RabbitMQ的特性及概念
一、背景
RabbitMQ是一个由erlang开发的AMQP(Advanced Message Queue )的开源实现。AMQP 的出现其实也是应了广大人民群众的需求,虽然在同步消息通讯的世界里有很多公开标准(如 COBAR的 IIOP ,或者是 SOAP 等),但是在异步消息处理中却不是这样,只有大企业有一些商业实现(如微软的 MSMQ ,IBM 的 Websphere MQ 等),因此,在 2006 年的 6 月,Cisco 、Redhat、iMatix 等联合制定了 AMQP 的公开标准。
RabbitMQ是由RabbitMQ Technologies Ltd开发并且提供商业支持的。该公司在2010年4月被SpringSource(VMWare的一个部门)收购。在2013年5月被并入Pivotal。其实VMWare,Pivotal和EMC本质上是一家的。不同的是VMWare是独立上市子公司,而Pivotal是整合了EMC的某些资源,现在并没有上市。
RabbitMQ的官网是http://www.rabbitmq.com
二、基础概念
讲解基础概念的前面,我们先来整体构造一个结构图,这样会方便们更好地去理解RabbitMQ的基本原理。
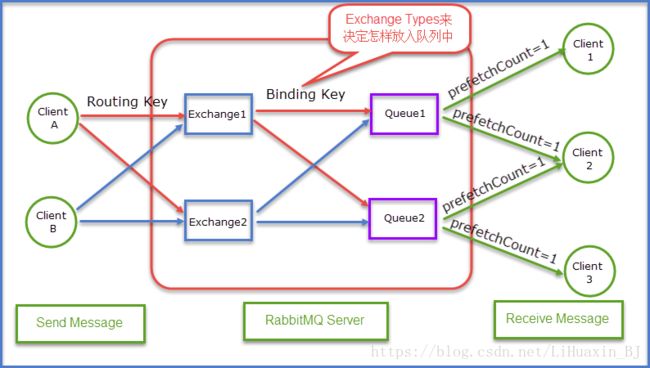
通过上面这张应用相结合的结构图既能够清晰的看清楚整体的send Message到Receive Message的一个大致的流程。当然上面有很多名词都相比还没有介绍到,不要着急接下来我们就开始对其进行详细的讲解。

Queue
Queue(队列)RabbitMQ的作用是存储消息,队列的特性是先进先出。上图可以清晰地看到Client A和Client B是生产者,生产者生产消息最终被送到RabbitMQ的内部对象Queue中去,而消费者则是从Queue队列中取出数据。可以简化成表示为:
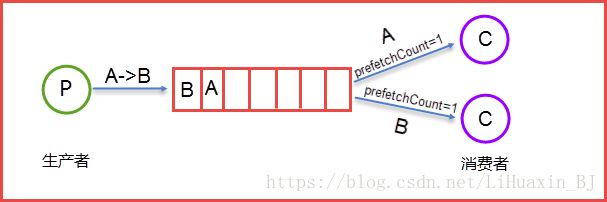
生产者Send Message “A”被传送到Queue中,消费者发现消息队列Queue中有订阅的消息,就会将这条消息A读取出来进行一些列的业务操作。这里只是一个消费正对应一个队列Queue,也可以多个消费者订阅同一个队列Queue,当然这里就会将Queue里面的消息平分给其他的消费者,但是会存在一个一个问题就是如果每个消息的处理时间不同,就会导致某些消费者一直在忙碌中,而有的消费者处理完了消息后一直处于空闲状态,因为前面已经提及到了Queue会平分这些消息给相应的消费者。这里我们就可以使用prefetchCount来限制每次发送给消费者消息的个数。详情见下图所示:
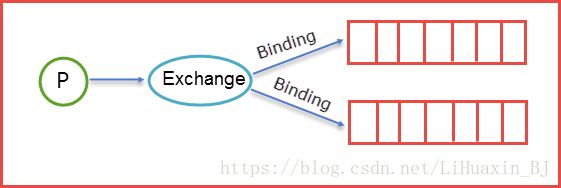
这里的prefetchCount=1是指每次从Queue中发送一条消息来。等消费者处理完这条消息后Queue会再发送一条消息给消费者。
Exchange
我们在开篇的时候就留了一个坑,就是那个应用结构图里面,消费者Client A和消费者Client B是如何知道我发送的消息是给Queue1还是给Queue2,有没有过这个问题,那么我们就来解开这个面纱,看看到底是个什么构造。首先明确一点就是生产者产生的消息并不是直接发送给消息队列Queue的,而是要经过Exchange(交换器),由Exchange再将消息路由到一个或多个Queue,当然这里还会对不符合路由规则的消息进行丢弃掉,这里指的是后续要谈到的Exchange Type。那么Exchange是怎样将消息准确的推送到对应的Queue的呢?那么这里的功劳最大的当属Binding,RabbitMQ是通过Binding将Exchange和Queue链接在一起,这样Exchange就知道如何将消息准确的推送到Queue中去。简单示意图如下所示:
在绑定(Binding)Exchange和Queue的同时,一般会指定一个Binding Key,生产者将消息发送给Exchange的时候,一般会产生一个Routing Key,当Routing Key和Binding Key对应上的时候,消息就会发送到对应的Queue中去。那么Exchange有四种类型,不同的类型有着不同的策略。也就是表明不同的类型将决定绑定的Queue不同,换言之就是说生产者发送了一个消息,Routing Key的规则是A,那么生产者会将Routing Key=A的消息推送到Exchange中,这时候Exchange中会有自己的规则,对应的规则去筛选生产者发来的消息,如果能够对应上Exchange的内部规则就将消息推送到对应的Queue中去。那么接下来就来详细讲解下Exchange里面类型。
Exchange Type
我来用表格来描述下类型以及类型之间的区别。
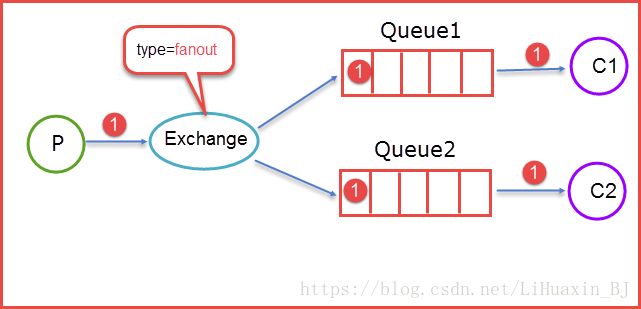
fanout
fanout类型的Exchange路由规则非常简单,它会把所有发送到该Exchange的消息路由到所有与它绑定的Queue中。
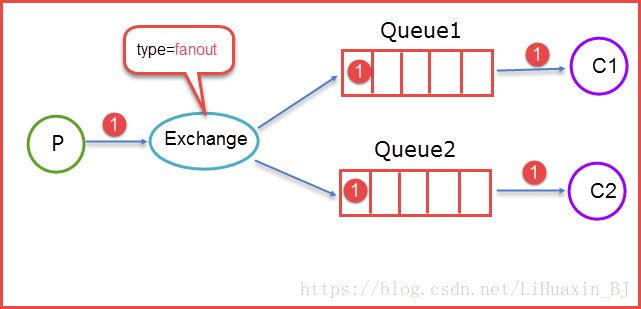
上图所示,生产者(P)生产消息1将消息1推送到Exchange,由于Exchange Type=fanout这时候会遵循fanout的规则将消息推送到所有与它绑定Queue,也就是图上的两个Queue最后两个消费者消费。
direct
direct类型的Exchange路由规则也很简单,它会把消息路由到那些binding key与routing key完全匹配的Queue中
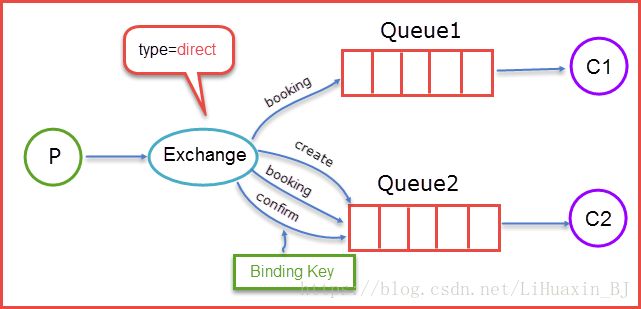
当生产者(P)发送消息时Rotuing key=booking时,这时候将消息传送给Exchange,Exchange获取到生产者发送过来消息后,会根据自身的规则进行与匹配相应的Queue,这时发现Queue1和Queue2都符合,就会将消息传送给这两个队列,如果我们以Rotuing key=create和Rotuing key=confirm发送消息时,这时消息只会被推送到Queue2队列中,其他Routing Key的消息将会被丢弃。
topic
前面提到的direct规则是严格意义上的匹配,换言之Routing Key必须与Binding Key相匹配的时候才将消息传送给Queue,那么topic这个规则就是模糊匹配,可以通过通配符满足一部分规则就可以传送。它的约定是:
routing key为一个句点号“. ”分隔的字符串(我们将被句点号“. ”分隔开的每一段独立的字符串称为一个单词),如“stock.usd.nyse”、“nyse.vmw”、“quick.orange.rabbit” binding key与routing key一样也是句点号“. ”分隔的字符串 binding key中可以存在两种特殊字符“*”与“#”,用于做模糊匹配,其中“*”用于匹配一个单词,“#”用于匹配多个单词(可以是零个)

当生产者发送消息Routing Key=F.C.E的时候,这时候只满足Queue1,所以会被路由到Queue中,如果Routing Key=A.C.E这时候会被同是路由到Queue1和Queue2中,如果Routing Key=A.F.B时,这里只会发送一条消息到Queue2中。
headers
headers类型的Exchange不依赖于routing key与binding key的匹配规则来路由消息,而是根据发送的消息内容中的headers属性进行匹配。
在绑定Queue与Exchange时指定一组键值对;当消息发送到Exchange时,RabbitMQ会取到该消息的headers(也是一个键值对的形式),对比其中的键值对是否完全匹配Queue与Exchange绑定时指定的键值对;如果完全匹配则消息会路由到该Queue,否则不会路由到该Queue。
该类型的Exchange没有用到过(不过也应该很有用武之地),所以不做介绍。
这里在对其进行简要的表格整理:
| 类型名称 |
类型描述 |
| fanout |
把所有发送到该Exchange的消息路由到所有与它绑定的Queue中 |
| direct |
Routing Key==Binding Key |
| topic |
我这里自己总结的简称模糊匹配 |
| headers |
Exchange不依赖于routing key与binding key的匹配规则来路由消息,而是根据发送的消息内容中的headers属性进行匹配。 |
补充说明:
ConnectionFactory、Connection、Channel
ConnectionFactory、Connection、Channel都是RabbitMQ对外提供的API中最基本的对象。Connection是RabbitMQ的socket链接,它封装了socket协议相关部分逻辑。ConnectionFactory为Connection的制造工厂。
Channel是我们与RabbitMQ打交道的最重要的一个接口,我们大部分的业务操作是在Channel这个接口中完成的,包括定义Queue、定义Exchange、绑定Queue与Exchange、发布消息等。
Connection就是建立一个TCP连接,生产者和消费者的都是通过TCP的连接到RabbitMQ Server中的,这个后续会再程序中体现出来。
Channel虚拟连接,建立在上面TCP连接的基础上,数据流动都是通过Channel来进行的。为什么不是直接建立在TCP的基础上进行数据流动呢?如果建立在TCP的基础上进行数据流动,建立和关闭TCP连接有代价。频繁的建立关闭TCP连接对于系统的性能有很大的影响,而且TCP的连接数也有限制,这也限制了系统处理高并发的能力。但是,在TCP连接中建立Channel是没有上述代价的。
三、特性
1、信息确认
RabbitMQ有两种应答模式,自动和手动。这也是AMQP协议所推荐的。这在point-to-point和broadcast都是一样的。
自动应答-当RabbitMQ把消息发送到接收端,接收端把消息出队列的时候就自动帮你发应答消息给服务。
手动应答-需要我们开发人员手动去调用ack方法去告诉服务已经收到。
文档推荐在大数据传输中,如果对个别消息的丢失不是很敏感的话选用自动应答比较理想,而对于那些一个消息都不能丢的场景,需要选用手动应答,也就是说在正确处理完以后才应答。如果选择了自动应答,那么消息重发这个功能就没有了。
点对点模式:也就是一发一接的模式,不适用发布/订阅这种广播模式
//autoAck 设置false,消费端挂掉,信息不会丢失,server会re-queue
channel.basicConsume(TASK_QUEUE_NAME, false, consumer);
//向服务器发送应答
channel.basicAck(envelope.getDeliveryTag(), false);在RabbitMQ中,为了不让消息丢失,它提供了消息应答的概念。当消费者获取到了一个消息以后,需要给RabbitMQ服务一个应答的消息,告知服务我已经收到或正确处理了该消息。那么RabbitMQ可以放心的在队列中删除该消息。
2、队列持久化
//durable 设置true,queue持久化,server重启,此queue不丢失
channel.queueDeclare(TASK_QUEUE_NAME, true, false, false, null);方法的第四的参数autoDelete,一般都会输入false。文档描述这个参数如果是true的话,意思是:如果这个queue不再使用(没有被订阅)的话,server就会删除它。在我的测试过程中,只要是连接改queue的所有接收者都断开连接的话,该queue就会被删除,即使里面还有没有处理的消息。RabbitMQ的重启也同样会删除他们。如果输入的是false,那与之相连的客户端都断开连接的话,服务是不会删除这个队列的,队列中的消息也就会存在。发送端在没有客户端连接的时候也可以把消息放入改队列,客户端起来的时候,就会得到这些消息。但是如果RabbitMQ服务重启的话,该队列就没有了,里面的消息自然也就没有了。
第三个参数是exclusive,文档描述说,如果是true,那么申明这个queue的connection断了,那么这个队列就被删除了,包括里面的消息。
第二个参数durable,文档描述说,如果是true,则代表是一个持久的队列,那么在服务重启后,也会存在。因为服务会把持久化的queue存放在硬盘上,放服务重启的时候,会重新申明这个queue。当然必须是在autoDelete和exclusive都为false的时候。队列是可以被持久化,但是里面的消息是否为持久化那还要看消息的持久化设置。也就是说,如果重启之前那个queue里面还有没有发出去的消息的话,重启之后那队列里面是不是还存在原来的消息,这个就要取决于发送者在发送消息时对消息的设置了(信息持久化)。
3、信息持久化
//BasicProperties设置MessageProperties.PERSISTENT_TEXT_PLAIN,信息持久化
channel.basicPublish("",TASK_QUEUE_NAME,MessageProperties.PERSISTENT_TEXT_PLAIN,message.getBytes("UTF-8"));
IBasicProperties properties = channel.CreateBasicProperties();
properties.DeliveryMode = 2;
channel.BasicPublish("", "TaskQueue", properties, bytes);DeliveryMode等于2就说明这个消息是persistent的。1是默认是,不是持久的。在接收者接收消息并处理的时候会出现各种各样的问题:抛出异常导致与RabbitMQ连接断开,程序挂掉,网络问题等等。往往在出现这些问题的时候我们通常都希望队列能保存这些消息,并在程序再次起来的时候能够重新处理,或如果是负载均衡的模式下,能够把这个消息重新分配给其他的同等的接受者来处理。这同样也是RabbitMQ对消息持久化的一种功能。这我们在消息的传输控制中做详细的说明
4、消息拒收
拒收,是接收端在收到消息的时候响应给RabbitMQ服务的一种命令,告诉服务器不应该由我处理,或者拒绝处理,扔掉。接收端在发送reject命令的时候可以选择是否要重新放回queue中。如果没有其他接收者监控这个queue的话,要注意一直无限循环发送的危险。
BasicDeliverEventArgs ea = (BasicDeliverEventArgs)consumer.Queue.Dequeue();
channel.BasicReject(ea.DeliveryTag, false);BasicReject方法第一个参数是消息的DeliveryTag,对于每个Channel来说,每个消息都会有一个DeliveryTag,一般用接收消息的顺序来表示:1,2,3,4 等等。第二个参数是是否放回queue中,requeue。
BasicReject一次只能拒绝接收一个消息,而BasicNack方法可以支持一次0个或多个消息的拒收,并且也可以设置是否requeue。
channel.BasicNack(3, true, false);
5、消息的QoS
QoS = quality-of-service, 顾名思义,服务的质量。通常我们设计系统的时候不能完全排除故障或保证说没有故障,而应该设计有完善的异常处理机制。在出现错误的时候知道在哪里出现什么样子的错误,原因是什么,怎么去恢复或者处理才是真正应该去做的。在接收消息出现故障的时候我们可以通过RabbitMQ重发机制来处理。重发就有重发次数的限制,有些时候你不可能不限次数的重发,这取决于消息的大小,重要程度和处理方式。
甚至QoS是在接收端设置的。发送端没有任何变化,接收端的代码也比较简单,只需要加如下代码:
channel.BasicQos(0, 1, false);代码第一个参数是可接收消息的大小的,但是似乎在客户端2.8.6版本中它必须为0,即使:不受限制。如果不输0,程序会在运行到这一行的时候报错,说还没有实现不为0的情况。第二个参数是处理消息最大的数量。举个例子,如果输入1,那如果接收一个消息,但是没有应答,则客户端不会收到下一个消息,消息只会在队列中阻塞。如果输入3,那么可以最多有3个消息不应答,如果到达了3个,则发送端发给这个接收方得消息只会在队列中,而接收方不会有接收到消息的事件产生。总结说,就是在下一次发送应答消息前,客户端可以收到的消息最大数量。第三个参数则设置了是不是针对整个Connection的,因为一个Connection可以有多个Channel,如果是false则说明只是针对于这个Channel的。
这种数量的设置,也为我们在多个客户端监控同一个queue的这种负载均衡环境下提供了更多的选择。
//对服务器确认之前,一次只接受一条信息
channel.basicQos(1);