数据结构基础知识核心归纳(二)
Android Java 数据结构
Android基础技术核心归纳(一) Java基础技术核心归纳(一) 数据结构基础知识核心归纳(一)
Android基础技术核心归纳(二) Java基础技术核心归纳(二) 数据结构基础知识核心归纳(二)
Android基础技术核心归纳(三) Java基础技术核心归纳(三) 数据结构基础知识核心归纳(三)
Android基础技术核心归纳(四) Java基础技术核心归纳(四)
不知不觉又是一年的9月,今天跟一个师弟聊天,谈到了他现在面试的一些情况,突然想起自己当年也是这么走过来的,顿时感慨良多。Android/Java经验汇总系列文章,是当初自己毕业时笔试、面试和项目开发中相关的总结,虽然不是很高深的东西,也没有归纳得很全面,但是对Android、算法、Java把握个大概还是没问题,今天特意将这些文章放出来,希望能够对看到这个系列文章的毕业生朋友一点帮助吧。当然,由于受当时知识面的限制,归纳得可能不是很准确,若有疑问就留言吧,我就不细看了。
1.冒泡排序(交换排序算法)
1.实现原理
从 最后一个关键字开始,两两比较相邻记录的关键字,如果反序(前者大于后者)则交换,直到没有反序的记录为止,即完成一次冒泡排序,然后再依次进行相同操作,最多需 (length-1)次 冒泡排序。实质上,冒泡排序就是每次交换的结果作为下一次两两比较的基础,最终将较小的数字如同气泡般慢慢浮到上面。
2.算法实现
(1)冒泡排序功能函数
void BubbleSort(int *a,int len){
int temp = 0;
/*第一步:边界处理,指针变量指向null,len<0*/
if(!a||len<0)
return;
/*第二步:进行n-1次冒泡排序*/
for(int i=0;ii;j--){
if(a[j-1]>a[j]){ //完成一次交换,将较小的存放到前面
temp = a[j-1];
a[j-1] = a[j];
a[j] = temp;
}
}
}
} void main(){
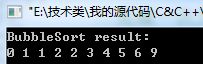
int a[]={2,1,4,3,6,0,2,5,9,1};
//计算数组的长度=sizeof(数组名)/sizeof(数组基本类型)
//即数组所占的总字节数/单个元素占的字节数
BubbleSort(a,sizeof(a)/sizeof(int));
}
3.算法性能分析
(1)时间复杂度:
◆最好情况:待排序本身有序,只需进行(n-1)次比较,没有数据移动,时间复杂度为O(n)
◆最坏情况:待排序逆序,需进行1+2+3+....+(n-1)=n*(n-1)/2数据移动,时间复
杂度为O(n^2)
(2)空间复杂度:冒泡算法只需要一个记录的辅助空间(temp),故空间复杂度为O(1).
(3)稳定性:没有跳跃式数据交换,稳定。
2.简单选择排序
1.实现原理
对长度为n的序列,通过(n-i)次关键字间的比较,从(n-i+1)个记录中选出关键字最小的关键字,并与第i(1≤i≤n)个记录交换。举例:有一长度n=5的序列,初始状态为{57 68 59 52 49}
首先,取第一个记录57(i=1),通过n-i=4次比较,选出n-i+1=5个记录中最小关键字记录49,与第i=1交换;

其次,取第二个记录68(i=2),通过n-i=3次比较,选出n-i+1个记录中最小关键字记录52,与第i=2交换;

以此类推,最后得到的排序序列为:49 52 57 59 68
2.算法实现
(1)代码实现
void selectSort(int *a,int len)
{
int min,temp=0;
/*第一步:边界处理,指针变量指向null,len<0*/
if(!a||len<0)
return;
/*第二步:将第i个元素,与其他(n-i)个元素进行 比较,从(n-i+1)个元素中选出最小的并与第i个
元素 进行交换。注意:第i个元素的下标为i-1(i>0)*/
for(int i=0;ia[j]) //将(n-i+1)个元素中最小元素下标赋值给min
min=j;
}
/*第三步:完成一次选择排序,将小标min对应最小元素与第i个元素互换*/
if(i!=min){
temp=a[i];
a[i]=a[min];
a[min]=temp;
}
}
} void main(){
int a[]={2,1,4,3,6,0,2,5,9,1};
//计算数组的长度=sizeof(数组名)/sizeof(数组基本类型)
//即数组所占的总字节数/单个元素占的字节数
BubbleSort(a,sizeof(a)/sizeof(int));
}
3.算法性能分析
(1)简单选择排序最大的特点就是交换移动数据的次数相当少,最好情况交换次数为0次,最坏情况(逆序)交换次数为n-1次。对于比较次数,最好最坏的情况都是一样多,因为第i趟排序需要进行n-1次关键字的比较,因此总共需要(n-1)+(n-2)+...+1=n(n-1)/2次比较。故总的时间复杂度=(n-1)+n(n-1)/2----->即O(n^2)。
(2)空间复杂度:冒泡算法只需要一个记录的辅助空间(temp),故空间复杂度为O(1).
(3)稳定性:没有跳跃式数据交换,稳定。
3.直接插入排序
1.实现原理
将一个记录插入到已经排好序的有序表中,从而得到一个新的、记录数增1的有序表。
★举例:序列的初始状态{57,68,59,52}
第一步:插入57到空表,此时,有序表为{57};
第二步:插入68到有序表,68>57,插在57之后,此时有序表为{57,68}
第三步:插入59到有序表,57<59<68,插在57和68之间,此时有序表为{57,59,68}
第四步:插入52到有序表,52<57,插在57之前,此时有序表为{52,57,59,68}
即,直接插入排序的结果为:52 57 59 68
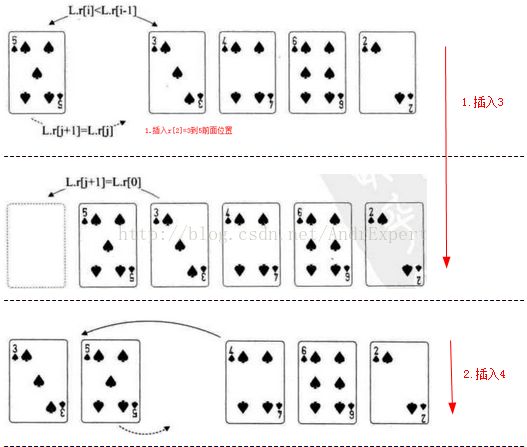

2.算法实现
(1)直接插入算法代码
//直接插入排序函数
void InsertSort(int *a,int len){
int i,j,temp=0; //temp辅助空间
for(i=1;ia[i]){ //由于第i个元素前面的元素已经有序,因此只需比较与第i-1个元素决定是否继续向前比较
temp = a[i]; //将要排序的元素存放到临时变量中
for(j=i-1;a[j]>temp;j--){ //后移逆序的元素
a[j+1] = a[j]; //将元素依次向后移动一位
}
a[j+1]=temp;
}
}
} void main()
{
int a[]={2,1,4,3,6,0,2,5,9,1};
//计算数组的长度=sizeof(数组名)/sizeof(数组基本类型)
//即数组所占的总字节数/单个元素占的字节数
InsertSort(a,sizeof(a)/sizeof(int));
}
3.算法性能分析
(1)时间复杂度:
◆最好情况:序列本身有序,比较次数=n-1,移动次数为0,总次数=n-1+0
故时间复杂度为O(n);
◆最坏情况:序列逆序,比较次数=2+3+....+n=(n+2)(n+1)/2,移动次数=(n+4)(n-1)/2
故时间复杂度为O(n^2);
◆平均情况:O(n^2)
注:由于第i位元素的前i-1个元素有序,因此对于待排序的第i位元素只需与第i-1位元素比较即可
(2)空间复杂度:直接插入算法只需要一个记录的辅助空间,故空间复杂度为O(1).
(3)稳定性:是一种稳定的排序算法
4.快速排序(交换排序算法)
1.实现原理
快速排序是冒泡排序的改进,快速排序也是分治法思想的一种实现,他的思路是:选取一个基准值,使数组中的每个元素与基准值(Pivot,通常是数组的首个值,A[0])比较,数组中比基准值小的放在基准值的左边,形成左部;比基准值Pivot大的放在右边,形成右部;当所有元素都比较完后,即说明完成一趟快速排序,此时,将待排序序列分割成独立的两部分,其中一部分的记录关键字均比另一部分记录的关键字小。再分别对这两个子序列进行快速排序,直到整个序列有序为止。

注意:比较(交换)后,若指针p2在基准的左边,则p2+1指向下一个元素;若指针p2在基本的右边,则p2-1指向下一个元素。
2.算法实现
/**
*(1)找基准值,设pivot=a[0];
*(2)分区(Partition)比基准值小的放在左边,大的放右边,基准值(pivot)放左部与右部之间
*(3)分别对左部(a[0]-a[pivot-1]),右部(a[pivot+1] - a[n-1])进行递归,重复上述步骤
*/
/***对顺序表L作快速排序
外封装一个函数,方便递归排序****/
void QuickSort(SqList *L)
{
QSort(L,1,L->length); //调用快速排序函数
}
分析:"QSort(L,1,L.length);"中1和L-length对应当前待排序的序列最小下标值low和最大下标值high.
/***对顺序表L中的子序列L.r[low...high]作快速排序***/
void QSort(SqList *L,int low,int high)
{
int pivot; //基准
if(low◆ "pivot = Partition(L,low,high);"函数功能:先取当中的一个关键字作为基准(如50),然后通过一系列两两相邻记录相互比较交换后,基准50被放置到一个位置,使得它左边的值都比它小,右边的值比它大,我们将这样的关键字称为枢轴(pivot)。
Partion(L,1,9)执行之后,待排序列变成{20,10,40,30,50,70,80,60,90},并返回pivot=5,表明基准50被放置在数组下标为5的位置,第一次快速排序完成,计算机把原来的数组变成两个位于50左和右小数组{20,10,40,30}和{70,80,60,90}。
◆"QSort(L,low,pivot-1)"和"QSort(L,pivot+1,high); "为递归调用语句,即分别对{20,10,40,30}和{70,80,60,90}待排子序列进行Partion操作,直到顺序全部正确为止。
/***Partion快速排序函数
功能:交换顺序表L中子表的记录,使枢轴记录到位,并返回其所在位置
此时,在它之前(后)的记录均不大(小)于它。***/
int Partion(SqList *L,int low,int high)
{
int pivotkey;
pivotkey=L->r[row]; //用子表的第一个记录作枢轴记录
whlie(lowr[high]>=pivotkey)
high--;
swap(L,low,high); //将比枢轴记录小的记录交换到低端
while(lowr[low]<=pivotkey)
low++;
swap(L,low,high); //将比枢轴记录大的记录交换到高端
}
return low; //返回枢轴所在的位置
} 3.算法性能分析
快速排序的时间取决于快速排序递归的深度,可以用递归树(为平衡树,性能较好)来描述递归算法的执行情况。
(1)时间复杂度:O(nlogn),O(nlogn),最坏情况O(n^2):

(2)空间复杂度:递归造成的栈空间的使用
最好情况,递归树的深度为log2^n,其空间复杂度为O(logn);
最坏情况,需要进行n-1递归调用,其空间复杂度为O(n);
(3)算法稳定性:由于关键字的比较和交换是跳跃式进行的,快速排序是不稳定的排序方法
5.希尔排序(插入排序算法)
1.实现原理
希尔排序是直接插入排序的改进,其基本思想是:将序列中的元素相距某个"增量"组成一个子序列(有多个),然后在子序列中分别进行直接插入排序,得到一个基本有序的序列。再另取一个"增量"按同样的方法得到另一个基本有序序列,直到整个序列有序。其中,基本有序即小的关键字基本在前面,大的基本在后面,不大不小的基本在中间。
举例:假定有一序列表为{57,68,59,52,72,28,96,33,14,19},其中表长n=10
第一步:取增量d1=n/2=5(取奇数),则分组的子序列有{57,28} {68,96} {59,33} {52,14} {72,19},然后对每组进行直接插入排序.需要注意的是,这里的子序列是与每个记录所在的位置相关联的。
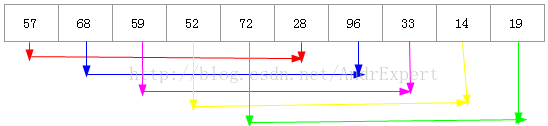
得到序列:28 68 33 14 19 57 96 59 52 72
第二步:取增量d2=d1/2=3(取奇数),分组的子序列有{28,14,96,72} {68,19,59} {33,57,52},

然后对每组进行直接插入排序得到序列:14 19 33 28 59 52 72 68 57 96
第三步:去增量d3=d2/2=1(取奇数),分组的子序列为{14 19 33 28 59 52 72 68 57 96}

然后对该子序列进行直接插入排序得到序列:14 19 28 33 52 57 59 68 72 96,即排序完成。
2.算法实现
/**
*(1)初始化增量inrement=L->length=9
*(2)计算增量inrement=inrement/3+1=4,从下标i=inrement+1=5的关键开始累加
* 与下标为i-increment关键字比较交换
*(3)计算增量inrement = increment/3+1=4/3+1=2,步骤同上
* .......
*(4)计算增量inrement = increment/3+1=1/3+1=1,不满足条件,排序结束
*/
void ShellSort(SqList *L)
{
int i,j;
int increment = L->length; //初始化增量increment,值为表长
do{
increment = increment/3+1; //计算增量increment公式
for(i=increment+1;ilength;i++) {
if( L->r[i-increment] > L->r[i] ){
L->r[0] = L->r[i]; //将子序列中要插入的关键字保存到r[0]
for(j=i-increment;j>0&&L->r[0]r[j];j -= increment) {
L->r[j+increment] = L->r[j]; //记录后移,查找插入位置
}
L->r[j] = L->r[0]; //插入到正确位置
}
}
}while(increment>1)
} for(i=increment+1;i
由于希尔排序的关键并不是随机分组后各自排序,而是将相隔某个"增量"的记录组成一个子序列,实现跳跃式的移动,使得排序的效率提高。
(1)时间复杂度:O(n^1.5),超过了O(n^2)瓶颈
(2)空间复杂度:直接插入算法只需要一个记录的辅助空间,故空间复杂度为O(1).
(3)稳定性:由于记录是跳跃式的移动,故希尔排序不是一种稳定的算法。
6.堆排序(选择排序算法)
1.实现原理
堆排序(Heap Sort)就是利用堆(假设利用大顶堆)进行排序的方法。它的基本思想是:将待排序的序列构造成一个大顶堆,此时,整个序列的最大值就是堆顶的根结点。将它移走(即将其与堆数组的末尾元素交换,此时末尾元素就是最大值),然后将剩余的n-1个序列重新构造成一个堆,这样就会得到n个元素中次大值。如此反复执行,便能得到一个有序序列。
★举例:对数列{46,79,56,38,40,84}建立大顶堆,则初始堆为______,最终排序结果______。
(1)求初始堆
第一步:首先对这些数据建立完全二叉树,填充的规则是按层次遍历将数据一一填入;
第二步:把二叉树调整为堆,即首先看第n/2个结点56,它比其子结点84小,所以应该把84和56的位置对调;

第三步:看第n/2-1个结点79,它比其他的两个子结点都要大,所以不用调整;接着看第n/2-2个结点46,它比它的两个子结点都小,所有把它和较大的子结点84对调;

第四步:接着我们看经过调整的结点46在当前的位置是否符合堆的规则,由于它小于其子结点56,所有要与子结点56进行交换,最终得到初始堆序列:84,79,56,38,40,46

注:对于结点i,i≥n/2时,表示结点i为叶子结点。
(2)根据初始堆获取最终排序
第一步:将根结点84与最后一个叶子结点46交换,然后,删除指向结点84的指针,调整完全二叉树中的结点重建新的大顶堆。结果:取出84;

第二步:再次将根结点79与最后一个叶子结点40交换,然后,删除指向结点79的指针,再次调整完全二叉树中的结点重建新的大顶堆。结果:取出79.;

依次类推,分别取出56、46、40、38。故最后的排序为:38、40、46、56、79、84
2.算法性能分析
(1)时间复杂度:O(nlogn)
堆排序的运行时间主要是消耗在初始构建堆和在重建堆时的反复筛选上。在构建堆的过程中,因为我们是完全二叉树从最下层最右边的非终端结点开始构建,将它与其孩子进行比较和若有必要的互换,对于每个非终端结点来说,其实最多进行两次比较和互换操作,因此整个构建堆的时间复杂度为O(n)。
在正式排序时,第i次取堆顶记录重建堆需要用O(logi)的时间(完全二叉树的某个结点到根结点的距离为[log2^i]+1),并且需要去n-1次堆顶记录,因此,重建堆的时间复杂度为O(nlogn)。所以,堆排序总时间复杂度为构建堆和排序之和,且由于堆排序对原始记录的排序状态不敏感,因此无论最好、最坏和平均时间复杂度均为O(nlogn)
(2)空间复杂度:O(1)。只需一个用来交换的暂存空间单元
(3)稳定性:由于记录的比较与交换是跳跃式进行,堆排序不稳定;
(4)适应范围:由于初始构建堆所需的比较次数较多,堆排序不适合待排序序列个数较少的情况
3.堆结构
堆是具有下列性质的完全二叉树:①每个结点的值都大于或等于其左右孩子结点的值,称为大顶堆;②每个结点的值都小于或等于其左右孩子结点的值,称为小顶堆。堆的数学描述如下:
n个元素的序列{K1,K2,...,Kn}当满足Ki≤K2i且Ki≤K2i+1或者Ki≥K2i且Ki≥K2i+1,则称为堆。
注:对于结点i,i≥n/2时,表示结点i为叶子结点。
7.归并排序
1.实现原理
归并排序(Merging Sort)即利用归并的思想实现的排序方法,其中归并在数据结构中的定义是将两个或两个以上的有序表组合成一个新的有序表。基本思想:假设初始序列含有n个记录,则可以看成是n个有序的子序列,每个子序列的长度为1,然后两两归并排序,得到[n/2]([x]表示不小于x的最小整数)个长度为2或1的有序子序列;再两两归并排序,......,如此重复,直至得到一个长度为n的有序表,这种排序方法称为2路归并排序。注:如此循环直到得到一个长度为n的有序表,通常需要[log2n]趟,如果该值为奇数,则为[log2n]+1。
★举例:有一个序列,初始状态为{16,7,13,10,9,15,3,2,5,8,12,1,11,4,6,14}

2.算法性能分析
(1)递归方法
①空间复杂度 :O(n+logn)
由于归并排序在归并过程中需要与原始记录序列同样数量的存储空间存放归并结果以及归并时深度为log2^n的栈空间,因此空间复杂度为O(n+logn)。
②时间复杂度 :O(nlogn)
一趟归并需要将SR[1]~SR[n]中响铃的长度为h的有序序列进行两两归并,并将结果放到TR[1]~TR[n]中,这需要将待排序序列中的所有记录扫描一遍,因此耗费O(nb)时间,而由完全二叉树的深度可知,整个归并排序需要进行[log2^n]次。因此,总的时间时间复杂度为O(nlogn),而且这是归并排序算法中最好、最坏、平均的时间性能。
③算法稳定性 :稳定
归并排序是一种比较占用内存,但却效率高且稳定的算法。
(2)非递归方法
非递归的迭代方法,避免了递归时深度为log2^n的栈空间,空间只是用到申请归并临时用的TR数组,因此空间复杂度为O(n),并且避免递归也在时间性能上有一定的提升。总之,使用归并排序时,应尽量考虑用非递归方法。
8.7种内排序算法性能比较

分析:从平均情况来看,改进算法性能远远优于简单排序算法;
从最好情况来看,冒泡排序和直接插入排序更胜一筹,即待排序列基本有序情况
从最坏情况来看,堆排序和归并排序优于快速排序及其他简单排序算法
注:logn>1.
1.从待排序数据规模(n)
当数据规模较小时,考虑使用简单的排序算法(如直接插入排序或冒泡排序);
当数据规模较大时,考虑使用改进的排序算法(如快速排序);
当待排序列基本有序时,考虑使用直接插入排序或冒泡排序;
2. 稳定性:归并排序 > 堆排序、快速排序
占内存:归并排序 > 快速排序 > 堆排序
性能稳定性:归并排序、堆排序 > 快速排序
3.排序算法特点
(1)快速排序:排序速度快,适用于待排数据规模大的情况。当记录随机分布的时候,快排的平均时间最短。但有可能出现最坏的情况,即时间复杂度为O(n^2),且递归深度为n,所需的栈空
间为O(n).
(2)堆排序:堆排序不会出现快速排序那样的最坏情况,且堆排序所需的辅助空间比快速排序、归并排序要少,算法不稳定。因此,适用于排序时不要求很高的稳定性且内存有要求的排序。
(3)归并排序:适用于要求高的稳定性,但内存充足的数据排序。此外,归并排序可以用于内排序,也可以用于外排序。在外排序时,通常采用多路归并,并且通过解决长顺串的合并,产生长的初始串,提高主机与外设并行能力等措施,以减少访问外存次数,提高外排序的效率。
(4)简单选择排序
从上诉表格中看,似乎简单选择排序是3种简单排序中最差的。但是,如果记录的关键字本身信息量比较大(比关键字都是数十位的数字),此时表明其占用存储空间很大,这样移动记录所花费的时间也就越多。而由于简单选择排序是属于移动次数较少的算法,最好情况(待排序基本有序)关键字移动次数为0,最坏情况也才O(n)。
9.二分查找算法
1.实现原理
(1)算法思想
在顺序存储的有序表中,取中间记录a[mid]作为比较对象。1) 当给定值与中间记录的关键字相等时,即a[mid]=key,则说明查找成功;2)若给定值小于中间记录的关键字,即a[mid]>key,则在中间记录的左半边继续查找;3)若给定值大于中间记录的关键字,即a[mid]
顺序存储的线性表,关键字有序.
2.算法实现
(1)功能函数
int Binary_Search(int *a,int len,int key){
int low,high,mid;
if(!a || len<=0) //边界处理
return -1;
low=1;high=len;
while(low<=high){
mid = (low+high)/2;
if(key < a[mid])
high = mid - 1;
else if(key > a[mid])
low = mid + 1;
else{
return mid; //当查找不成功时,返回11
}
}
}void main(){
int a[] = {0,1,16,24,35,47,59,62,73,88,99};
int length = sizeof(a)/sizeof(int)-1; //存储下标为1~n
printf("len=%d\n",length );
printf("result=%d\n",Binary_Search(a,length,73));
}
3.算法性能分析
由二分查找过程可绘制成一棵二叉树,树中每个结点表示表中一个记录,结点中的值为该记录在表中的位置,通常称这个描述查找过程的二叉树为判定树。根据二叉树的性质4:"具有n个结点的完全二叉树的深度为[log2^n]+1"。因此,折半查找法在查找成功时进行比较的关键字个数最多不超过树的深度,而具有n个结点的判断树的深度为[log2^n]+1,即时间复杂度最坏情况为o(logn),相比顺序查找时间复杂度O(n)效率要高得多。
10.Hash算法
Hash表又被哈希表、散列表,它是一种十分使用的查找技术。我们通过查找关键字不需要比较就可获得需要的纪录(关键字)的存储位置,这是一种新的存储技术--散列技术,具有极高的查找效率。
1.散列技术
散列技术是在纪录的存储位置和它的关键字之间建立一个确定的对应关系f,使得每个关键字key对应一个存储位置f(key)。查找时,根据这个确定的对应关系找到给定值key的映射f(key),若查找集合中存在这个纪录,则必定在f(key)的位置上。散列技术既是一种存储方法,也是一种查找方法,散列技术的记录之间不存在什么逻辑关系,它只与关键字有关联,散列主要是面向查找的存储结构。
★适用场合:散列技术最适合的求解是查找与给定值相等的记录。
2.哈希(Hash)函数
将纪录的存储位置和它的关键字之间建立的确定的对应关系f(key)称为散列函数,又称为哈希(Hash)函数。散列函数值即为关键字在存储空间的存储位置,设计一个简单、均匀、存储利用率高的散列函数是散列技术中最关键的问题。
3.哈希表(Hash table)
采用散列技术将纪录存储在一块连续的存储空间中,这块连续存储空间称为散列表或哈希表。
4.冲突
在理想的情况下,每一个关键字,通过散列函数计算出来的地址都是不一样的。实际上,当两个关键字key1!=key2,却有f(key1)=f(key2),即不同关键字在连续存储空间中的存储空间一样,这种现象我们称为冲突。

5.★散列表查找步骤★
(1)在存储时,通过散列函数计算记录的散列地址,并按此散列地址存储该纪录;
(2)当查找记录时,我们通过同样的散列函数计算记录的散列地址,按此散列地址访问该纪录。
散列函数的构造函数
Hash函数是创建哈希表的前提,影响着元素查找效率,其函数的值为元素值在哈希表(连续存储空间)中的地址即哈希地址。对于Hash函数的构造,没有特定的要求,所以方法很多,只是我们需了解什么样的哈希函数才叫好的Hash函数,这样就便于我们根据实际情况来构造合理的Hash函数。
1.构造原则
(1)计算简单
如果设计一个算法可以保证所有的关键字都不会产生冲突,但是这个算法需要很复杂的计算,会耗费很多的时间,这对于需要频繁地查找来说,就会大大降低查找的效率了。因此,散列函数的计算时间不应该超过其他查找技术与关键字比较的时间。
(2)散列地址分布均匀
尽量让散列地址均匀地分布在存储空间中,以保证存储空间的有效利用,并减少为处理冲突而耗费的时间。
2.常用构造方法
■直接定址法
(1)原理:取关键字(key)或关键字的某个线性函数值为哈希地址,即:
H(key)=key或H(key)=a*key+b(a、b为常数)
(2)特点:散列函数的优点就是简单、均匀、不易产生冲突,适用于事先知道关键字的分布和查找表较小且连续的情况。
■数字分析法
数字分析法的基本思想:使用抽取方法将抽取关键字的一部分来计算散列存储位置的方法,数字分析法通常适合处理关键字位数比较大的情况,如果事先知道关键字的关不且关键字 的若干位分布较均匀,就可考虑这个方法。
■平方取中法
先通过求关键字的平方值扩大相近数的差别,然后根据表长度取中间的几位数作为散列函数值(哈希地址)。又因为一个乘积的中间几位数和乘数的每一位都相关,所以由此产生的散列地址比较为均匀。适用:不知道关键字的分布,而位数又不是很大的情况。
即,上述三个关键字的哈希地址分别为4、0、2
■折叠法
(1)原理:折叠法是将关键字从左到右分割成位数相等的几部分(注意最后一部分位数不够时可以短些),然后将这几部分叠加求和,并按散列表表长,取后几位作为散列地址。
(2)适用场合:事先不需要直到关键字的分布,适合关键字位数较多的情况
■除留余数法(最常用)
对于散列表长为m的散列函数公式为
f(key)=key mod p(p=
注:若散列表表长为m,通常p为小于或等于表长(最好接近m)的最小质数或不包含小于20质因子的合数。p的选取原则:冲突越少越好。
■
基数转换法
将关键字看作是某个基数制上的整数,然后将其转换为另一基数制上的数
即,17、24、9为关键字21、30、11的哈希地址(存储空间)
■随机数法
选择一个随机数,取关键字的随机函数值为它的散列地址,即f(key)=random(key),其中random是随机函数。当关键字的长度不等时,采用这个方法构造散列函数是比较合适的。
总结:
根据不同因素,决策选择哪种散列函数:
1.计算散列地址所需的时间;
2.关键字的长度;
3.散列表的大小;
4.关键字的分布情况;
5.纪录查找的频率。
处理散列冲突方法
1.开放定址法
★线性探测法
(1)定义:开放定址法就是一旦发生了冲突,就去寻址下一个空的散列地址,只要散列表足够大且散列表未被填满,空的散列地址总能找到,并将纪录存入。
它的公式是:
f1(key)=keyMOD m
fi(key) = (f(key)+di) MOD m (di=1,2,3,...,m-1)
(2)举例:
求假如有关键字集合为{12,67,56,16,25,37,22,29,15,47,48,34},表长为12的哈希表。
a)取散列函数f(key)=key mod 12;
b)计算前5个数{12,67,56,16,25}时,都是没有冲突的散列地址,直接存入 ;
c)计算key=37时,与f(25)所在的位置冲突,故应用f(37)=((37mod12)+1) mod 12=2,即将37存入下标为2的位置。
.........![]()
★二次探测法
有些我们在处理冲突时,关键字所在的冲突位置后面没有空位置了,反而它的前面有一个空位置,尽管可以不断地求余数后得到结果,但是效率很差。因此我们可以改进di=1^2,-1^2,2^2,-2^2,....,q^2,-q^2,(q=
在冲突时,对于位移量di采用随机函数计算得到,则称为随机探测法。
fi(key)=(f(key)+di) MOD m(di是一个随机数列)
2.链地址法
将所有关键字为同义词的记录存储在一个单链表中,我们称这种表为同义词子表,在散列表中只存储所有同义词子表的头指针。链地址法实际上已经不存在什么冲突换址的问题,无论有多少个冲突,都只是在当前位置给单链表增加结点的问题。
链地址法对于可能会造成很多冲突的散列函数来说,提供了绝不会出现找不到地址的保障,当然,这也就带来了查找时需要遍历单链表的性能损耗。
3.公共溢出区法
即为所有冲突的关键字建立了一个公共的溢出区来存放。在查找时,对给定值通过散列函数计算出散列地址后,先与基本表的相应位置进行对比,如果相等,则查找成功;如果不想等,则到溢出表去进行顺序查找。如果相对于基本表而言,有冲突的数据很少的情况下,公共溢出区的结构对查找性能来说还是非常高的。
4.再散列函数法
对于散列表,可以事先准备多个散列函数,每当发生散列地址冲突时,就换一个散列函数计算,相信总会有一个散列函数可以把冲突解决。
fi(key)=RHi(key)(i=1,2,...,k) ,其中RHi就是不同的散列函数。
这种方法能够使得关键字不产生聚集,但会增加计算时间。
散列表查找实现
1.散列表查找算法实现
(1)散列表结构HashTable
功能:定义一个散列表的结构以及一些相关的常数
算法:
#define SUCCESS 1
#define UNSUCCESS 0
#define HASHSIZE 12 //定义散列表长为数组的长度
#define NULLKEY -32768
typedef struct
{
int *elem; //数据元素存储基址,动态分配数组
int count; //当前数据元素个数
}HashTable;
int m=0; //散列表表长,全局变量
(2)初始化散列表
Status InitHashTable(HashTable *H)
{
int i;
m=HASHSIZE;
H->count=m; //设置Hash表表长为12
H->elem=(int *)malloc(m*sizeof(int)); //为hash表开辟连续的存储空间
for(i=0;ielem[i]=NULLKEY;
return OK;
} 用于计算各个关键字在哈希表中的存储地址。
int Hash(int key)
{
return key % m; //除留余数数
}初始化完成后,我们可以对散列表进行插入操作,要判断冲突,如果发生冲突则需利用开发地址法的线性探测解决冲突。假设我们插入的关键字集合为{12,67,56,25,37,22,29,15,47,48,34}
/*插入关键字进散列表*/
void InsertHash(HashTable *H,int key)
{
int addr = Hash(key); //求散列地址
while(H->elem[addr]!=NULLKEY) //如果地址部位空,则冲突
addr=(addr+1)%m; //开发地址法的线性探测解决冲突
H->elem[addr]=key; //直到有空位后插入关键字
}如果散列表存在后,通过散列表查找要的记录
Status Search(HashTable H,int key,int *addr)
{
*addr = Hash(key); //先求要查新关键字的散列地址
while(H.elem[*addr] !=key) //如果该散列地址位置存在的值不等于关键字,则通过线性探测继续查找
{
*addr = (*addr+1)%m; //开放地址法的线性探测,查找下一个位置是否相等
if(H.elem[*addr]==NULLKEY||*addr==Hash(key))
{
return UNSUCCESS;//如果循环回到原点(*addr==Hash(key)),则说明关键字不存在
}
}
return SUCCESS; //查找成功
}散列表查找性能分析
如果没有冲突,散列查找的时间复杂度为O(1),是所有查找算法中效率最高的。但在实际应用中,冲突是不可避免的,散列查找的平均查找长度主要取决于如下因素:
1.散列函数是否均匀
散列函数的好坏直接影响着出现冲突的频繁程度,但由于不同的散列函数对同一组随机的关键字,产生冲突的可能性是相同的,因此,我们可以不考虑它对平均查找长度的影响。
2.处理冲突的方法
相同的关键字、相同的散列函数,但处理冲突的方法不同,会使得平均查找长度不同。比如线性探测处理冲突可能会产生堆积,显然就没有二次探测法好,而链地址法处理冲突不会产生任何堆积,因而具有更佳的平均查找性能。
3.散列表的装填因子
所谓的装填因子a=填入表中的记录个数/散列表长度,a标志着散列表的装满的程度。当填入表中的记录越多,a就越大,产生冲突的可能性就越大。散列表的平均查找长度取决于装填因子,而不是取决于查找集合中的记录个数。
为了使散列查找的时间复杂度达到O(1),我们需将散列表的空间设置得比查找集合大,虽然有点浪费空间,但是换来了高的查找效率。
11.二叉排序树算法
一、二叉排序树(提高查询、插入、删除速度-动态查找算法)
如果要查找的数据集是有序线性表且是顺序存储的,查找可以用顺序、折半、插值、斐波那契、线性索引(无序)等查找算法来实现。然后,由于有序,当我们在插入和删除操作上,就需要耗费大量的时间。下面将要学习的二叉排序树,就是一种既可以使得插入和删除效率不错,又可以比较高效率地实现查找的算法。为此,构造一棵二叉排序树的目的并不是为了排序,而是为了提供查找和插入删除关键字的速度。
1.二叉排序树概念
二叉排序树(Binary Sort Tree),又称为二叉查找树,或者是一棵空树,或者是具有下列性质的二叉树。
◆若它的左子树不空,则左子树上所有结点的值均小于它的根结构(双亲结点)的值;
◆若它的右子树不空,则右子树上所有结点的值均大于它的根结点(双亲结点)的值;
◆它的左、右子树也分别为二叉排序树。
2.二叉树结点结构
/*二叉树的二叉链表结点结构定义*/
typedef struct BiTNode //结点结构
{
int data; //结点数据
Struct BiTNode *lchild,*rchild; //左右孩子指针
}BiTNode,*BiTree; 1.典型实例分析
假如有一数据集合={62,88,58,47,35,73,51,99,37,93},查找的关键字key=93。
使用二叉排序树查找算法步骤如下:
①根据二叉排序树定义将该数据集合构造成一棵二叉排序树(中序遍历);

②调用二叉排序树查询算法SearchBST(*T,key,NULL,&p)查询关键字,其中,SearchBST函数是一个可递归运行的函数,参数T是一个二叉树链表、key代表要查询的关键字、二叉树f指向T的双亲。当T指向根结点时,f的初值就为NULL,它在递归时有用,最后的参数p是为了查找成功后可以得到查找到的结点位置。
③ if(!T){ .... }语句。用来判断当前二叉树是否到叶子结点,此时当前T指向根结点62的位置,由于T不为空,故该语句片段不执行。
④esle if(key==T->data)语句。即查找到相匹配的关键字执行语句,显然93!=62,故该语句片段不执行。
⑤else if(key
⑥else{....}语句。即当即当要查找关键字大于当前结点时执行语句,93>62,所以以递归调用SearchBST(T->rchild,key,T,p)。此时,T指向了62的右孩子88,f指向88的双亲结点,即62。如图:
⑦此时第二层SearchBST,因93比88大,所以执行else{....}语句,再次递归调用SearchBST(T->rchild,key,T,p)。此时T指向了88的右孩子99。

⑧此时第三层SearchBST,因93比99小,所以执行else if(key
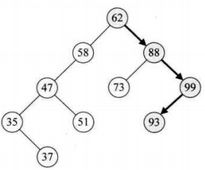
⑨第四层SearchBST,因key等于T->data,所以执行第10~11行,此时指针p指向93所在的结点并返回True到第三层、第二层、第一层,最终返回函数True。
总结:递归查找二叉排序树T中是否存在key, 指针f指向T的双亲,其初始调用值为NULL。若查找成功,则指针p指向该数据元素结点,并返回TRUE;否则指针p指向查找路径上访问的最后一个结点并返回FALSE*。
2.Java插入与查找操作实现
public class BinaryTree{
int data; //相当于C代码中的数据域数据
BinaryTree left; //相当于C代码中的指针域指针变量
BinaryTree right;
/*1.构造方法:初始化成员变量*/
public BinaryTree(int data){
this.data = data;
left = null;
right = null;
}
/*2.二叉排序树的查找操作*/
public boolean searchKey(BinaryTree rootObj,int key){
//边界检查
if(root==null)
return false;
if(rootObj.data==key) //rootObj的data值相等key,查找成功
return true;
else if(rootObj.data < key) //rootObj的data值小于key,向右继续查找
return searchKey(rootObj.right,key);
else
return searchKey(rootObj.left,key);
}
}
/*3.二叉排序树的插入结点*/
public void insertTree(BinaryTree rootObj,int data){
if(root.data<=data){
if(rootObj.right == null)
rootObj.right = new BinaryTree(data);
else
insertTree(rootObj.right,data);
}else{
if(rootObj.left == null)
rootObj.left = new BinaryTree(data);
else
insertTree(rootObj.left,data);
}
}二叉排序树是以链接的方式存储,保持了链接存储结构在执行插入或删除操作时不用移动元素的优点,只要找到合适的插入和删除位置后,仅需修改链接指针即可。插入删除的时间性能比较好,而对于二叉排序树的查找,走的就是从根结点到要查找的结点的路径,其比较次数等于给定值的结点在二叉排序树的层数。极端情况,最少为1次,即跟结点就是要找的结点,最多也不会超过树的深度,即二叉排序树的查找性能取决于二叉排序树的形状。