RCNN系列学习记录
一、RCNN

第一阶段 分类
1)selective search 选择2000个候选区域2)对于每一个region proposal 都wrap到固定的大小的scale,227*227(AlexNet Input)
3)对于每一个处理之后的图片,把他都放到CNN上去进行特征提取,得到每个region proposal的feature map,这些特征用固定长度的特征集合feature vector来表示。最后对于每一个类别,我们都会得到很多的feature vector。
4)把这些特征向量直接放到svm现行分类器去判断,每个region 都会给出所对应的score。打分是指region proposals对于各个类别的分数。
第二阶段 边缘检测
用非极大值抑制canny来进行边缘检测非极大值抑制(NMS)先计算出每一个bounding box的面积,然后根据score进行排序,把score最大的bounding box作为选定的框,计算其余bounding box与当前最大score与box的IoU,去除IoU大于设定的阈值的bounding box。然后重复上面的过程,直至候选bounding box为空,然后再将score小于一定阈值的选定框删除得到一类的结果
总结:
1)首先需要在AlexNet上进行分类的训练model,得到AlexNet之后才能进行分类(Pretrained procedure->SoftMax2SVM)。2)分类之后再改一下AxlexNet model (fc: 1000->21)得到detection model(training)->(testing),然后在上面利用SVM进行二分类判断当前的region有没有包含我们需要的物体
3)(对结果进行排序,取前面的IOU最大的那几个(nms),在对这些进行canny边缘检测,才可以得到bounding-box(then B-BoxRegression)。
二、SSP-NET
CNN网络需要固定尺寸的图像输入,SPPNet将任意大小的图像池化生成固定长度的图像表示。事实上,CNN的卷积层不需要固定尺寸的图像,全连接层是需要固定大小输入的,因此提出了SPP层放到卷积层的后面。
如果像上图那样将reponse map分成4x4 2x2 1x1三张子图,做max pooling后,出来的特征就是固定长度的(16+4+1)x256那么多的维度了。
如果原图的输入不是224x224,出来的特征依然是(16+4+1)x256
SPP层其实就说一个特殊的池化层。空间金字塔最大池化的过程,其实就是从这21个图片块中,分别计算每个块的最大值,从而得到一个输出神经元。最后把一张任意大小的图片转换成了一个固定大小的21维特征(当然你可以设计其它维数的输出,增加金字塔的层数,或者改变划分网格的大小)。上面的三种不同刻度的划分,每一种刻度我们称之为:金字塔的一层,每一个图片块大小我们称之为:windows size了。如果你希望,金字塔的某一层输出n*n个特征,那么你就要用windows size大小为:(w/n,h/n)进行池化了。
关键机制:如何将图像的ROI映射到feature map
原图的某个区域就可以通过除以网络的所有stride来映射到conv5后去区域缺点
SPP中的微调只更新spp层后面的全连接层,对很深的网络这样肯定是不行的。
三、Fast-RCNN
与RCNN对比改进
1. 比R-CNN更高的检测质量(mAP);2. 把多个任务的损失函数写到一起,实现单级的训练过程;
训练的时候,pipeline是隔离的,先提proposal,然后CNN提取特征,之后用SVM分类器,最后再做bbox regression。FRCN实现了end-to-end的joint training(提proposal阶段除外)
3. 在训练时可更新所有的层;
RCNN中ROI-centric的运算开销大,所以FRCN用了image-centric的训练方式来通过卷积的share特性来降低运算开销;
FRCN进一步通过single scale(pooling->spp just for one scale) testing和SVD(降维)分解全连接来提速。
4. 不需要在磁盘中存储特征。
RCNN提取特征给SVM训练时候需要中间要大量的磁盘空间存放特征,FRCN去掉了SVM这一步,所有的特征都暂存在显存中,就不需要额外的磁盘空间了
与SPP对比
对比回来SPP-Net,可以看出FRCN大致就是一个joint training版本的SPP-Net,改进如下:1.改进了SPP-Net在实现上无法同时tuning在SPP layer两边的卷积层和全连接层
2.SPP-Net后面的需要将第二层FC的特征放到硬盘上训练SVM,之后再额外训练bbox regressor
整体框架
如果以AlexNet(5个卷积和3个全连接)为例,大致的训练过程可以理解为:1.selective search在一张图片中得到约2k个object proposal(这里称为RoI)
2.缩放图片的scale得到图片金字塔,FP得到conv5的特征金字塔。
3.对于每个scale的每个ROI,求取映射关系,在conv5中crop出对应的patch。并用一个单层的SPP layer(这里称为Rol pooling layer)来统一到一样的尺度(对于AlexNet是6x6)。
4.继续经过两个全连接得到特征,这特征有分别share到两个新的全连接,连接上两个优化目标。第一个优化目标是分类,使用softmax,第二个优化目标是bbox regression,使用了一个smooth的L1-loss.
(除了1,上面的2-4是joint training的。测试时候,在4之后做一个NMS即可。)
Rol pooling layer
Rol pooling layer的作用主要有两个:
1.是将image中的rol定位到feature map中对应patch
2.是用一个单层的SPP layer将这个feature map patch下采样为大小固定的feature再传入全连接层。即
RoI pooling layer来统一到相同的大小-> (fc)feature vector 即->提取一个固定维度的特征表示。
RoI-centric sampling与image-centric sampling
RoI-centric sampling:从所有图片的所有RoI中均匀取样,这样每个SGD的mini-batch中包含了不同图像中的样本。(SPPnet采用)image-centric sampling: (solution)mini-batch采用层次取样,先对图像取样,再对RoI取样,同一图像的RoI共享计算和内存。
四、Faster-RCNN
从RCNN到fast RCNN,再到本文的faster RCNN,目标检测的四个基本步骤(候选区域生成,特征提取,分类,位置精修)终于被统一到一个深度网络框架之内。所有计算没有重复,完全在GPU中完成,大大提高了运行速度。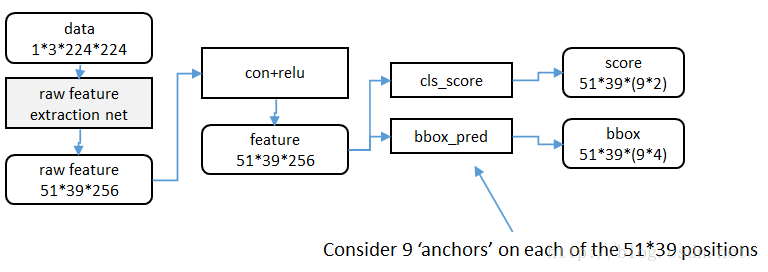
faster RCNN可以简单地看做“区域生成网络+fast RCNN“的系统,用区域生成网络代替fast RCNN中的Selective Search方法。本篇论文着重解决了这个系统中的三个问题:
1. 如何设计区域生成网络
2. 如何训练区域生成网络
3. 如何让区域生成网络和fast RCNN网络共享特征提取网络
个人理解
RPN网络是从fast-rcnn变化出来的,fast-rcnn需要Selective Search方法提供候选区域,如果我们
先用某种机制选出候选区域,尽管这个机制选出来的候选区域不太准确,但经过RPN网络的bbox regression输出后会精准许多,特别是RPN网络经过训练后(轮流训练或者联合训练)。这个机制在文章中就是在conv5层中的feature map的每一个点都反映射到原图中,作为候选区域的中心点,然后3*3滑动窗口中的9种anchors是候选区域的大小和比例,这样就确定了初始给出的候选区域了。候选区域包含边界的或者与grouth truth的IOU小于thresh的都要去掉。
区域生成网络:训练
样本
考察训练集中的每张图像:a. 对每个标定的真值候选区域,与其重叠比例最大的anchor记为前景样本
b. 对a)剩余的anchor,如果其与某个标定重叠比例大于0.7,记为前景样本;如果其与任意一个标定的重叠比例都小于0.3,记为背景样本
c. 对a),b)剩余的anchor,弃去不用。
d. 跨越图像边界的anchor弃去不用
代价函数
同时最小化两种代价:a. 分类误差
b. 前景样本的窗口位置偏差
超参数
原始特征提取网络使用ImageNet的分类样本初始化,其余新增层随机初始化。每个mini-batch包含从一张图像中提取的256个anchor,前景背景样本1:1.
前60K迭代,学习率0.001,后20K迭代,学习率0.0001。
momentum设置为0.9,weight decay设置为0.0005。
共享特征
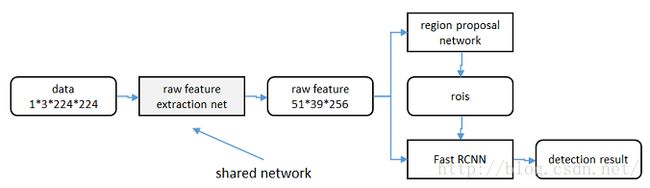
区域生成网络(RPN)和fast RCNN都需要一个原始特征提取网络(下图灰色方框)。这个网络使用ImageNet的分类库得到初始参数W0,但要如何精调参数,使其同时满足两方的需求呢?本文讲解了三种方法。
轮流训练
a. 从W0开始,训练RPN。用RPN提取训练集上的候选区域b. 从W0开始,用候选区域训练Fast RCNN,参数记为W1
c. 从W1开始,训练RPN…
具体操作时,仅执行两次迭代,并在训练时冻结了部分层。论文中的实验使用此方法。
如Ross Girshick在ICCV 15年的讲座Training R-CNNs of various velocities中所述,采用此方法没有什么根本原因,主要是因为”实现问题,以及截稿日期“。
近似联合训练
直接在上图结构上训练。在backward计算梯度时,把提取的ROI区域当做固定值看待;在backward更新参数时,来自RPN和来自Fast RCNN的增量合并输入原始特征提取层。
此方法和前方法效果类似,但能将训练时间减少20%-25%。公布的python代码中包含此方法。
联合训练
直接在上图结构上训练。但在backward计算梯度时,要考虑ROI区域的变化的影响。推导超出本文范畴,请参看15年NIP论文。