集成学习AdaBoost算法原理及python实现
1 集成学习简介
根据个体学习器的生成方式,目前集成学习方法大致分为两大类:
一是序列化方法,其代表算法为Boosting,该方法个体学习器存在强依赖关系、必须串行生成(对于AdaBoost算法,反应在,权值更新上);
二是并行化方法,其代表算法为Bagging和随机森林(Random Forest),该算法个体学习器之间没有强依赖关系,可同时生成。
对于分类问题,
Bagging算法,首先通过有放回的随机采样方式,从原始数据集中采样,新的采样样本应和原始数据集样本数相同,共采样出M个新的采样样本集合,同时训练M个分类器,采用少数服从多的分类原则,从M个分类器中找出投票结果最多的类别作为最后的分类结果。
Boosting算法,首先从原始数据集中训练出一个基学习器,再根据该基学习器的表现,对原始样本分布进行调整,使得先前基学习器错位分类的样本在下一次的训练学习器中受到更多关注,基于调整后的样本分布训练下一个基学习器,以此,训练出M个基学习器,并加权求和M个基学习器,利用sign函数得出最后的分类结果。AdaBoost算法是Boosting算法较为流行的版本,接下来将会对该算法进行详细描述,并给出python实现代码。
2 AdaBoost算法原理
AdaBoost全称是adaptive boosting,该算法基本思想:多个结构较为简单,分类或预测精度较低的弱学习算法可以通过某种方式结合成具有较强学习能力的强学习算法。根据统计学习方法的三要素,AdaBoost 方法=加法模型+指数损失函数(策略)+前向分步 算法。其 运行过程如下:训练数据中的每个样本,赋予其一个权重,这些权重构成全会向量D,D的初始值为1/N,N为训练样本数,首先在训练集上训练处一个弱分类器,并计算该分类器的分类误差率,根据分类误差率计算该分类器在总的集成分类器中所占的比例系数alpha,根据alpha,标签真值,分类估计值来调整训练样本的权值分布,加大错误分类样本的权值,使其在下一次的分类器训练过程中受到更多关注,与此同时减少正确分类样本的权值,之后进行第二次分类器训练,循环指导训练错误率为0或者弱分类器数目达到用户的指定值为止。下图为AdaBoost算法的示意图:
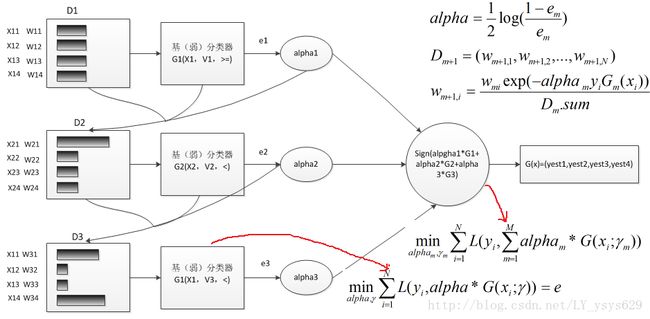
图中,红线所指示公式为,基分类器的目标函数,以及adaboost加法模型的目标函数。
注意:下一篇博客会着重介绍boosting算法应用中需要注意的问题
3 基于单层决策树的AdaBoost算法python实现
3.1 算法实现伪代码
for i from(1,2,…,M)
1)找出最佳单层决策树:
将最小分类误差率minerror=inf
对数据集中的每一个特征:
对该特征的每个步长(找出决策阈值):
对每个不等号(>=,<):
建立一颗单层决策树(只包含树桩)并利用加权数据集并计算该决策树的分类误差率
如果分类误差率小于minerror,则将当前单层决策树设置成最佳单层决策树。
2)利用单层决策树的分类误差率计算该决策树的比例系数alpha
3)计算更新权重向量D
4)更新累计类别估计值,计算AdaBoost模型的错误率
5)如果错误率为0或者分类器数目i>M,则退出循环
3.2 python 实现代码
# -*- coding: utf-8 -*-
"""
Created on Thu Jun 01 09:29:18 2017
Adaboost
@author: liujiping
"""
import numpy as np
def loadSimData():
'''
输入:无
功能:提供一个两个特征的数据集
输出:带有标签的数据集
'''
datMat = np.matrix([[1. ,2.1],[2. , 1.1],[1.3 ,1.],[1. ,1.],[2. ,1.]])
classLabels = [1.0, 1.0, -1.0, -1.0, 1.0]
return datMat, classLabels
def stumpClassify(dataMatrix,dimen,thresholdValue,thresholdIneq):
'''
输入:数据矩阵,特征维数,某一特征的分类阈值,分类不等号
功能:输出决策树桩标签
输出:标签
'''
returnArray = np.ones((np.shape(dataMatrix)[0],1))
if thresholdIneq == 'lt':
returnArray[dataMatrix[:,dimen] <= thresholdValue] = -1
else:
returnArray[dataMatrix[:,dimen] > thresholdValue] = -1
return returnArray
def buildStump(dataArray,classLabels,D):
'''
输入:数据矩阵,对应的真实类别标签,特征的权值分布
功能:在数据集上,找到加权错误率(分类错误率)最小的单层决策树,显然,该指标函数与权重向量有密切关系
输出:最佳树桩(特征,分类特征阈值,不等号方向),最小加权错误率,该权值向量D下的分类标签估计值
'''
dataMatrix = np.mat(dataArray); labelMat = np.mat(classLabels).T
m,n = np.shape(dataMatrix)
stepNum = 10.0; bestStump = {}; bestClassEst = np.mat(np.zeros((m,1)))
minError = np.inf
for i in range(n):
rangeMin = dataMatrix[:,i].min(); rangeMax = dataMatrix[:,i].max()
stepSize = (rangeMax - rangeMin)/stepNum
for j in range(-1, int(stepNum)+1):
for thresholdIneq in ['lt', 'gt']:
thresholdValue = rangeMin + float(j) * stepSize
predictClass = stumpClassify(dataMatrix,i,thresholdValue,thresholdIneq)
errArray = np.mat(np.ones((m,1)))
errArray[predictClass == labelMat] = 0
weightError = D.T * errArray
#print "split: dim %d, thresh: %.2f,threIneq:%s,weghtError %.3F" %(i,thresholdValue,thresholdIneq,weightError)
if weightError < minError:
minError = weightError
bestClassEst = predictClass.copy()
bestStump['dimen'] = i
bestStump['thresholdValue'] = thresholdValue
bestStump['thresholdIneq'] = thresholdIneq
return bestClassEst, minError, bestStump
def adaBoostTrainDS(dataArray,classLabels,numIt=40):
'''
输入:数据集,标签向量,最大迭代次数
功能:创建adaboost加法模型
输出:多个弱分类器的数组
'''
weakClass = []#定义弱分类数组,保存每个基本分类器bestStump
m,n = np.shape(dataArray)
D = np.mat(np.ones((m,1))/m)
aggClassEst = np.mat(np.zeros((m,1)))
for i in range(numIt):
print "i:",i
bestClassEst, minError, bestStump = buildStump(dataArray,classLabels,D)#step1:找到最佳的单层决策树
print "D.T:", D.T
alpha = float(0.5*np.log((1-minError)/max(minError,1e-16)))#step2: 更新alpha
print "alpha:",alpha
bestStump['alpha'] = alpha
weakClass.append(bestStump)#step3:将基本分类器添加到弱分类的数组中
print "classEst:",bestClassEst
expon = np.multiply(-1*alpha*np.mat(classLabels).T,bestClassEst)
D = np.multiply(D, np.exp(expon))
D = D/D.sum()#step4:更新权重,该式是让D服从概率分布
aggClassEst += alpha*bestClassEst#steo5:更新累计类别估计值
print "aggClassEst:",aggClassEst.T
print np.sign(aggClassEst) != np.mat(classLabels).T
aggError = np.multiply(np.sign(aggClassEst) != np.mat(classLabels).T,np.ones((m,1)))
print "aggError",aggError
aggErrorRate = aggError.sum()/m
print "total error:",aggErrorRate
if aggErrorRate == 0.0: break
return weakClass
def adaTestClassify(dataToClassify,weakClass):
dataMatrix = np.mat(dataToClassify)
m =np.shape(dataMatrix)[0]
aggClassEst = np.mat(np.zeros((m,1)))
for i in range(len(weakClass)):
classEst = stumpClassify(dataToClassify,weakClass[i]['dimen'],weakClass[i]['thresholdValue']\
,weakClass[i]['thresholdIneq'])
aggClassEst += weakClass[i]['alpha'] * classEst
print aggClassEst
return np.sign(aggClassEst)
if __name__ == '__main__':
D =np.mat(np.ones((5,1))/5)
dataMatrix ,classLabels= loadSimData()
bestClassEst, minError, bestStump = buildStump(dataMatrix,classLabels,D)
weakClass = adaBoostTrainDS(dataMatrix,classLabels,9)
testClass = adaTestClassify(np.mat([0,0]),weakClass)
4 参考文献
1.统计学习方法—-李航
2.机器学习———周志华
3.机器学习实践—-李锐、李鹏译