改变世界的9大算法--搜索引擎索引
搜索有两个主要阶段:匹配和排名。搜索引擎将二者组合成一个流程以实现一致性。但是这两个在概念上是独立的,我们假设在排名之前已经完成了匹配。
并且一个搜索引擎的生死由其排名的质量决定。
还是老规则,问题三部曲。是什么?为什么?怎么办?
首先来回答一下是什么?
什么是匹配?
假设我现在搜索的是“伦敦公共汽车时刻表”,那么匹配就是搜索整个互联网中包含该字段的网页。匹配阶段也就是回答了“哪个网页与我的查询匹配”。
具体实例见下图:

其次说说为什么匹配?
为一个给出的查询高效地找出所有命中问题。
最后说说怎么匹配?
在说到怎么匹配之前,先来了解一下,什么是索引?
“索引”这个词通常指参考书的最后一个版块。你可能查找所要的概念以固定顺序(通常按字母排序)排列,每一个概念下都列出的具体出现的位置(通常以页码形式出现)。
就像是“cat 124, 523”的索引项。意味着“cat”这个词在第124,页和第523页中出现过。
下面给出三张图,假设这三张图片就是互联网上的三个网页。
1. 2.
2. 3.
3.
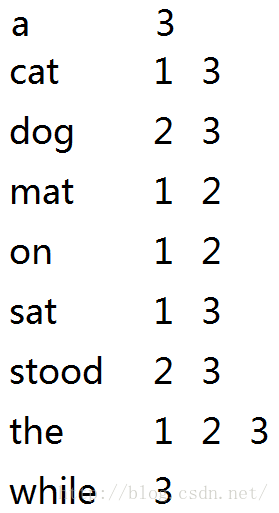
一个用页码表示的简单索引表
a--表示在第3张表中出现
the---表示在第1、2、3张表中出现
以此类推。
在搜索cat 、dog、 while等单词时,搜索引擎可以很快的查找到,但是在实际所搜中,却很难一个词搜索,往往事词语或词组搜索,假设我现在要搜索的是cat sat和“cat sat”.
(注意:这里有无引号的区别)。首先看第一项,搜索引擎很快就搜索到cat和sat在第1、3页出现了。现在搜索第二项,那么搜索引擎首先会搜索含有cat 和sat的页面,这里出现在第1页和第3页,但此时,搜索就卡住了,它不知道具体的顺序是如何?谁在前谁在后?
如何解决这个问题?利用“词把戏”解决。
解决思路:索引不单单只存储页码,还要存储页面内的位置。位置:它们代表了一个词在页面中的位置。比如:第3个词的位置是3,第29个词的位置是29.
那么将以上的三个图以及索引表改为:
1 2
2 3
3

a--表示在第3页第5个位置
cat--表示在第1页第2个位置,第3页第2个位置
以此类推。
那么我们开始寻找词语“cat sat”,通过查看索引信息("cat":位置:1-2 3-2, “sat”:位置:1-3 3-7)(注意:这里是查看索引就知道位置,而不用查看原始网页)
那么,3-2=1,7-2=5.便知道了"cat sat"之间连在一起的词是在第1个网页。
“词把戏”解决的不仅是短语查询之间的搜索,而且是相邻词语搜索的重要手段之一。一般在查询相邻词五个相邻位置左右。
讲完匹配之后,再来说说排名。
还是一样,首先解决的是,什么是排名?生活中很多例子,考试排名第一,体侧排名最后等等,和生活中的事例一样,只不过互联网中的排名我们看不到而已(这里指普通用户)。
其次解决为什么要排名?挑选出前几个命中并展示给用户的阶段。“排名”对于一个高质量的搜索引擎的绝对不可少的。
怎么排名?其实也就是,排名取决于什么?
真正的问题不是“这个网页和查询匹配吗”,而是“这个网页和查询是否相关”。这里用“相关度”来描述网页与查询相关的紧密程度。
还是用例子来说明:
1. 2.
2.

假设现在查询的是 cause malaria(导致疟疾),那么1.中是导致疟疾的相关原因,但是2.中只是恰巧有cause和malaria,但是两个网页都同时命中了,这时候,搜索引擎该怎么分辨出,那个是我们所需要的?
解决方案:“原词把戏”
要想搜索引擎一样分析网页结构。网页结构是以HTML来编写的,包含着大量的标签(tag),那么通过分析这些标签到做到搜索。
那么为什么所要分析网页结构来达到我们的目的。
因为文章的标题。往往一篇文章的标题便是这篇文章的中心大意以及标题的文字往往是我们要搜索的内容,这比起在文章中偶尔出现一两个单词更具有搜索价值。
还是以匹配阶段举得例子为例:



其他类推。。
假如现在我要查询dog在标题中的网页,那么该如何做呢?
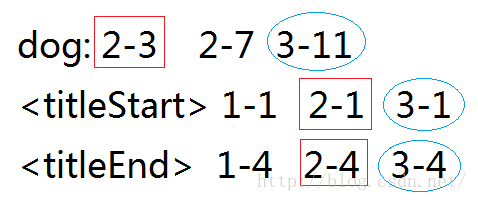
找到了
那么搜索引擎便会查找以“1-”开头的索引,在start以及end之间的便是我们要查找的内容。
例如:1-1 1-4,再搜索dog中的索引,没有“1-”开头的,那么继续往下搜索索引值,2-1 2-4 ,再搜索dog中,发现有“2-"开头,那么判断"2-?"中的?是否在 1 注意的是:搜索引擎每次都只是查询小部分索引项,就能回应查询,并且搜索引擎只需遍历每个索引项一次。 索引和匹配并非是全部内容,下一篇将会带来PageRank算法--让谷歌腾飞的技术。 http://blog.csdn.net/l_rollback/article/details/52764861