jieba-基于 TF-IDF 算法的关键词抽取
jieba-基于 TF-IDF 算法的关键词抽取
通过上述三篇文章的介绍(详见其他的博客),接下来将对TF-IDF算法的实现进行介绍。
- jieba.analyse.extract_tags(sentence, topK=20, withWeight=False, allowPOS=())
- sentence 为待提取的文本
- topK 为返回几个 TF/IDF 权重最大的关键词,默认值为 20
- withWeight 为是否一并返回关键词权重值,默认值为 False
- allowPOS 仅包括指定词性的词,默认值为空,即不筛选
- jieba.analyse.TFIDF(idf_path=None) 新建 TFIDF 实例,idf_path 为 IDF 频率文件
关键词提取的代码如下:
import sys
sys.path.append('../')
import jieba
import jieba.analyse
from optparse import OptionParser
USAGE = "usage: python extract_tags.py [file name] -k [top k]"
parser = OptionParser(USAGE)
parser.add_option("-k", dest="topK")
opt, args = parser.parse_args()
if len(args) < 1:
print(USAGE)
sys.exit(1)
file_name = args[0]
if opt.topK is None:
topK = 10
else:
topK = int(opt.topK)
content = open(file_name, 'rb').read()
tags = jieba.analyse.extract_tags(content, topK=topK)
print(",".join(tags))
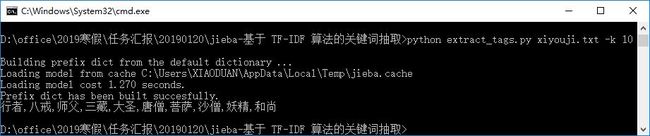
测试样本为《西游记》的TXT文件(后续代码的测试样本都是基于此文本进行测试,不再进行说明),在命令行中输入如下语句:
python extract_tags.py xiyouji.txt -k 10
所得结果如下所示:
1.关键词提取所使用逆向文件频率(IDF)文本语料库可以切换成自定义语料库的路径
-
用法: jieba.analyse.set_idf_path(file_name) # file_name为自定义语料库的路径
-
自定义语料库示例:

-
代码如下:
import sys sys.path.append('../') import jieba import jieba.analyse from optparse import OptionParser USAGE = "usage: python extract_tags_idfpath.py [file name] -k [top k]" parser = OptionParser(USAGE) parser.add_option("-k", dest="topK") opt, args = parser.parse_args() if len(args) < 1: print(USAGE) sys.exit(1) file_name = args[0] if opt.topK is None: topK = 10 else: topK = int(opt.topK) content = open(file_name, 'rb').read() jieba.analyse.set_idf_path("../jieba-基于 TF-IDF 算法的关键词抽取/idf.txt.big"); tags = jieba.analyse.extract_tags(content, topK=topK) print(",".join(tags))在命令行中输入如下代码:
python extract_tags_idfpath.py xiyouji.txt -k 10所得结果如下所示:

2.关键词提取所使用停止词(Stop Words)文本语料库可以切换成自定义语料库的路径
-
用法: jieba.analyse.set_stop_words(file_name) # file_name为自定义语料库的路径
-
自定义语料库示例(注:字典采用utf-8的编码格式):
-
代码如下:
import sys sys.path.append('../') import jieba import jieba.analyse from optparse import OptionParser USAGE = "usage: python extract_tags_stop_words.py [file name] -k [top k]" parser = OptionParser(USAGE) parser.add_option("-k", dest="topK") opt, args = parser.parse_args() if len(args) < 1: print(USAGE) sys.exit(1) file_name = args[0] if opt.topK is None: topK = 10 else: topK = int(opt.topK) content = open(file_name, 'rb').read() jieba.analyse.set_stop_words("../extra_dict/stop_words.txt") jieba.analyse.set_idf_path("../extra_dict/idf.txt.big"); tags = jieba.analyse.extract_tags(content, topK=topK) print(",".join(tags))在命令行中输入代码:
python extract_tags_stop_words.py xiyouji.txt -k 10所得结果如下所示:

3.关键词一并返回关键词权重值
-
代码如下:
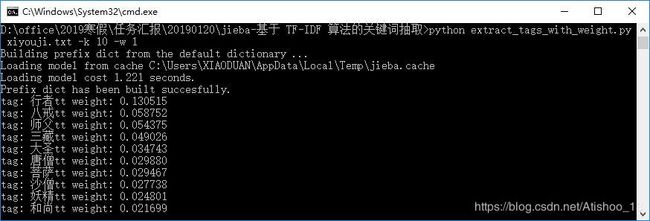
import sys sys.path.append('../') import jieba import jieba.analyse from optparse import OptionParser USAGE = "usage: python extract_tags_with_weight.py [file name] -k [top k] -w [with weight=1 or 0]" parser = OptionParser(USAGE) parser.add_option("-k", dest="topK") parser.add_option("-w", dest="withWeight") opt, args = parser.parse_args() if len(args) < 1: print(USAGE) sys.exit(1) file_name = args[0] if opt.topK is None: topK = 10 else: topK = int(opt.topK) if opt.withWeight is None: withWeight = False else: if int(opt.withWeight) is 1: withWeight = True else: withWeight = False content = open(file_name, 'rb').read() tags = jieba.analyse.extract_tags(content, topK=topK, withWeight=withWeight) if withWeight is True: for tag in tags: print("tag: %stt weight: %f" % (tag[0],tag[1])) else: print(",".join(tags))在命令行中输入代码:
python extract_tags_with_weight.py xiyouji.txt -k 10 -w 1(1为显示权重值,0为不显示权重值)
所得结果如下所示: