基于MDP和Policy Gradient的强化排序学习(RLTR)实验
排序(rank)是搜索、推荐业务中经常能够遇到的业务场景:对于某个特定用户,如何针对该用户的信息,进行个性化的备选产品(candidate)的推荐排序,从而优化业务指标(例如点击率、营收等)?在大数据的支撑下,我们可以通过一些流行的机器学习算法来自动实现排序任务的学习,如基于传统模型计算出的分数直接排序,或者LTR(learning to rank)、rankBoost、rankSVM、Page Rank等更有针对性的排序算法。这些主要基于监督学习的方法有着相似的流程:首先收集具有不同标签的样本,基于标签的指标评估学习得到模型,再通过这个模型进行实际的预测和排序。而与强化学习(Reinforcement Learning)算法【1】则提供了不太一样的解决思路:我们可以利用强化学习能够在agent和environment之间进行交互式学习的特点,同时进行排序操作和自身的学习。
强化排序学习(MDPrank)
强化学习对排序最明显的改变是实现了“scoring and sorting”到“sequential decision making”的转变。以传统排序算法最常见的point-wise思路为例,模型的输入包括单个用户和单个candidate的特征,而输出的则是该candidate对该用户的score值;在排序过程中,用模型生成每个candidate对该用户的score,然后根据score的大小进行candidate的排序;整个过程是首先scoring再sorting,前提是假设candidates与user之间的相关性彼此独立(图2)。而强化学习则考虑到1)candidate之间的相互关联 2)当前排序位置对score的影响,从而每次在决定某个排序位置的candidate时考虑当前所有已经排好的candidates对后续的影响,因此能够实现序列化的动态决策(sequential decision making)(图2)。
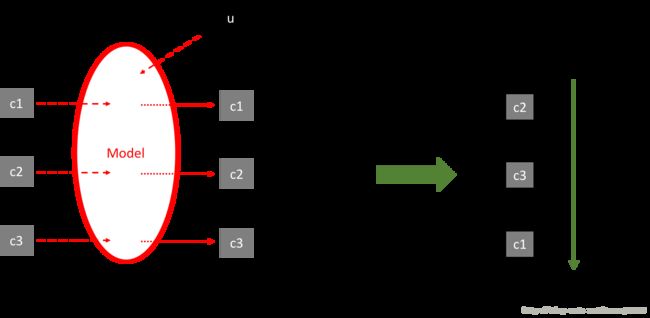
图1 scoring and sorting过程
(u:user;c:candidate;虚线:模型输入;点线:模型输出)
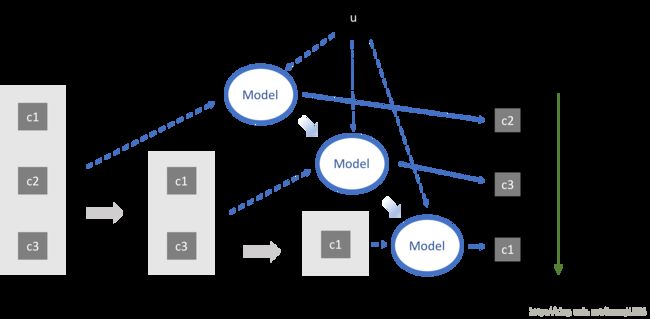
图2 sequential decision making过程
(u:user;c:candidate;虚线:模型输入;点线:模型输出)
【2】和【3】提供了强化排序学习(Reinforcement Learning To Rank, RLTR)的一个解决方案:把每个排序过程看成是一系列的马尔可夫过程,从而形成一个markov decision process(MDP)问题;对每一次排序决策,通过一个随机的policy策略,基于当前状态(state)进行全部可能的行为(action)的monte carlo抽样;基于candidate的特征情况,定义一个平滑可导的RL的优化目标函数;在迭代时,基于上一次行为得到的奖励(reward),采用policy gradient方法对policy内部的参数进行更新,从而实现自身的学习和进化。其中,【2】面对的是搜索问题中的多样化(diversification)需求,而【3】面对的是搜索问题中的相关性(relevance)需求;前者的模型结构比后者更加复杂一些。
MDP rank for diversification:
1. 排序对象:用L维向量q代表用户信息;假设一共有M个待排序的candidates,则每个排序的episode共包括M个步骤;对于第m个candidate,假设其特征向量为xm,同样为L维向量。
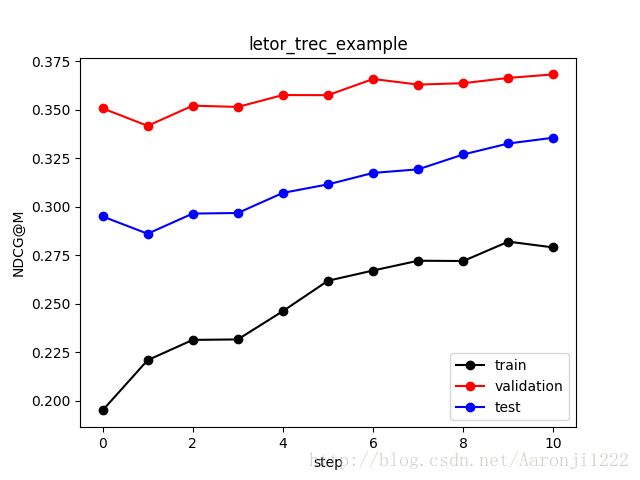
2. Action:对于排序任务,每次选择将candidates中的第m个放到第t个位置的行为定义为MDP的一个Action,用at表示。因此,与一般的强化学习默认采用时间(t)作为步骤不同,这里的步骤t代表了rank位置;因此,每个排序的episode共包括M个步骤即t=0,1,...,M-1;在第t步骤,通过at把第m个产品排到第t个位置,即m=m(at),0<=m 3. State:假设对于每个candidate,我们有对应的L维特征向量x;则第t步的state,st:={Zt, Xt, ht},其中Zt为已经排好序的x的组合;Xt为尚未被排序的x的组合;ht为K维变量,它同时编码了用户的初始需求和当前已被排序的candidates所覆盖的信息,并且具有一定的步骤间记忆功能。显然,对于初始步骤即t=0,Zt为空集,Xt为全部x的集合X:={x0, x1, ..., xM-1},而h0则被定义为:h0=sig(Vqq),Vq为K*L维矩阵;sig()即sigmoid函数,当输入为向量或矩阵时,代表对其每个element分别进行sigmoid变换。 4. Transition:给定st和at时,下一步状态st+1的计算方式。对于MDPrank, V为K*L维矩阵,W为K*K维矩阵。图3具体示意了state和action的具体transition方式。可以看出,ht有着与循环神经网络(RNN)类似的记忆功能。 图3 模型状态之间的transition (s: state, a: action, x: feature of candidate) 5. Policy: 即给定当前state的情况下,RL的agent生成action的方式。这里采用了stochastic而不是deterministic的policy,即对当前全部可能的action集合A,通过policy计算得到A中每个a的概率的大小,再依照概率抽样得到当前的at。具体的policy函数定义为 U为L*K维矩阵。 6. Reward:在离线学习时,每一个被排序的candidate都会反馈给我们一个reward,这种reward可以是直接的label,也可能是label转化为排序场景常用的metric,例如rt:=DCG@m(对于第m个位置的candidate)。由于RL的一个特质就是可以考虑长期而不只是瞬时的回报,我们定义第t步时的长期回报为 这里我们给不同步骤的回报赋予同样的权重,即discount rate=1.0。 7. 参数学习:与主流的基于action-value函数的RL方法(如Q-learning)不同,policy gradient不需要计算价值函数,而是直接优化一个表现函数J()。对于排序任务,我们希望在遵循一定policy的情况下最大化第0步时的长期回报的期望,即 \theta即为模型的待定参数。 8. 离线学习:离线学习分两部分: (1)对于一组u和candidates数据,首先按照当前的theta和policy,完成一次排序,即“SampleAnEpisode”,生成一个排序episode为E={s0, a0, r1,s1, a1, s2, ..., sM-1, aM-1,rM}。 (2)对于一个episode,令t从0循环到M-1;对于每个t,对theta做一次stochastic gradient descent;因此,我们需要推出J相对于theta的偏导数。根据【1】中第13章的REINFORCE算法,每一次update为 其中\eta为学习率,与迭代次数、converge阈值等均为超参数。 (3)对数据中的全部user循环,每次生成一次episode,对\theta进行更新后,再重新迭代,直到满足迭代结束条件,即对数据进行了足够的Monte Carlo sampling。 9. 在线预测:线上的时候我们无法及时得到reward,并且不再对\theta进行更新;因此,对每一次的排序决策,我们选择完全信任policy: 从t=0开始循环到M-1,直到生成全部排序序列{m(a0), m(a1),…,m(aM-1)}。 与diversification相比,relevance主要只考虑user和candidate之间的相关性,更接近point-wise的情形。因此【3】的算法比【2】简化一些。如果我们忽略掉每一步ht中的sig()函数处理,并令 则ht退化为参数w,而state可以只用{xt}表示;在模型学习时,只需要按照对参数w进行更新。重新观察policy的结构,可以发现relevance模型的policy变成了一个小型的神经网络:将待排序的x的特征值作为输入,先经过一个全连接层,再经过一次softmax,最终的输出为不同action的选择概率。 这里简单复现了relevance模型,代码参见https://github.com/AaronJi/RL/tree/master/python/MDPrank。实验数据采用Microsoft提供的开源LETOR数据【4】,下载地址见【5】,包括TREC(TD2003)和OHSUMED两个数据集。其中,TREC数据中candidate的特征维度为44,学习率设置为\eta=0.005;OHSUMED数据的特征维度为25,学习率设置为\eta=0.0001。由于笔记本算力有限,这里只跑了两个数据集中的Fold1,迭代10次,并统计了10个agent的平均表现。对于排序效果,采用NDCG@M对排序效果进行衡量,结果见图4、图5。 图4 MDPrank在OHSUMED数据集的平均NDCG@M表现 图5 MDPrank在TREC数据集的平均NDCG@M表现 随着迭代次数的增加,可以遇见MDPrank 的效果会进一步提升;还可以根据validation set的表现,对超参数如\eta等进一步优化。 【1】Reinforcement Learning: An Introduction. Sutton, Barto, MIT Press, 2016 【2】Adapting Markov Decision Process for Search Result Diversification. Xia, Xu, Lan, Guo, Zeng, Cheng, SIGIR’17, 2017 【3】Reinforcement Learning to Rank with Markov Decision Process. Wei, Xu, Lan, Guo, Cheng, SIGIR’17, 2017 【4】LETOR: A benchmark collection for research on learning to rank for information retrieval. Qin, Liu, Xu, Li, Inf Retrieval 2010.LINK: https://www.microsoft.com/en-us/research/publication/letor-benchmark-collection-research-learning-rank-information-retrieval/ 【5】https://www.microsoft.com/en-us/research/people/tyliu/?from=http%3A%2F%2Fresearch.microsoft.com%2Fusers%2Ftyliu%2Fletor%2F![]()

![]()

![]()
![]()
![]()
MDP rank for relevance:
![]()
代码实现

相关链接