y i + Δ 才为负,score经过损失函数后映射大的值 fj f j 都为0,该样本的loss(所有 fj f j 之和)才会为0,即表示第i个样本属于j类的可能性达到最高。当然实际情况 yi y i 可能不能显著地都比j大 Δ Δ ,但只要足够好结果loss就会比较小。
所以,所有Hinge Loss问题,都是希望正确的分类对应的w[i,:]x极大大于不正确的分类对应的w[j,:]x,压制那些在hinge loss区域内不具有很高置信度的数据。
有时为了提高压制力度,还会对结果进行一个平方
5. softmax
softmax函数和SVM的loss是两大常用线性分类器
softmax =指数归一化+交叉熵损失(cross-entropy loss)。它是将信息论中的交叉熵原理用于评价模型好坏很好的例子。我们知道,交叉熵是用来衡量 损失函数可以衡量真实分布p与观测分布q的相似性。交叉熵的公式如图:
和信息熵的公式差别在于交叉熵用非真实分布q来衡量真实分布p的权重/期望/概率-log(q(i))。如果没有真实分布,可以按照贝叶斯的信念,将训练集中的分布当做最真实的分布,当然,这就是无监督学习中应用交叉熵的理论基础了。
如果q与p相等,则H(p,q)达到最小值,为信息熵。
从交叉熵这个角度看softmax:
if(i=yi),p(i)=1;else,p(i)=0; i f ( i = y i ) , p ( i ) = 1 ; e l s e , p ( i ) = 0 ;
q(i)=efyiΣjej q ( i ) = e f y i Σ j e j (对进行了一个指数映射,记住指数映射后,q(i)概率之和为1)
所以交叉熵相乘(只有一个维度非零)再相加:
从概率的角度上看:
先将所有结果映射到一个概率,然后利用MAP(Maximum a posteriori )估计,即找到与先验估计(即正确的分布p(i)有最大可能性的那个估计)。结合先验估计的办法就是交叉熵。
softmax的特点和优点是:
1)将指数进行了映射。这样映射的好处是:穷者不那么穷,富者不那么富有。会更好地考虑到那些概率小的数据。所以和SVM的max相比,它是软max。所以相比之下,上边的SVM具有一些局部最优解性质,softmax考虑全局(对SVM来说,这也有好处,比如SVM分类一张疑似小汽车图像时,大部分精力集中在排除卡车,而不会收到白色的军绕);SVM注重各个分类可能性之间的绝对差异,softmax更注重将各个可能性之间的相对差异。
2)交叉熵损失函数可以衡量p与q的相似性或者说差距;交叉熵作为损失函数还有一个好处是使用sigmoid函数,在梯度下降时能避免均方误差损失函数学习速率降低的问题
softmax的导数是:
可见,求导很简单,只要将第i个结果的各维度映射到(0,1)区间,再将正确的维度-1就是导数(当然实际中往往不是求L关于f而是L关于x的导数,即 dWij d W i j
softmax实际使用注意事项
对于比较大的数,比如超过四位数,指数映射,数值太大很容易溢出。因此实际使用中往往减去最大的 fj f j ,将最大值拉回到零处:
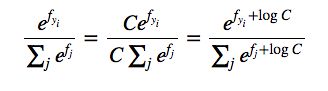
其中一般:
6.谈谈cost function
对于一个输入来说,除了需要映射到一个符合分类、回归需要的空间中,还要判别这个映射过程好不好(涉及到线性分类器的W参数矩阵选择)。这由损失函数来判断。常见的损失函数有L-2norm方法:
定义损失函数时,需要考虑到最终的计算,比如最好定义成是一个凸问题,容易求全局最优解。比如sigmoid逻辑回归时定义:
由于0< fθ(x) f θ ( x ) <1
fθ(x) f θ ( x ) 为监督结果为1的概率。
如果监督结果为1,则当概率 fθ(x) f θ ( x ) 为1,则损失为0,如果接近0,则损失很大;
如果监督结果不为1(为0),则当概率 fθ(x) f θ ( x ) 为0时(即为0的概率为1),损失为0。合并以上分段函数,最终:
则可以用梯度下降等方法来求解这个cost function。
Does not saturate!.Does not die.
其他函数:
Hierarchical Softmax
建议:
- Use ReLU. Be careful with your learning rates
- Try out Leaky ReLU / Maxout / ELU
- Try out tanh but don’t expect much
- Don’t use sigmoid
(待更新)