机械学习与R语言--Naive Bayes 朴素贝叶斯在R语言中的实现
为什么天气预报说70%概率下雨?为什么垃圾短信垃圾邮件被自动归类?这一切的基础算法便是朴素贝叶斯理论(算法有很多,这仅是其中之一)。
1.由贝叶斯理论到朴素贝叶斯(naive bayes)
理论的基础我就不讲了,我讲一下两个理论的区别。原本贝叶斯理论用来处理上述事件是很好的,但是由于贝叶斯理论在计算条件概率时,即在B发生的情况下A发生的概率,并不能简单的等同于A的概率而是![]() . 除非A B互为独立事件,才能直接等于P(A)。 如果我们直接把这个理论应用在R里面,似乎没啥问题。但是如果并不是简单的AB两个事件,而是ABCD...E+++这会导致算法量激增而计算机负担加重。通过实践认知,即使贝叶斯理论的独立假设被违背时,朴素贝叶斯还是很容易生效的,因此,为了简便,相比于贝叶斯理论,我们有很大倾向性使用朴素贝叶斯.
. 除非A B互为独立事件,才能直接等于P(A)。 如果我们直接把这个理论应用在R里面,似乎没啥问题。但是如果并不是简单的AB两个事件,而是ABCD...E+++这会导致算法量激增而计算机负担加重。通过实践认知,即使贝叶斯理论的独立假设被违背时,朴素贝叶斯还是很容易生效的,因此,为了简便,相比于贝叶斯理论,我们有很大倾向性使用朴素贝叶斯.
2.导入数据
我们以 sms_spam.csv 为例子,这是一个短信的例子,每天我们的手机都会收到各式各样的短信,有一些是朋友发来的,也有所谓的‘垃圾短信’,其中包含着广告,推销之类的主题。 垃圾短信是否拥有什么共同的特质,如包含链接?或者是 包含某些特征词(free, congratulations...) , 我们相信,同一类事务会拥有某个或者某些可以被发现的特征。 应运而生,我们有发现这些特征并评价这些特征的算法产生, NAIVE BAYES 便是其中之一。
# read the sms data into the sms data frame
sms_raw <- read.csv("sms_spam.csv", stringsAsFactors = FALSE,encoding='UTF-8')
# convert spam/ham to factor.
sms_raw$type <- as.factor(sms_raw$type)
# examine the type variable more carefully
str(sms_raw$type)
#Factor w/ 3 levels "All done, all handed in. Don't know if mega shop in asda counts as celebration but thats what i'm doing!",..: 2 2 2 3 3 2 2 2 3 2 ...
table(sms_raw$type)在 sms_spam.csv 中,我们可以看到数据大概是这样子的(实际上你应该在读入R之前就先打开excel看看数据)

这是一个非常简单的数据,2个Variables,Type应该由ham和spam组成。但是仔细观察str(sms_raw$text)的结果,你会发现levels是3(想想,这是不合理的,数据集我是从guthub上直接保存下来的)。进一步,我们看看问题出在哪里?
> summary(sms_raw)
type
All done, all handed in. Don't know if mega shop in asda counts as celebration but thats what i'm doing!: 1
ham :4811
spam : 747
text
Length:5559
Class :character
Mode :character
#find where it is
which(sms_raw$type=="All done, all handed in. Don't know if mega shop in asda counts as celebration but thats what i'm doing!")
#1072我们发现问题出在1072行(也许你的数据集风平浪静,不会出现这样的问题)
![]()

无论是出于何种原因(我理解为解码问题),原本应该在1072行 第一列的 ham(少了一行是因为csv文档里面由headers占了一行),被弄到了上一行的(urgent please balabala)的末尾。 显然,这一行的值不能作为一个独特的TYPE,于是我们可以简单地删除,也可以修正这一行。我选择了修正
#restore
sms_raw$text[1072]<-as.character(sms_raw$type[1072])
sms_raw$type[1072]<- "ham"
sms_raw$type <- factor(sms_raw$type)继续
在这样的一个数据结构中, 会发现 spam的数据有747个, ham有4812个(数据本身有形状,并非55分)。同时会发现,短信会包含很多东西,如标点符号(,。等),空格(1个或者多个),不规范用语等,这些都是我们可能需要处理的。
# build a corpus using the text mining (tm) package
library(tm)
sms_corpus <- VCorpus(VectorSource(sms_raw$text))
print(sms_corpus)
'''
<>
Metadata: corpus specific: 0, document level (indexed): 0
Content: documents: 5559
'''
inspect(sms_corpus[1:2])
'''
<>
Metadata: corpus specific: 0, document level (indexed): 0
Content: documents: 2
[[1]]
<>
Metadata: 7
Content: chars: 49
[[2]]
<>
Metadata: 7
Content: chars: 23
'''
as.character(sms_corpus[[1]])
#[1] "Hope you are having a good week. Just checking in" 使用一些function来查看数据,要查看实际的短信内容,as.character 是比较实用的。
3.清洗数据
长路漫漫,数据作伴。 清洗数据永远都会占掉你大把时间。 对于这种字符型数据,我们可以先把大小写统一,标点符号去掉,甚至是处理过去式,过去分词等
# clean up the corpus using tm_map()
sms_corpus_clean <- tm_map(sms_corpus, content_transformer(tolower))
# show the difference between sms_corpus and corpus_clean
as.character(sms_corpus[[1]])
as.character(sms_corpus_clean[[1]])
sms_corpus_clean <- tm_map(sms_corpus_clean, removeNumbers) # remove numbers
sms_corpus_clean <- tm_map(sms_corpus_clean, removeWords, stopwords()) # remove stop words
# tip: create a custom function to replace (rather than remove) punctuation
removePunctuation("hello...world")
replacePunctuation <- function(x) { gsub("[[:punct:]]+", " ", x) }
replacePunctuation("hello...world")
#sms_corpus_clean <- tm_map(sms_corpus_clean, removePunctuation)
sms_corpus_clean <- tm_map(sms_corpus_clean, content_transformer(replacePunctuation))
# replace punctuation with blank
# illustration of word stemming
library(SnowballC)
wordStem(c("learn", "learned", "learning", "learns"))
sms_corpus_clean <- tm_map(sms_corpus_clean, stemDocument)
sms_corpus_clean <- tm_map(sms_corpus_clean, stripWhitespace) # eliminate unneeded whitespace
# examine the final clean corpus
lapply(sms_corpus[1:3], as.character)
lapply(sms_corpus_clean[1:3], as.character)以上步骤看似复杂,但属于对于一些文本数据的常规清洗。
题外话:
有时候我们会担心 sms_corpus_clean <- tm_map(sms_corpus_clean, removePunctuation) # remove punctuation这一步,因为这会使得hello,world 简单地变为helloworld。 这也许不是我们希望的样子,所以我自定义了一个replacePunctuation 的方程,如下(上面亦有写出):
# tip: create a custom function to replace (rather than remove) punctuation
removePunctuation("hello...world")
replacePunctuation <- function(x) { gsub("[[:punct:]]+", " ", x) }
replacePunctuation("hello...world")本质上这是使用了gsub的原理,用空格‘ ’代替了所有符号。 上诉例子就会变成hello world. 同时细心的你会发现,我在使用tm_map的时候,里面的argument有一些直接使用了方程名字如: removeNumbers 而有一些却变成了content_transformer(tolower)。那是因为本质上我们的data已经不是dataframe的形式,而是转换成了语料库(corpus),而removeNumbers是 tm包里专门针对这一datatype而带的方程,tolower却不是,所以要使用这个方程,必须加上content_transformer()来调用,是tolower作为变换函数来访问语料库,包括我们的自创方程replacePunctuation。
题外话结束
到这里清洗就差不多了(有特殊需求特殊处理),那么多的词,分布在那么多句子里,有些词出现了N次,有些词出现了1次。归根结底,每一个句子里面出现的词的数量,占总共词数量比例是很小的。这时候你想到了什么储存方式?没错,稀疏矩阵。正如你猜想的一样,R里面已经有了建立稀疏矩阵的function(万幸,不需要我们自己去定义),稀疏矩阵也可以大大减小我们的储存空间哦,你可以注意一下sms_dtm与原本的corpus大小。
# create a document-term sparse matrix
sms_dtm <- DocumentTermMatrix(sms_corpus_clean)
#summary
inspect(sms_dtm)
sms_dtm4.训练数据测试数据准备
# creating training and test datasets
set.seed(1)
temp<- sample(sms_dtm$nrow, round(0.75*sms_dtm$nrow),replace = F)
sms_dtm_train<- sms_dtm[temp,]
sms_dtm_test<- sms_dtm[-temp,]
# also save the labels
sms_train_labels <- sms_raw[temp, ]$type
sms_test_labels <- sms_raw[-temp, ]$type
# check that the proportion of spam is similar
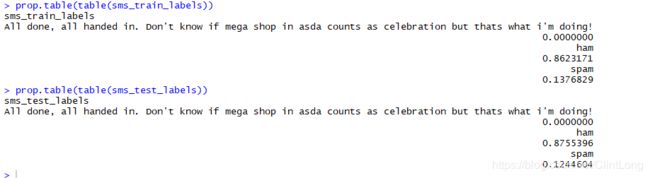
prop.table(table(sms_train_labels))
prop.table(table(sms_test_labels))我们随机切割了cleaned data,呈现的结果如下:
5.分析数据
我们可以对数据有一个初步的认知(外观上的),wordcloud恰巧可以满足这一点。
# word cloud visualization
library(wordcloud)
wordcloud(sms_corpus_clean, min.freq = 50, random.order = FALSE) 
这是一个非常头疼的wordcloud,即使我们已经做过很多努力去转换清洗数据,依然会有 类似于happi(你可以想象它是有happiness变来的),sorri,reply这样的词出现在我们的词云中,这也许是不可避免的(或许不去处理词干wordstem也是不错的选择?)。 有那么多词是高频的(50+),而整个数据里面有超过6000个terms。 在这些terms中,比然有一些是低频词,它们也许出现次数少,也许出现在某一条或者几条特定的短信中,这些数据我们最好是预先处理掉。
#remove words that are less than 0.1% of total words
sms_dtm_freq_train <- removeSparseTerms(sms_dtm_train, 0.999)
sms_dtm_freq_train
# save frequently-appearing terms to a character vector
sms_freq_words <- findFreqTerms(sms_dtm_train, 5)
str(sms_freq_words)
# create DTMs with only the frequent terms
sms_dtm_freq_train <- sms_dtm_train[ , sms_freq_words]
sms_dtm_freq_test <- sms_dtm_test[ , sms_freq_words]记住,无论是removeSparseTerms 还是 findFreqTerms,我们都没有改变或者删除行,我们只是减少了列(这点很重要,因为我们之前保存了每一行对应的labels【是Spam还是ham】,这需要一一对应)
稀疏矩阵是一个带有数值的矩阵,而实际上Naive bayes需要的只是这个词干在这一条短信中是否出现过(Y/N),于是我们可以创建一个转换方程,将矩阵中的数字转换成我们需要的Y/N。同时将DocumentTermMatrix转变为普通的matrix以方便后续建模。

# convert counts to a factor
convert_counts <- function(x) {
x <- ifelse(x > 0, "Yes", "No")
}
# apply() convert_counts() to columns of train/test data
sms_train <- apply(sms_dtm_freq_train, MARGIN = 2, convert_counts)
sms_test <- apply(sms_dtm_freq_test, MARGIN = 2, convert_counts)
6.应用朴素贝叶斯模型
library(e1071)
sms_classifier <- naiveBayes(sms_train, sms_train_labels,laplace=0)
## Step 4: Evaluating model performance ----
sms_test_pred <- predict(sms_classifier, sms_test)
library(gmodels)
CrossTable(sms_test_pred, sms_test_labels,
prop.chisq = FALSE, prop.t = FALSE, prop.r = FALSE,
dnn = c('predicted', 'actual'))
结果不错。不幸的是,有7条短信被错误的归类为垃圾短信(这可不好),我们需要思考为什么会发生(有可能是数据本身错误,也有可能是有些参数调整不佳)。实际上,只要我们想,是可以大大降低这个数量的(也许需要牺牲一点总体准确率)
比如我们可以试着在laplace这个参数上做文章,如果某个词A在training set中,都出现在垃圾短信(spam)中(这也是我们为什么会去剔除低频词,我们不希望那些只出现少量的词影响模型),但这不意味着 有词A的短信都是垃圾短信(尽管有时候他们确实是),于是我们尝试改变laplace参数:
## Step 5: Improving model performance ----
sms_classifier2 <- naiveBayes(sms_train, sms_train_labels, laplace = 1)
sms_test_pred2 <- predict(sms_classifier2, sms_test)
CrossTable(sms_test_pred2, sms_test_labels,
prop.chisq = FALSE, prop.t = FALSE, prop.r = FALSE,
dnn = c('predicted', 'actual')) 
得到了一个好一点点的结果,这个值由7->6, 尽管另一个值由17->20(预测是ham但实际是spam)。不同的模型针对不同的需求,这两个都不失为可选的模型,因为总体预测准确率都很高。