PRML读书笔记(一)
从多项式拟合开始
机器学习中的有监督学习
机器学习中的有监督学习,是指训练样本包含输入向量以及对应的目标向量。即 (x,y) , x 和 y 为向量。
对于向量 y ,若它由离散变量组成,则被称为分类(classification)问题。如对数字识别,输入 x 为包含数字的图像向量, y 为对应的真实值类别 0,1,2,⋯,9 ;
若 y 由连续变量组成,则被称为回归(regression)问题。如多项式拟合问题;
多项式拟合例子
现在有函数 t=sin(2πx) ,想用一种简单的方式进行曲线拟合,如下函数:
M是多项式的阶数, w 是多项式的系数,现在我们想要确定的是多项式阶数M和系数 w 。
如何确定?
这里就引入了误差函数的概念。可以通过最小化误差函数(error function)来实现。误差函数是衡量真实值与预测值之间差距的函数。一种广泛应用的误差函数是每个数据点 xn 的预测值 y(xn,w) 和目标值 tn 的平方和,即最小化
其中, 12 是为了计算方便。由于(1)式是 w 的二次函数,因此它的最小值有唯一解,记作 w∗ ,最终的多项式可以由 y(x,w∗) 给出。
我们可以通过给 t=sin(2πx) 加上一些随机噪声来产生数据,即 t=sin(2πx)+δ
δ 服从高斯分布。取10组数据 (x,t) .

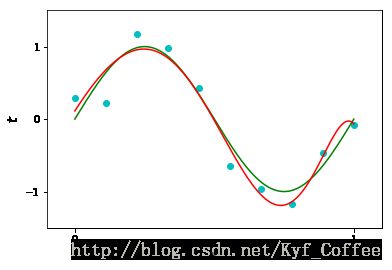
根据不同的阶数,可以拟合出不同的模型。取M=0,1,3,9

从上图可以看到,对于M=0或者M=1,多项式的拟合效果很差,很难识别出数据点中隐含的规律 t=sin(2πx) ,对于M=3,多项式曲线能通过大部分的点,曲线的形状也近似等于 t=sin(2πx) ;对于M=9,多项式曲线通过了所有十个点,此时误差函数 E(w∗)=0 ,但它是我们想要的拟合多项式吗?显然不是,因为它的曲线形状完全与 t=sin(2πx) 不符,这种现象叫做过拟合(overfitting)。
如何解决过拟合?
首先尝试加大数据量。取N=100,做同样的实验。

发现随着N的增大,过拟合的现象在减少。
但若一定要在N=10的数据上使用该模型呢?通常的做法是给参数加一个正则项的约束防止过拟合,一个最常用的正则项是平方正则项,即控制所有参数的平方和大小:
∥w∥2≡=wTw=w20+w21+⋯+w2M , λ 是控制正则项和误差项的相对重要性的参数。
概率论
第一章介绍了概率论中的一些基本概念,sum rule和product rule,以及bayes公式,期望、方差、协方差等概念。重点记录一下贝叶斯概率。
Bayes概率
对于一组模型参数 w ,假设服从先验概率分布 p(w) 。
D{t1,t2,⋯tn} 是我们观测到的一组数据,这组数据在参数 w 下的条件概率分布为 p(D|w) .
由Bayes公式知:
这样我们就可以通过 D 来确定 w 。
似然函数
p(D|w) 可以看成是给定观测数据 D 的情况下关于参数向量 w 的一个函数,通常叫做似然函数(likelihood function)。
似然函数反映了在给定一组参数 w 的情况下,生成这组观测数据的一种可能性。注意它并不是一个关于 w 的概率分布。
因此Bayes公式可表示为:
即后验概率正比与似然函数和先验概率的积,这三个量都是 w 的函数。分母是一个归一化常数。
PS:对于bayes估计和最大似然估计还需要琢磨。
信息论
熵的概念
书里的关于熵的直观解释让我记忆深刻。对于离散变量x,它包含的信息量是多少?可以这么去感受,如果不经常发生的x发生了,则“惊讶程度”就会高,可以理解为信息量大;反之,信息量小。这就把信息量和x发生的概率 p(x) 联系在了一起。
随机变量x的熵:
连续变量的熵:
以及条件熵、相对熵、互信息等定义书中都作了说明。
总结
第一章从一个例子开始,引入了模式识别与机器学习中的相关概念和所需的部分理论知识。文中从平方损失出发,逐步融入概率的思想对期望风险的解释,使我对损失函数有了新的认识。练习题1.16中对于D维M阶多项式独立参数个数的讨论使我对多项式模型的复杂程度有了很直观的认识。同时,还有许多问题还需要反复琢磨。
习题答案
习题答案coding