hadoop2.7完全分布式集群搭建以及任务测试
要想深入的学习hadoop数据分析技术,首要的任务是必须要将hadoop集群环境搭建起来,本文主要讲述如何搭建一套hadoop完全分布式集群环境。
环境配置:2台64位的redhat6.5 + 1台64位centos6.9 + Hadoop + java7
一、先配置服务器的主机名
Namenode节点对应的主机名为master
Datanode节点对应的主机名分别为node1、node2
1、 在每一台服务器上执行vim /etc/hosts, 先删除hosts里面的内容,然后追加以下内容:
192.168.15.135 master
172.30.25.165 node1
172.30.25.166 node22、 在每一台服务器上执行vim /etc/sysconfig/network,修改红色部分的内容,对应上面所说的hostname,对于master节点那么hostname就为master
NETWORKING=yes
HOSTNAME= master
NETWORKING_IPV6=yes
IPV6_AUTOCONF=no类似的,在node1服务器节点上应该为:
NETWORKING=yes
HOSTNAME= node1
NETWORKING_IPV6=yes
IPV6_AUTOCONF=no类似的,在node2服务器节点上应该为:
NETWORKING=yes
HOSTNAME= node2
NETWORKING_IPV6=yes
IPV6_AUTOCONF=no这两步的作用很关键,如果配置不成功,进行分布式计算的时候有可能找不到主机名
二、安装SSH,并让master免验证登陆自身服务器、节点服务器
1、 执行下面命令,让master节点能够免验证登陆自身服务器
ssh-keygen -t dsa -P'' -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub>> ~/.ssh/authorized_keys
exportHADOOP\_PREFIX=/usr/local/hadoopHADOOP_PREFIX表示自己安装的hadoop路径
2、 让主结点(master)能通过SSH免密码登录两个子结点(slave)
为了实现这个功能,两个slave结点的公钥文件中必须要包含主结点的公钥信息,这样当master就可以顺利安全地访问这两个slave结点了。操作过程如下:
在node1上执行
scp root@master:~/.ssh/id_dsa.pub ~/.ssh/master_dsa.pub
cat~/.ssh/master_dsa.pub >> ~/.ssh/authorized_keys在node2上执行
scp root@master:~/.ssh/id_dsa.pub ~/.ssh/master_dsa.pub
cat~/.ssh/master_dsa.pub >> ~/.ssh/authorized_keys如上过程显示了node1结点通过scp命令远程登录master结点,并复制master的公钥文件到当前的目录下,这一过程需要密码验证。接着,将master结点的公
钥文件追加至authorized_keys文件中,通过这步操作,如果不出问题,master结点就可以通过ssh远程免密码连接node1结点了。在master结点中操作如:

当然值得注意的是:首次登陆是需要确认的,node1结点首次连接时需要,“YES”确认连接,这意味着master结点连接node1结点时需要人工询问,无法自动连接,输入yes后成功接入,紧接着注销退出至master结点。要实现ssh免密码连接至其它结点,还差一步,只需要再执行一遍ssh node1,如果没有要求你输入”yes”,就算成功了。
三、下载并解压hadoop安装包,配置hadoop
1、 关于安装包的下载就不多说了,不过可以提一下目前我使用的版本为hadoop-2.7.1
2、 配置namenode,修改site文件
下面开始修改hadoop的配置文件了,即各种site文件,文件存放在etc/Hadoop/下,主要配置core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml这三个文件。
这里我只把我的实例贴出来,经供参考,更多详细配置请参照官方文档
core-site.xml:
fs.defaultFS
hdfs://master:9000
hdfs-site.xml:
dfs.replication
1
dfs.namenode.secondary.http-address
master:9001
mapred-site.xml:
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
master:10020
mapreduce.jobhistory.webapp.address
master:19888
yarn-site.xml:
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
yarn.resourcemanager.address
master:8032
yarn.resourcemanager.scheduler.address
master:8030
yarn.resourcemanager.resource-tracker.address
master:8031
yarn.resourcemanager.admin.address
master:8033
yarn.resourcemanager.webapp.address
master:8088
3、 配置namenode,修改env环境变量文件
配置之前要说的话:你必须确保你已经安装了java6或者java7,并且java的环境变量已经配置好,由于本文的重点不在此,故不详细说明,我系统java的环境变量为/usr/java/jdk1.7.0_71
所以讲hadoop-env.sh、mapred-env.sh、yarn-env.sh这几个文件中的JAVA_HOME改为/usr/java/jdk1.7.0_71,如下图所示:

文件中的其他一些配置项,请参考官方文档
4、 slaves文件配置,增加如下两行内容:
node1
node2四、向节点服务器node1、node2复制我们刚刚在master服务器上配置好的hadoop
scp–r hadoop root@node1:/usr/local/hadoop
scp–r hadoop root@node2:/usr/local/hadoop五、格式化namenode,在master节点上执行如下命令:
bin/hdfs namenode-format 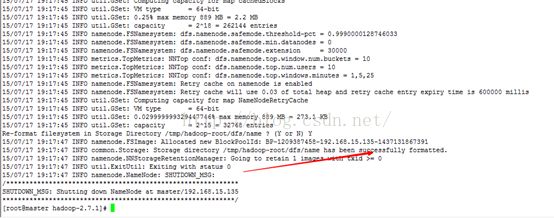
只要出现“successfully formatted”就表示成功了。
六、启动hadoop
这一步也在主结点master上进行操作:

七、用jps检验各后台进程是否成功启动
master

node1

node2

八、向hadoop集群系统提交第一个mapreduce任务
到这里为止我们已经完成了一个真正意义上的hadoop完全分布式环境搭建,下面我们要像这个集群系统提交第一个mapreduce任务
1、 bin/hdfs dfs -mkdir /tmp 在虚拟分布式文件系统上创建一个测试目录tmp
2、 bin/hdfs dfs -copyFromLocal ./ LICENSE.txt /tmp 将当前目录下的LICENSE文件复制到虚拟分布式文件系统中
3、bin/hdfs dfs-ls /tmp查看文件系统中是否存在我们所复制的文件
下面这张图显示了一系列的操作过程

3、 运行如下命令向hadoop提交单词统计任务
bin/hadoop jar./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar wordcount/tmp/LICENSE.txt /tmp-output
最后会显示一个运算结果:

到这里为止,你已经完成了第一个任务的分布式计算
注意:在你重新格式化分布式文件系统之前,需要将文件系统中的数据先清除,否则,datanode将创建不成功,这一点很重要
关于一些常见的端口
master:8088能显示你的集群状态
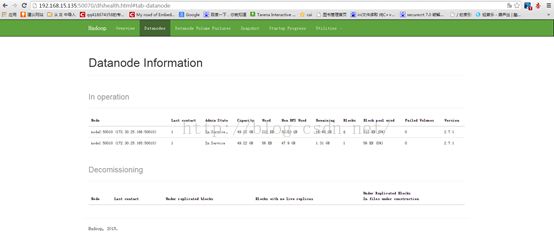
master: 50070能进行一些节点的管理
除此之外,还有很多有用的端口,当然这也是和你的配置文件相关的,最后,贴上两张图片: