Hadoop本地模式、伪分布式和全分布式集群安装与部署
目录
准备
软件版本
集群规划
本地模式
上传文件
解压文件
配置环境变量
配置hadoop-env.sh
测试
伪分布式
hdfs-site.xml
core-site.xml
mapred-site.xml
yarn-site.xml
格式化Namenode
启动集群
测试
全分布式
免密码登录
编辑hosts文件
配置环境变量
bigdata112配置
hadoop-env.sh
hdfs-site.xml
core-site.xml
yarn-site.xml
slaves
其他节点配置
格式化NameNode
集群时间同步
启动集群
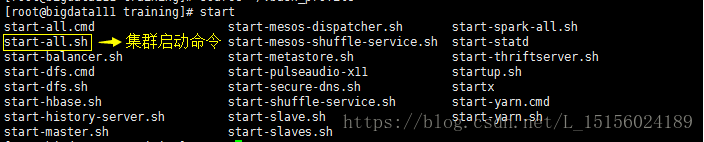
start-all.sh
UI
测试
准备
软件版本
(1)JDK1.8
jdk-8u144-linux-x64.tar.gz
(2)Hadoop
hadoop-2.7.3.tar.gz
(3)CentOS
CentOS-7-x86_64-Everything-1708.iso
安装Hadoop集群前,需要提前准备四台Linux服务器,并在每台服务器上安装和配置好JDK。其中一台用于搭建本地模式和伪分布模式,另外三台用于搭建全分布模式。
集群规划
下面搭建三种模式的Hadoop集群,各个模式的集群具体划分如下:
(1)本地模式(Local Mode)
| 主机名 | IP地址 | Hadoop节点名称 |
|---|---|---|
| bigdata111 | 192.168.189.111 | 无 |
(2)伪分布式模式(Pseudo-Distributed Mode)
| 主机名 | IP地址 | Hadoop节点名称 |
|---|---|---|
| bigdata111 | 192.168.189.111 | NameNode / SecondaryNameNode / DataNode / ResourceManager / NodeManager |
(3)全分布式模式(Fully-Distributed Mode)
| 主机名 | IP地址 | Hadoop节点名称 |
|---|---|---|
| bigdata112 | 192.168.189.112 | NameNode / SecondaryNameNode / ResourceManager |
| bigdata113 | 192.168.189.113 | DataNode / NodeManager |
| bigdata114 | 192.168.189.114 | DataNode / NodeManager |
本地模式
本地模式没有HDFS,只能测试MapReduce程序,程序运行的结果保存在本地文件系统。
上传文件
将hadoop-2.7.3.tar.gz文件上传至bigdata111服务器的/root/tools下,如图:

解压文件
在当前目录,执行如下解压命令
tar -zxvf hadoop-2.7.3.tar.gz -C ~/training/将文件解压到/root/training/目录下,如图:

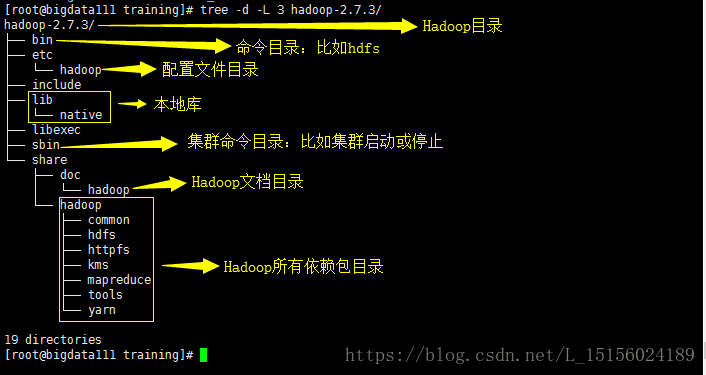
可以执行如下tree命令(需要单独安装tree-1.6.0-10.el7.x86_64.rpm)
tree -d -L 3 hadoop-2.7.3/查看hadoop的三层目录,如下:
配置环境变量
执行
vi ~/.bash_profile命令,打开环境变量配置文件,添加如下配置

保存并退出文件,再执行
source ~/.bash_profile命令,使配置生效。在命令窗口敲入start,然后按Tab键,如果出现如下界面表示配置成功:
配置hadoop-env.sh
进入Hadoop的配置文件目录,如下:
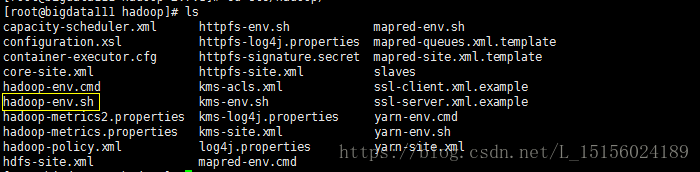
图中是Hadoop的所有配置文件。伪分布式只需要配置hadoop-env.sh,在该文件中配置JDK安装路径,如下:

保存退出文件。事实上,这里不配置JDK,也是可以的。
测试
(1)单词计数
Hadoop中为我们提供了一个单词计数的MapReduce程序,详细目录如下:

(2)执行MapReduce程序
先在/root/input目录下创建一个data.txt文件,output目录不能提前创建,然后在程序所在目录执行如下命令:
hadoop jar hadoop-mapreduce-examples-2.7.3.jar wordcount ~/input/data.txt ~/output/成功后,会在output目录下生成两个文件,结果如下:

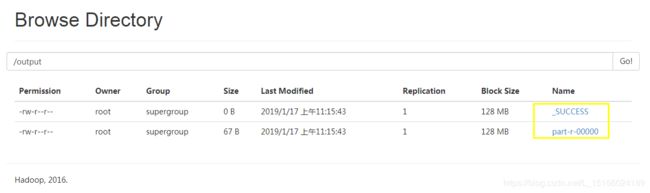
实际结果存在part-r-00000,_SUCCESS只是一个状态文件。
(3)Bug
在执行上面的MapReduce时,会出现如下的bug:
可以参见:
https://issues.apache.org/jira/browse/MAPREDUCE-6835
https://issues.apache.org/jira/browse/YARN-4322
这个bug不用太在意,实际生产环境采用全分布式模式。
注:实际上,在Hadoop本地模式中,只是将MapReduce程序作为普通的Java程序来执行,并不需要Hadoop的HDFS和Yarn支持。
伪分布式
伪分布式模式在单机上运行,模拟全分布式环境,具有Hadoop的主要功能。它在本地模式基础之上,再如下修改配置文件即可。具体配置如下:
hdfs-site.xml
dfs.replication
1
dfs.permissions
true
参数说明:
(1)dfs.replication
配置数据的副本数。因为这里是单机,所以副本数配置为1。
(2)dfs.permissions
配置HDFS的权限检查。默认是true,也就是开启权限检查。可以不配置,这里只是为了说明。
core-site.xml
fs.defaultFS
hdfs://bigdata111:9000
hadoop.tmp.dir
/root/training/hadoop-2.7.3/tmp
参数说明:
(1)fs.defaultFS
配置NameNode的地址,通信端口号是9000。bigdata111为主机名,也可以使用IP地址。
(2)hadoop.tmp.dir
配置HDFS数据保存目录,默认是Linux系统的tmp目录,而Linux系统tmp目录重启后会被删除,所以这里需要配置为本地系统的其他目录,例如Hadoop安装目录下的tmp目录。tmp目录需要用户自己创建,如图:

mapred-site.xml
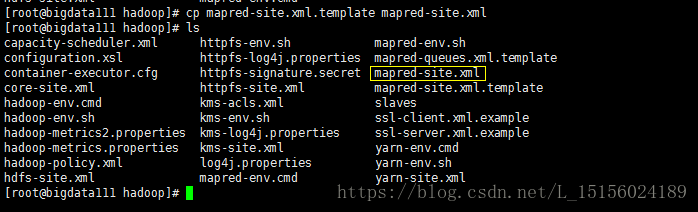
Hadoop配置文件中默认没有这个文件,只提供了模板文件mapred-site.xml.template,需要在当前目录下复制一份:
cp mapred-site.xml.template mapred-site.xml
复制成功后,如图:
具体配置内容如下:
mapreduce.framework.name
yarn
参数说明:
(1)mapreduce.framework.name
配置mapreduce程序执行的框架名称:yarn。yarn是资源管理器框架。
yarn-site.xml
yarn.resourcemanager.hostname
bigdata111
yarn.nodemanager.aux-services
mapreduce_shuffle
参数说明:
(1)yarn.resourcemanager.hostname
配置yarn的主节点ResourceManager主机名;
(2)yarn.nodemanager.aux-services
配置yarn的NodeManager运行MapReduce的方式。
格式化Namenode
执行如下命令
hdfs namenode -format格式化Namenode(实际生成格式化目录/root/training/hadoop-2.7.3/tmp)。格式化成功后,部分日志如下:
18/08/18 19:10:19 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = bigdata111/192.168.189.111
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.7.3
de4719c1c8af91ccff; compiled by 'root' on 2016-08-18T01:41ZSTARTUP_MSG: java = 1.8.0_144
************************************************************/
18/08/18 19:10:19 INFO namenode.NameNode: registered UNIX signal handlers for [TERM, HUP, INT]
18/08/18 19:10:19 INFO namenode.NameNode: createNameNode [-format]
Formatting using clusterid: CID-64debde0-a2ea-4385-baf2-18e6b2d76c74
18/08/18 19:10:21 INFO namenode.FSNamesystem: No KeyProvider found.
18/08/18 19:10:21 INFO namenode.FSNamesystem: fsLock is fair:true
18/08/18 19:10:21 INFO blockmanagement.DatanodeManager: dfs.block.invalidate.limit=1000
18/08/18 19:10:21 INFO blockmanagement.DatanodeManager: dfs.namenode.datanode.registration.ip-hostn
ame-check=true18/08/18 19:10:21 INFO blockmanagement.BlockManager: dfs.namenode.startup.delay.block.deletion.sec
is set to 000:00:00:00.00018/08/18 19:10:21 INFO blockmanagement.BlockManager: The block deletion will start around 2018 Aug
18 19:10:2118/08/18 19:10:21 INFO util.GSet: Computing capacity for map BlocksMap
18/08/18 19:10:21 INFO util.GSet: VM type = 64-bit
18/08/18 19:10:21 INFO util.GSet: 2.0% max memory 966.7 MB = 19.3 MB
18/08/18 19:10:21 INFO util.GSet: capacity = 2^21 = 2097152 entries
18/08/18 19:10:21 INFO blockmanagement.BlockManager: dfs.block.access.token.enable=false
18/08/18 19:10:21 INFO blockmanagement.BlockManager: defaultReplication = 1
18/08/18 19:10:21 INFO blockmanagement.BlockManager: maxReplication = 512
18/08/18 19:10:21 INFO blockmanagement.BlockManager: minReplication = 1
18/08/18 19:10:21 INFO blockmanagement.BlockManager: maxReplicationStreams = 2
18/08/18 19:10:21 INFO blockmanagement.BlockManager: replicationRecheckInterval = 3000
18/08/18 19:10:21 INFO blockmanagement.BlockManager: encryptDataTransfer = false
18/08/18 19:10:21 INFO blockmanagement.BlockManager: maxNumBlocksToLog = 1000
18/08/18 19:10:21 INFO namenode.FSNamesystem: fsOwner = root (auth:SIMPLE)
18/08/18 19:10:21 INFO namenode.FSNamesystem: supergroup = supergroup
18/08/18 19:10:21 INFO namenode.FSNamesystem: isPermissionEnabled = true
18/08/18 19:10:21 INFO namenode.FSNamesystem: HA Enabled: false
18/08/18 19:10:21 INFO namenode.FSNamesystem: Append Enabled: true
18/08/18 19:10:21 INFO util.GSet: Computing capacity for map INodeMap
18/08/18 19:10:21 INFO util.GSet: VM type = 64-bit
18/08/18 19:10:21 INFO util.GSet: 1.0% max memory 966.7 MB = 9.7 MB
18/08/18 19:10:21 INFO util.GSet: capacity = 2^20 = 1048576 entries
18/08/18 19:10:21 INFO namenode.FSDirectory: ACLs enabled? false
18/08/18 19:10:21 INFO namenode.FSDirectory: XAttrs enabled? true
18/08/18 19:10:21 INFO namenode.FSDirectory: Maximum size of an xattr: 16384
18/08/18 19:10:21 INFO namenode.NameNode: Caching file names occuring more than 10 times
18/08/18 19:10:21 INFO util.GSet: Computing capacity for map cachedBlocks
18/08/18 19:10:21 INFO util.GSet: VM type = 64-bit
18/08/18 19:10:21 INFO util.GSet: 0.25% max memory 966.7 MB = 2.4 MB
18/08/18 19:10:21 INFO util.GSet: capacity = 2^18 = 262144 entries
18/08/18 19:10:21 INFO namenode.FSNamesystem: dfs.namenode.safemode.threshold-pct = 0.9990000128746
03318/08/18 19:10:21 INFO namenode.FSNamesystem: dfs.namenode.safemode.min.datanodes = 0
18/08/18 19:10:21 INFO namenode.FSNamesystem: dfs.namenode.safemode.extension = 30000
18/08/18 19:10:21 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.window.num.buckets = 10
18/08/18 19:10:21 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.num.users = 10
18/08/18 19:10:21 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.windows.minutes = 1,5,25
18/08/18 19:10:21 INFO namenode.FSNamesystem: Retry cache on namenode is enabled
18/08/18 19:10:21 INFO namenode.FSNamesystem: Retry cache will use 0.03 of total heap and retry cac
he entry expiry time is 600000 millis18/08/18 19:10:21 INFO util.GSet: Computing capacity for map NameNodeRetryCache
18/08/18 19:10:21 INFO util.GSet: VM type = 64-bit
18/08/18 19:10:21 INFO util.GSet: 0.029999999329447746% max memory 966.7 MB = 297.0 KB
18/08/18 19:10:21 INFO util.GSet: capacity = 2^15 = 32768 entries
18/08/18 19:10:21 INFO namenode.FSImage: Allocated new BlockPoolId: BP-608361600-192.168.189.111-15
3459062172118/08/18 19:10:21 INFO common.Storage: Storage directory /root/training/hadoop-2.7.3/tmp/dfs/name h
as been successfully formatted.18/08/18 19:10:21 INFO namenode.FSImageFormatProtobuf: Saving image file /root/training/hadoop-2.7.
3/tmp/dfs/name/current/fsimage.ckpt_0000000000000000000 using no compression18/08/18 19:10:22 INFO namenode.FSImageFormatProtobuf: Image file /root/training/hadoop-2.7.3/tmp/d
fs/name/current/fsimage.ckpt_0000000000000000000 of size 351 bytes saved in 0 seconds.18/08/18 19:10:22 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
18/08/18 19:10:22 INFO util.ExitUtil: Exiting with status 0
18/08/18 19:10:22 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at bigdata111/192.168.189.111
************************************************************/
关键日志:
3459062172118/08/18 19:10:21 INFO common.Storage: Storage directory /root/training/hadoop-2.7.3/tmp/dfs/name h
as been successfully formatted.
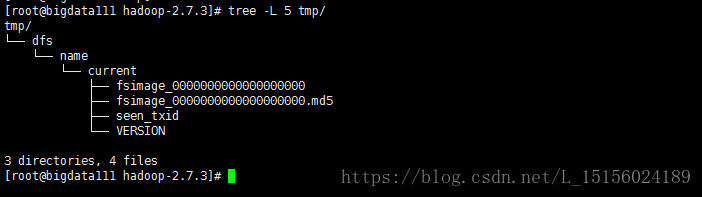
tmp目录生成的数据如下:
启动集群
(1)start-all.sh
执行start-all.sh(这个命令已经过期,可以分别执行start-dfs.sh和start-yarn.sh命令)命令,正常启动后如下:

Hadoop节点如下:
a、NameNode
b、DataNode
c、SecondaryNameNode
yarn节点如下:
a、ResourceManager
b、NodeManager
(2)UI
在浏览器中输入地址http://192.168.189.111:50070(SecondaryNameNode端口默认是50090),即可打开Hadoop管理页面,如图:

打开Utilities,查看HDFS文件系统管理页面如下

输入http://192.168.189.111:8088/cluster,打开yarn应用管理页面,如图:
测试
还是以Hadoop中提供了单词统计为例。
(1)创建数据
在本地模式中,单词统计的数据输入和输出都是在Linux本地目录,而在伪分布模式中,数据的输入和输出都是HDFS,所以需要在HDFS上准备输入数据。分别执行如下命令:
hdfs dfs -mkdir /input
hdfs dfs -put /root/input/data.txt /input在HDFS上创建input目录,将数据data.txt上传至该目录。
(2)执行MapReduce程序
在程序所在目录执行如下命令:
hadoop jar hadoop-mapreduce-examples-2.7.3.jar wordcount /input/data.txt /outputoutput目录不能提前创建,成功后,会在HDFS的/output目录下生成两个文件,结果如下:
和本地模式产生的数据是一样的,只是一个存在Linux本地目录,另一个存在HDFS上(事实上它的数据也在Linux上,具体在/root/training/hadoop-2.7.3/tmp/dfs/data/current下)。
全分布式
全分布式环境,用于生产环境。
免密码登录
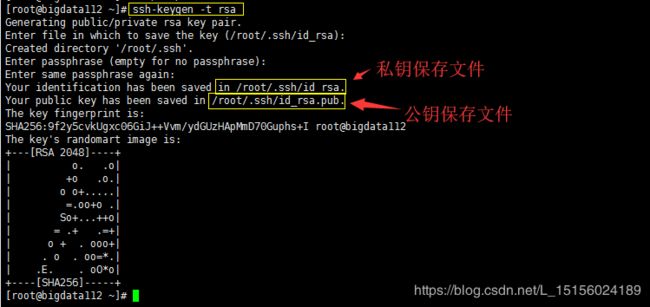
(1)生成公钥和私钥
三台服务器执行命令ssh-keygen -t rsa生成公钥和私钥,中间按Enter即可。例如在bigdata112上生成过程如下:
(2)拷贝私钥
将每台机器的私钥拷贝到其他机器(包括自己),例如在bigdata112上执行如下拷贝命令:
ssh-copy-id -i ~/.ssh/id_rsa.pub root@bigdata112将私钥拷贝给自己。拷贝好后,可以如下测试是否拷贝成功:

注意:尝试拷贝给bigdata111,如图:

结果不能解析bigdata111,原因是bigdata112的hosts文件中并没有配置bigdata111和IP地址的对应关系。
将免密码登录配置放在第一步,主要是因为免密码登录配置成功后,远程拷贝时不用再输入密码确认,非常方便。
编辑hosts文件
执行vi /etc/hosts打开主机名配置文件,配置主机名和IP地址对应关系如下:

三台服务器都需要配置。可以配置好一台,然后使用如下命令远程拷贝到其他服务器:
scp -r /etc/hosts root@bigdata113:/etc/hosts
scp -r /etc/hosts root@bigdata114:/etc/hosts
配置环境变量
三台服务器都需要配置Hadoop环境变量,参考本地模式。也可以单独配置好一台,然后远程拷贝到其他服务器(一定要使配置文件生效)。事实上,只在bigdata112节点上配置也是可以的,不过,这样只能在bigdata112上执行Hadoop命令,比如集群的启动和停止。为了管理方便,建议保持各个节点配置相同。
bigdata112配置
按照伪分布式配置,不同的配置如下:
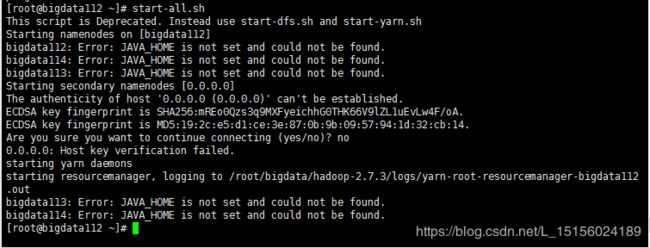
hadoop-env.sh
在本地模式下,可以不配置JDK,但是全分布式模式必须要配置,不然启动集群时,会报如下错误:
hdfs-site.xml
dfs.replication
2
dfs.permissions
true
数据副本数配置为2,默认是3,这里只有两个datanode,所以配置为2。
core-site.xml
fs.defaultFS
hdfs://bigdata112:9000
hadoop.tmp.dir
/root/training/hadoop-2.7.3/tmp
NameNode地址为bigdata112。
yarn-site.xml
yarn.resourcemanager.hostname
bigdata112
yarn.nodemanager.aux-services
mapreduce_shuffle
ResourceManager节点主机名改为bigdata112。
slaves
salvas配置文件内容如下:

其他节点配置
将bigdata112的hadoop目录远程拷贝到bigdata113和bigdata114上,命令如下:
scp -r hadoop-2.7.3/ root@bigdata113:/root/training
scp -r hadoop-2.7.3/ root@bigdata114:/root/training格式化NameNode
这里与伪分布模式相同。成功后,如图:
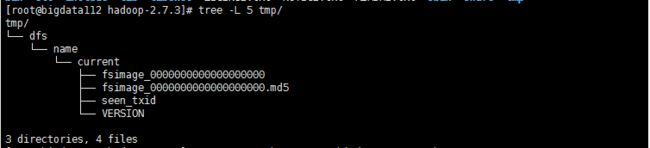
这一步放在最后。主要是因为如果放在上一步之前,那么会在每个节点上都有tmp/name目录。正常情况下,bigdata112上tmp目录下有name和namesecondary两个目录,如图:
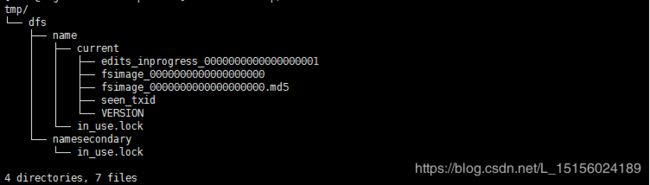
bigdata113和114,tmp目录结构如图:

集群时间同步
安装ntp服务。暂略,以后补上。
启动集群
start-all.sh
在bigdata112上执行集群启动命令start-all.sh,成功后,如图:



可能出现下图中的情况:
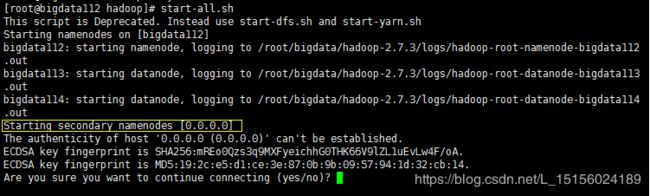

原因是bigdata112上生成的公钥忘了拷贝给自己,重新在bigdata112上生成密钥,然后拷贝到各个服务器(包括自己)。
UI
在浏览器中输入http://192.168.189.112:50070打开Hadoop管理页面,如下:
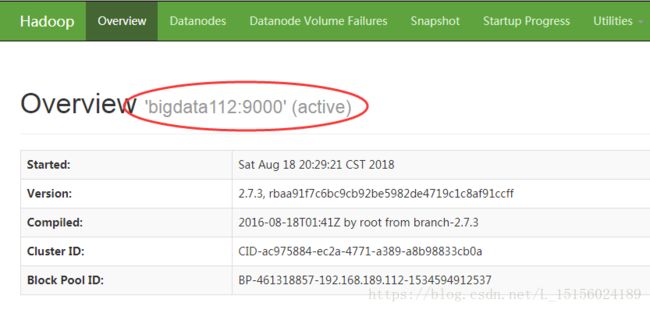
打开Utilities,查看HDFS文件系统管理页面如下
输入http://192.168.189.112:8088,打开yarn应用管理页面如下:

测试
与伪分布相同,执行MapReduce程序。略。