决策树原理及实战代码
目录
1 定义
2 基本流程
3 划分选择
3.1 信息增益(ID3)
3.2 增益率(C4.5)
3.3 基尼系数(CART)
4 剪枝处理
4.1 预剪枝
4.2 后剪枝
5 多变量决策树
6 决策树优缺点
6.1 优点
6.2 缺点
7 代码实践
1 定义
决策树是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法。由于这种决策分支画成图形很像一棵树的枝干,故称决策树。在机器学习中,决策树是一个预测模型,他代表的是对象属性与对象值之间的一种映射关系。Entropy = 系统的凌乱程度,使用算法ID3、C4.5和C5.0生成树算法使用熵。这一度量是基于信息学理论中熵的概念。
举个例子,我们要对“这是好瓜吗”这个问题进行决策时,通常会进行一系列子决策:通过色泽、根蒂、敲声等方式进行判断,最终得出结论是否为好瓜,这个过程即可以看作一个决策树运行的过程。

2 基本流程
决策树通常有三个步骤:特征选择、决策树的生成、决策树的修剪。
一个决策树包含了一个根节点,若干个内部节点和若干个叶节点。用决策树分类时,从根节点开始,对实例的某一特征进行测试,根据测试结果将实例分配到其子节点,此时每个子节点对应着该特征的一个取值,如此递归的对实例进行测试并分配,直到到达叶节点,最后将实例分到叶节点的类中。
下图为决策树示意图,圆点——内部节点,方框——叶节点。

此图采用博客https://blog.csdn.net/jiaoyangwm/article/details/79525237中的图
决策树学习的目的是为了产生一棵泛化能力强,即处理未见实例能力强的决策树,其基本流程遵循简单且直观的“分而治之”的思想 。决策树算法的伪码如下图所示。

3 划分选择
在选择每一步的特征值时,如何对特征选择的先后进行判断呢?以判断西瓜好坏为例子,图4-1中以“色泽-根蒂-敲声”的顺序进行判断,那可不可以以“敲声-色泽-根蒂”的顺序进行判断呢?这里提供三种划分选择的方式。
3.1 信息增益(ID3)
这里引入熵的概念。“信息熵”是度量样本集合纯度的最常用的一种指标。假定当前样本集合D中第k类样本所占比例为pk,则样本集合D的信息熵定义为:

Ent(D)的值越小,D的纯度越高。
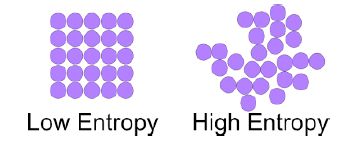
上图当中,左图比右图熵值低。可见,无序熵值高于有序熵值。这里可以类比高中化学当中对熵的定义。越无序熵值越大,越有序熵值越低。
假定通过属性划分样本集D,产生了V个分支节点,v表示其中第v个分支节点,易知:分支节点包含的样本数越多,表示该分支节点的影响力越大。故可以计算出划分后相比原始数据集D获得的“信息增益”(information gain)。

一般而言,信息增益越大,则意味着该属性来进行划分所获得的“纯度提升”越大。因此,使用信息增益进行属性划分,就是找寻信息增益较大的节点作为每一层的“根节点”。下图为使用信息增益进行属性划分的例子。
 3.2 增益率(C4.5)
3.2 增益率(C4.5)
在上面例子当中,我们有意忽略了“编号”这一属性。如果把编号也当作一个属性,每个分支结点的纯度都达到最大,但是决策树明显不具有泛化能力,无法对新样本进行有效预测。
实际上,信息增益准则对可取值数目较多的属性有偏好,为减少这种偏好可能带来的不利影响,可以使用增益率来进行划分。
信息增益比是特征A对训练数据集D的信息增益比![]() 定义为其信息增益
定义为其信息增益![]() 与训练数据集D关于特征A的值的熵
与训练数据集D关于特征A的值的熵![]() 之比,即
之比,即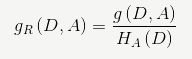 其中,
其中, ,n是特征A取值的个数。
,n是特征A取值的个数。
需要注意的是:增益率准则对可取值数目较少的属性有所偏好,因此,C4.5算法不是直接选择增益率大的候选划分属性,而是先从候选划分属性中找出信息增益高于平均水平的属性,再从中选择增益率高的。
3.3 基尼系数(CART)
CART分类算法是根据基尼(Gini)系数来选择测试属性,Gini系数的值越小,划分效果越好。设样本集合为D,则D的Gini系数值可由公式计算:
直观来说,Gini(D)反映了从数据集D中随机抽取两个样本,其类别标记不一致的概率。因此,Gini(D)越小,数据集D的纯度越高。
与上式相同,属性a的基尼指数定义为:

于是在候选属性集合A中,我们选择使得划分后基尼指数最小的属性作为最优划分属性。
4 剪枝处理
决策树生成算法递归的产生决策树,直到不能继续下去为止,这样产生的树往往对训练数据的分类很准确,但对未知测试数据的分类缺没有那么精确,即会出现过拟合现象。过拟合产生的原因在于在学习时过多的考虑如何提高对训练数据的正确分类,从而构建出过于复杂的决策树,解决方法是考虑决策树的复杂度,对已经生成的树进行简化。
剪枝(pruning):从已经生成的树上裁掉一些子树或叶节点,并将其根节点或父节点作为新的叶子节点,从而简化分类树模型。剪枝分为预剪枝与后剪枝。
4.1 预剪枝
预剪枝是指在决策树的生成过程中,对每个节点在划分前先进行评估,若当前的划分不能带来泛化性能的提升,则停止划分,并将当前节点标记为叶节点。

优点:预剪枝处理使得决策树的很多分支被剪掉,因此大大降低了训练时间开销,同时降低了过拟合的风险。
缺点:但另一方面由于剪枝同时剪掉了当前节点后续子节点的分支,因此预剪枝“贪心”的本质阻止了分支的展开,在一定程度上带来了欠拟合的风险。
4.2 后剪枝
后剪枝是指先从训练集生成一颗完整的决策树,然后自底向上对非叶节点进行考察,若将该节点对应的子树替换为叶节点,能带来泛化性能的提升,则将该子树替换为叶节点。
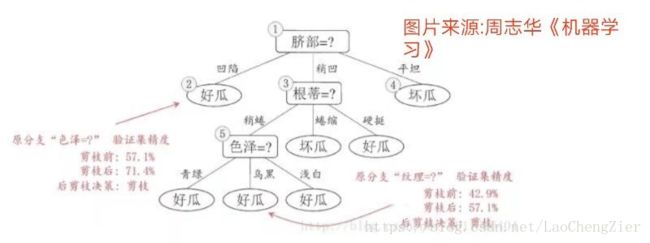
优点:后剪枝则通常保留了更多的分支,因此采用后剪枝策略的决策树性能往往优于预剪枝。
缺点:但其自底向上遍历了所有节点,并计算性能,训练时间开销相比预剪枝大大提升。
5 多变量决策树
决策树所形成的分类边界有一个明显的特点:轴平行(axis-parallel),即它的分类边界由若干个与坐标轴平行的分段组成。“多变量决策树”(multivariate decision tree)能实现“斜划分”甚至更复杂划分的决策树。
与传统的“单变量决策树”(univariate decision tree)不同,在多变量决策树的学习过程中,不是为每个非叶结点寻找一个最优划分属性,而是试图建立一个合适的线性分类器。
典型算法:OC1、“感知机树”等。
这里特别要说的是,周志华教授提出了多粒度级联森林GCForest,提出了替代深度学习的可能性,文章地址为https://arxiv.org/abs/1702.08835v2。
6 决策树优缺点
6.1 优点
- 容易解释,容易可视化;
- 无需对特征进行归一化处理;
- 可以用于混合型特征的数据集(连续性特征、类别性特征等)。
6.2 缺点
- 剪枝后也很难避免过拟合;
- 通常需要ensemble才能达到很好的效果(如随机森林等)。
7 代码实践
#scikit-learn中决策树的重要参数
#max_depth:树的最大深度(分割点个数),最常用的用于减少模型复杂度防止过拟合的参数
#min_sample_leaf:每个叶子拥有的最少样本个数
#max_leaf_nodes:树中叶子的最大个数
#实际应用中,通常只需要调整max_depth就已经足够防止决策树模型的过拟合这里一个非常简单的小demo,使用的鸢尾花的数据集。
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
#下载数据集
iris = load_iris()
#划分数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=0)
#设置树的最大深度控制树的复杂度
max_depth_values = [2, 3, 4]
for max_depth_val in max_depth_values:
dt_model = DecisionTreeClassifier(max_depth=max_depth_val)
dt_model.fit(X_train, y_train)
print('max_depth=', max_depth_val)
print('训练集上的准确率: {:.3f}'.format(dt_model.score(X_train, y_train)))
print('测试集的准确率: {:.3f}'.format(dt_model.score(X_test, y_test)))
print()所得预测结果如下:
