Coarse-to-fine CNN 人脸特征点定位思路
Reference: Erjin Zhou,Haoqiang Fan,Zhimin Cao,Yuning Jiang,Qi Yin. Extensive facial landmark localization with coarse-to-fine convolutional network cascade

Deep convolutional neural networks (DCNN) 已经成功地应用在了人脸特征点定位上,它有两个优点:
1.人脸特征点间的几何约束隐式地被利用到了。
2.大量的训练数据可以被利用进来。
但是当要定位大量人脸特征点(多于50点)时,传统的CNN在结构设计和训练过程中会面临巨大的挑战。
而这篇论文设计了一种更加有效的四级CNN级联网络。
介绍级联CNN结构前,先简单说一下人脸特征点定位的三种思路:
1.基于局部块分类;2.ASM/AAM;3.基于显式地回归方法。
第一种方法是用滑动窗口扫描图像,用局部块分类器分类,效果最差,因为它很难将全局的纹理信息利用到局部搜索框架中。
第二种方法曾经很流行,它可以为全局人脸外观建立通用模型,所以对局部图像损坏是稳键的,但是它的计算代价很高,需要大量迭代步骤。
第三种方法是最近开始采用的新的框架,该方法将特征点定位直接看作一个回归任务,用一个全局的回归器来计算特征点的坐标。与前面的两种方法相比,这种方法更稳健,因为全局的上下文信息在一开始时被用到;同时它也是高效的,因为不需要迭代步骤,也不需要滑动窗口。
但是人脸特征点定位仍然是一项非常有挑战的工作,因为人脸表情、姿势、光照等变化很多。同时,人脸不同位置特征点的定位难度是不同的,要是用一种单一的模型来定位的话,效果不会太好。
所以本论文用多模型来定位不位置的特征点,即将人脸分为内部点组(51点)与边界点组(17点)来分别定位。
(边界点的定位难点:1.局部纹理信息少;2.定义模糊,背景噪声大)
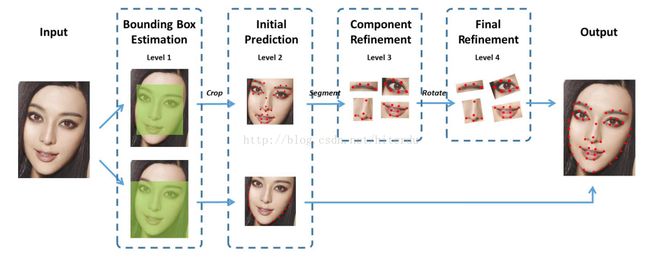
论文中4级CNN级联网络的设计:
1.分成两个并行的CNN级联网络,一个是4级级联,用于计算内部特征点(51点)的位置,第1级用于估计内部特征点的bounding box,第2级用于初步估计特征点的位置,第3组用于进一步精确估计各组成部分特征点的位置(左右眼睛、眉毛,鼻子,嘴巴6个部分),第4级是对进行了旋转校正后的6部分进行特征点精确定位。
2.另一组是2级级联的CNN,第1组用于估计边界点(17点)的bounding box,第2级用于估计17个边界特征点的准确位置。
之所以两组CNN的第1级都在定位bounding box上,是因为传统的DCNN在先验知识不足时,卷积网络大部分的力量都浪费在寻找人脸上了。
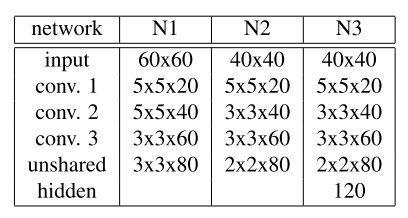
具体每一级CNN的设计如下:
都是4个卷积层加一个全连接层,卷积层后跟的都是最大值池化层,同时滤波后的激活函数采用双曲正切函数,这可以给网络带来很好的非线性拟合能力。
比较有特色的是最后一个卷积层叫作 非权值共享的卷积层,该层在不同位置采用的权值是不同的,所以该层严格来说是一个局部的感知器,而非传统的卷积层。
同时,最大值池化层的滑动间隔是非重叠的。池化层会丢失一些信息,那为什么这里还采用呢?因为对整个网络而言,池化所带来的稳健性能很好的补偿这种损失;而且特征点的形状和相对位置比像素级信息更重要的!

输入图像的预处理:
1.进行0均值1方差的归一化处理
2.用一个双曲正切函数将像素值映射到[-1,1]
3.将bounding box放大百分之10到20,然后进行裁剪
(这样可以保留更多的内容信息,同时让系统对第一级CNN估计bounding box的小误差有一定容忍性)
4.第4级CNN的输入图像是人脸各个局部(左右眼睛,左右眉毛,鼻子,嘴巴,6个部位),用两个角的特征点计算其角度,对局部图像进行旋转矫正。
旋转不宜在前面几级CNN进行,因为要是旋转角度估计失败的话,它产生的错误会被后续几级的CNN放大,这是非常严重的问题。
5.为了避免过拟合,图像会随机地进行一些旋转、平移、缩放的变换,这样可以生成大量的训练样本。同时也会对图像进行翻转,这样可以对右眼睛、眉毛复用左眼睛、眉毛的模型。
训练用SGD。
论文的三点贡献:
1.验证了级联CNN对大量人脸特征点定位的有效性
2.Coarse-to-fine的级联网络分散了网络的复杂性与训练负担。
3.表明了显式的几何修正(估计各部分的位置、旋转)可以显著地提升正确率和稳定性。