【Semantic Segmentation】语义分割综述 -- Attention
【Semantic Segmentation】语义分割综述 -- Attention
- Attention
- [Attention U-Net] Learning Where to Look for the Pancreas( MIDL 2018)
- [PAN] Pyramid Attention Network for Semantic Segmentation (BMVC 2018)
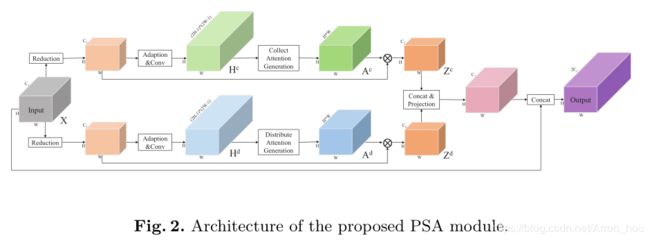
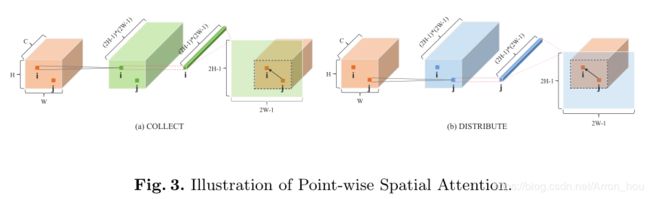
- [PSANet] Point-wise Spatial Attention Network for Scene Parsing (ECCV 2018)
- [EncNet] Context Encoding for Semantic Segmentation (CVPR 2018)
- [DANet] Dual Attention Network for Scene Segmentation 2018-09 (CVPR 2019)
- [EMANet] Expectation-Maximization Attention Networks for Semantic Segmentation (2019 ICCV oral)
Attention
语义分割的核心是通过像素周围语义信息,去判定当前像素的类别。比如说在某一个区域,检测到是指猫,但是增大感受野之后,发现这只猫是一个人T-shirt上的图案,那么这只猫的所有像素就应该分类为人。
上述的方法都是在研究感受野如何增加,可以更好的获取某一个区域的语义。但是可想而知,在深度神经网络,前面感受野较小,后面感受野较大,在信息流通的过程中,浅层的神经网络并不确切第知道某一个区域应该是什么,例如是猫还是人,需要信息逐渐传到后面,才能得以确认。
受限于原始卷积操作的结构,感受野必然受限于局部的信息,对于远端的信息融合能力不够,例如一个车和船比较像,在湖中,我们就直接推断这是一个船,在路上我们就推断这是一个车。
模型就算足够深,获得了更大的感受野,但是任然不能解决,长距离依赖的问题,而且要考虑到之后上采样,或者转置卷积为原始的图片大小,空间信息不能丢失太多,一般下采样的倍数控制到16或者32倍。
注意力机制可以在encoder 的过程中就考虑到长距离的信息,进行信息融合。可以改变上述局部感受野的问题。
前置阅读
核心的Attention机制 例如 channel-wise 的SeNet 以及 pixel-wise 的 Non-local Neural Network
【Attention】注意力机制在图像上的应用
[Attention U-Net] Learning Where to Look for the Pancreas( MIDL 2018)
https://arxiv.org/abs/1804.03999

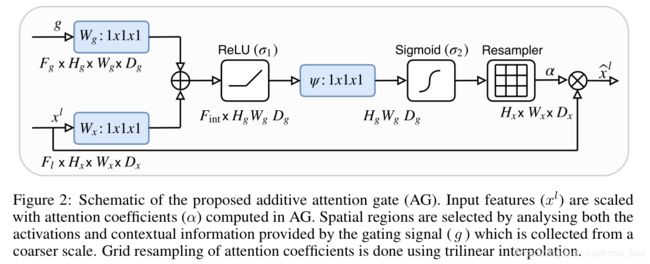
[PAN] Pyramid Attention Network for Semantic Segmentation (BMVC 2018)
https://arxiv.org/abs/1805.10180v1
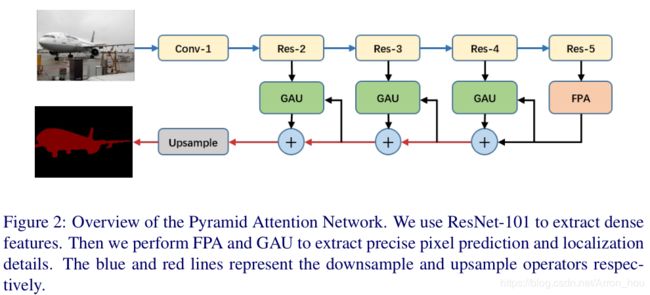
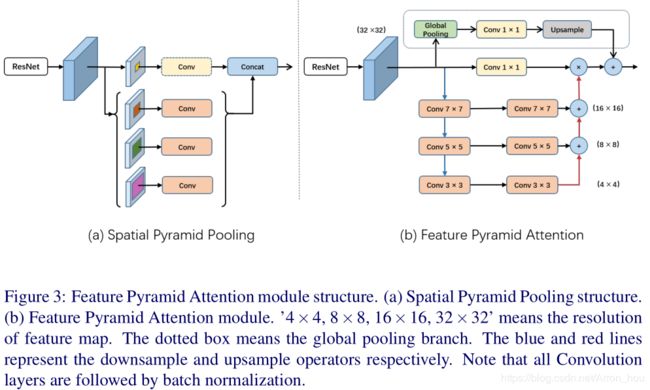
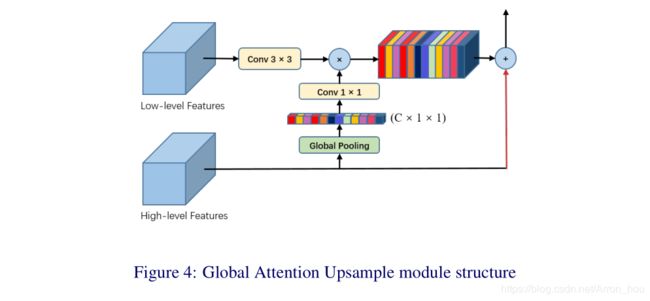
[PSANet] Point-wise Spatial Attention Network for Scene Parsing (ECCV 2018)
商汤及联合实验室
https://hszhao.github.io/projects/psanet/
https://hszhao.github.io/papers/eccv18_psanet.pdf
[EncNet] Context Encoding for Semantic Segmentation (CVPR 2018)
https://arxiv.org/abs/1803.08904v1

[DANet] Dual Attention Network for Scene Segmentation 2018-09 (CVPR 2019)
https://arxiv.org/abs/1809.02983
pam结构
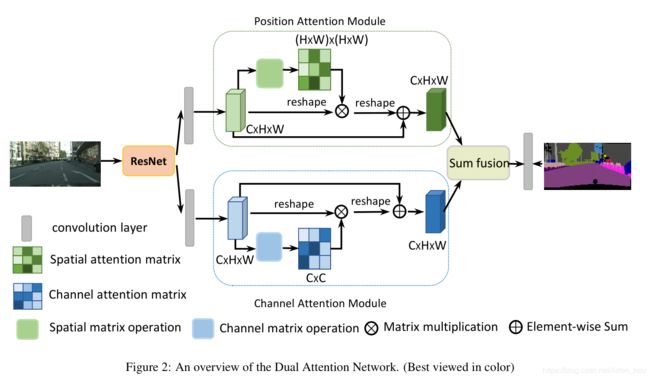
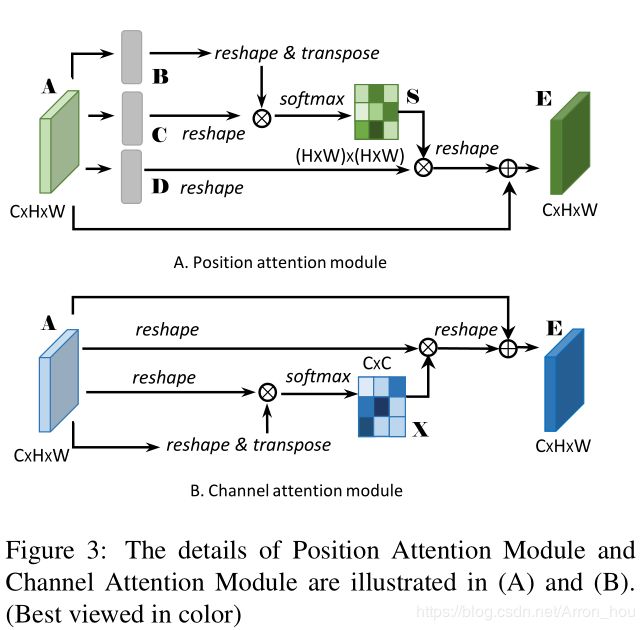
class PAM_Module(Module):
""" Position attention module"""
# Ref from SAGAN
def __init__(self, in_channels):
super(PAM_Module, self).__init__()
inter_channels = in_channels // 8
self.query_conv = Conv2d(in_channels, inter_channels, kernel_size=1)
self.key_conv = Conv2d(in_channels, inter_channels, kernel_size=1)
self.value_conv = Conv2d(in_channels, in_channels, kernel_size=1)
self.gamma = Parameter(torch.zeros(1))
self.softmax = Softmax(dim=-1)
def forward(self, x):
"""
inputs :
x : input feature maps( B,C,H,W)
returns :
out : attention value + input feature
attention: B,(HxW),(HxW)
"""
B, C, H, W = x.size()
# query (B,WH,C//8)
query = self.query_conv(x).reshape(B, -1, H * W).permute(0, 2, 1)
# key (B,C//8,HW)
key = self.key_conv(x).reshape(B, -1, H * W)
# value (B,C,HW)
value = self.value_conv(x).reshape(B, -1, H * W)
# energy (B,WH,WH)
energy = torch.bmm(query, key)
# attention (B,WH,WH)
attention = self.softmax(energy)
# print(attention[0][0]) #[0.1114, 0.1236, 0.1127, 0.1003, 0.1041, 0.1065, 0.1078, 0.1163, 0.1173]
# print(sum(attention[0][0])) # 1
# out (B,C,WH)
out = torch.bmm(value, attention)
# out = torch.bmm(value, attention.permute(0, 2, 1))
# out (B,C,W,H)
out = out.reshape(B, C, H, W)
out = self.gamma * out + x
return out
cam结构
class CAM_Module(Module):
""" Channel attention module"""
def __init__(self, in_dim):
super(CAM_Module, self).__init__()
self.chanel_in = in_dim
self.gamma = Parameter(torch.zeros(1))
self.softmax = Softmax(dim=-1)
def forward(self, x):
"""
inputs :
x : input feature maps (B,C,H,W)
returns :
out : attention value + input feature
attention: (B,C,C)
"""
B, C, H, W = x.size()
# query (B,C,HW)
query = x.reshape(B, C, -1)
# key (B,HW,C)
key = x.reshape(B, C, -1).permute(0, 2, 1)
# value (B,C,HW)
value = x.reshape(B, C, -1)
# energy (B,C,C)
energy = torch.bmm(query, key)
energy = torch.max(energy, -1, keepdim=True)[0].expand_as(energy) - energy
attention = self.softmax(energy)
out = torch.bmm(attention, value)
out = out.reshape(B, C, H, W)
out = self.gamma * out + x
return out
整体网络
import torch
import torch.nn as nn
from .nn.attention import PAM_Module, CAM_Module
def conv2d(in_channels, out_channels, norm_layer):
return nn.Sequential(nn.Conv2d(in_channels, out_channels, 3, padding=1, bias=False),
norm_layer(out_channels),
nn.ReLU(inplace=True))
def dropout_conv1x1(in_channels, out_channels):
return nn.Sequential(nn.Dropout2d(0.1, False),
nn.Conv2d(in_channels, out_channels, 1))
class DANet(nn.Module):
def __init__(self, in_channels, out_channels, norm_layer=nn.BatchNorm2d):
super(DANet, self).__init__()
assert in_channels >= 32
inter_channels = in_channels // 4
# pam
self.pam_conv1 = conv2d(in_channels, inter_channels, norm_layer)
self.pam = PAM_Module(inter_channels)
self.pam_conv2 = conv2d(inter_channels, inter_channels, norm_layer)
self.pam_conv3 = dropout_conv1x1(inter_channels, out_channels)
# cam
self.cam_conv1 = conv2d(in_channels, inter_channels, norm_layer)
self.cam = CAM_Module(inter_channels)
self.cam_conv2 = conv2d(inter_channels, inter_channels, norm_layer)
self.cam_conv3 = dropout_conv1x1(inter_channels, out_channels)
self.fusion_conv = dropout_conv1x1(inter_channels, out_channels)
def forward(self, x):
p = self.pam_conv1(x)
p = self.pam(p)
p = self.pam_conv2(p)
c = self.cam_conv1(x)
c = self.cam(c)
c = self.cam_conv2(c)
pa = p + c
pa = self.fusion_conv(pa)
p = self.pam_conv3(p)
c = self.cam_conv3(c)
output = []
output.append(pa)
output.append(p)
output.append(c)
return tuple(output)
[EMANet] Expectation-Maximization Attention Networks for Semantic Segmentation (2019 ICCV oral)
https://arxiv.org/abs/1907.13426
EMANet 是一个十分有意义的工作。attention 机制的有效性在上述论文中都有体现。但是图像attention机制(non local)的实现往往需要进行若干次矩阵相乘运算,会导致极高的计算量 O ( N 2 C ) O(N^2C) O(N2C),这也是attention在工业界很少出现的原因所在。EMANet通过EM算法迭代近似non local,将计算量前置到训练时,提高了部署后的推理速度,并且也是一种传统机器学习算法于深度学习完美结合的一个典范。

详细介绍见下,一作李夏讲解。
[用Attention玩转CV,一文总览自注意力语义分割进展] https://mp.weixin.qq.com/s?__biz=MzA3MzI4MjgzMw==&mid=2650768770&idx=3&sn=aec7b055da21a94999adac0ce45dfe01&chksm=871a41fcb06dc8ead45b8b99a7b9bc59aedc64373a45f781db00f528e029a7c861e95f8094c0&token=310258758&lang=zh_CN#rd
[论文一作中文讲解 解读北大提出的期望最大化注意力网络EMANet] https://mp.weixin.qq.com/s?__biz=MzA3MzI4MjgzMw==&mid=2650768486&idx=4&sn=8dd39c05a69021007f8f2d9ccae5ffb6&chksm=871a4018b06dc90e5ef9320dc9a032a92e7a609a34765ea37f6eacd7382b2f93b23d3f51f717&scene=21#wechat_redirect
[github] github.com/XiaLiPKU/EMANet