六、ELK6.0日志从收集到处理完整版教程
一、使用场景
在分布式的系统中,一个服务会被部署多份,并且部署在不同的服务器上。这样日志就分散在不同的服务器上,如果系统发生异常错误,想要排查异常是十分麻烦的,只能逐个到每台服务器上去寻找日志信息,而如果能将不同服务器的日志集中到一起并能够使用软件分析日志数据,那么排查问题就会简单的多了。
二、ELK简介
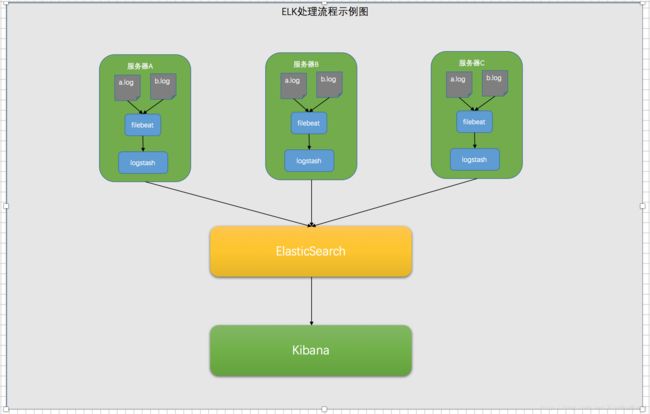
Elasticsearch
开源分布式搜索引擎,它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。也可以认为ElasticSearch是一个NoSQL存储中心,可以存储各种数据,并且查询速度超级快。
Logstash
完全开源的工具,可以从各种输入流(文件,队列,数据库)收集信息,并对信息进行处理,将处理后的信息存储到ElasticSearch
kibana
开源和免费的工具,它可以从ElasticSearch读取日志等存储的信息, 提供的日志分析友好的 Web 界面,可以帮助您汇总、分析和搜索重要数据日志。
他们之间的关系如下图
三、资源下载
ElasticSearch
Kibana
Logstash
Filebeat
注意点:elastic系列软件的版本必须相同,也就是所有的软件版本号要一样才能正常使用。推荐全部下载最新版本。

四、Filebeat安装与配置
1.将下载好的filebeat-6.0.0-linux-x86_64.tar.gz解压到系统对应目录。
tar -zxf filebeat-6.0.0-linux-x86_64.tar.gz2.修改解压目录中的filebeat.yml配置文件,如下
filebeat.prospectors:
- type: log
paths:
- /kingboy/logstash-tutorial.log
- /kingboy/king.log
multiline.pattern: '^\['
multiline.negate: true
multiline.match: after
output.logstash:
hosts: ["localhost:5043"]3.配置说明
paths
指定要收集的日志文件的地址,如有多个日志文件,可以写多行进行配置。
支持通配符进行匹配,如:- /kingboy/*.log达到的效果和上面的配置是一样的multiline.*
filebeat处理log文件是按行处理的,也就是说会把一行当成一条数据进行处理,那么log中的异常信息就会被当成多条日志分开处理,显然不是我们想要的。这三行的作用就是将异常信息归并到上一条日志信息中。
pattern
value为正则表达式,
'^\['表示不是以[开头的行,都当做是异常信息,归并为一行。negate
true 或 false;默认是false,匹配pattern的行合并到上一行;true,不匹配pattern的行合并到上一行 Default is false.
match
after 或 before,合并到上一行的末尾或开头。
multiline配置前的效果

multiline配置后的效果

hosts
设定发送到logstash的地址,一般安装在同一台主机上,所以一般为
localhost:5043。当我们配置Logstash的时候会设置这个端口,先不要着急。
- 启动命令
进入到解压目录
sudo ./filebeat -e -c filebeat.yml -d "publish"现在启动会失败,因为启动时会连接logstash,而logstash我们还没安装。当我们完成logstash的安装和启动,再启动filebeat就可以了。
五、ElasticSearch安装与配置
之前写过一篇文章专门介绍ElasticSearch的安装,就不重复了。传送门
只是版本不同,过程是一样一样的。
六、LogStash安装与配置
1.将下载好的logstash解压到系统对应目录
tar -zxf logstash-6.0.0.tar.gz2.配置logstash
我们需要为logstash创建一个配置文件,进入到logstash目录,创建logstash.conf文件,
vim logstash.conf内容如下
input {
beats {
port => "5043"
}
}
filter {
grok {
match => { "message" => "\[%{IP:ip}\] \[%{TIMESTAMP_ISO8601:timestamp}\] \[%{NOTSPACE:class}\]"}
}
}
output {
elasticsearch {
hosts => [ "http://172.16.160.176:9200" ]
}
}3.配置说明
logstash的配置氛围三大块(input,filter,output), 这个就不废话了。
input
定义输入流,我们这里使用beatfile进行输入,所以定义很简单。
filter==>grok
对filebeat的输入信息进行处理,根据正则匹配日志中的每一行信息,将信息格式化成相应的字段,发送给ElasticSearch进行存储。(稍后进行详细说明)。
output
填写自己的ElasticSearch的地址
4.filter=>grok的注意点
1.关于正则的校验
可以进入网址http://grokdebug.herokuapp.com/,对我们的正则进行校验
2.正则中的写法
前面的IP、NOTSPACE、TIMESTAMP是logstash中内置的类型,不是我们随便写的,后面的ip是我们自己定义的字段名称,可以随意定义,会被ElasticSearch处理成一个属性名(类似mysql中的列名)。
来几个例子
#日志
55.3.244.1 GET /index.html 15824 0.043
#对应的正则
%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}详细可以参考:
https://www.cnblogs.com/stozen/p/5638369.html
3.正则的写法
我的日志中的格式如下(本博文中就是使用如下格式的日志文件)
[192.168.43.121] [2017-11-13 19:11:56] [PersonService.save]
[192.168.43.121] [2017-11-13 19:11:56] [PersonService.save]
[192.168.43.121] [2017-11-13 19:11:56] [PersonService.save]所以对应的正则书写为
\[%{IP:ip}\] \[%{TIMESTAMP_ISO8601:timestamp}\] \[%{NOTSPACE:class}\]5.启动命令
进入到安装目录,执行以下命令
bin/logstash -f logstash.conf七、Kibana安装与配置
1.将下载好的Kibana解压到对应的目录
tar -zxf kibana-6.0.0-linux-x86_64.tar.gz2.在配置文件中config/kibana.yml添加如下内容
#将本机的外网ip地址配置上,这样外网才能访问到(更换为你的ip地址))。
server.host: "172.16.160.176"
#配置Elastic的地址,同台机器使用localhost,不同机器使用ip(我是和ES安装一起的)
elasticsearch.url: "http://localhost:9200"注意点
如果外网还访问不到,请检查自己的防火墙设置。简单粗暴的做法就是将防火墙关闭
service iptables stop,(centOS7,请检查firewall)
3.启动命令
进入到程序解压目录
bin/kibana4.外网访问
http://ip:5601
5.关于Kibana的使用
使用方法网上还是有很多的,就不重复写了。其实自己摸索一会,随便点点就差不多回了。
七、说明
这些步骤都是参照Elastic的官网文档进行配置完成的。写这篇博客给自己做个安装记录,更加倾向于如何安装配置,而没有如何使用的内容,其中ElasticSearch的安装过程是比较繁琐的,一定要有耐心,当初也折腾了很久。
关于具体的操作使用可以搜索下相关其它的博客,加强理解。