计算机视觉学习--目标检测算法分类
基于深度学习的目标检测算法主要分为两类:
1 two stage:
先进行区域生成(一个可能包含待检测物体的预选框),在通过卷积神经网络进行样本分类。
常见的算法:R-CNN SPP-Net Fast R-CNN R-FCN Faster R-CNN等
2 one stage:
不用RP,直接在网络中提取特征来预测物体的分类和位置
常见的算法:YOLOv1 YOLOV2 YOLOV3 SSD 等
R-CNN介绍:
创新点:使用CNN 对region proposal 计算feature vectors 。从经验驱动特征(SIFT,HOG),到数据驱动特征
大样本下有监督训练,和小样本微调的方法,解决过拟合问题

后来因为这个算法过于冗杂(每个候选区域都要进行卷积),又提出了fast Rcnn,其创新点在于:
1 只对整副图像进行一次特征提取(称作 shared feature map),避免rcnn的冗余
2 用ROl pooling 层替换掉maxpooling ,巧妙的解决了尺度缩放的问题
3 末尾采用的是并行不通的全连接层,可同时输出分类结果
4 输出是多个batch vector,其中batch的值等个roi的个数,vector 大小为 channel*w*h ,ROL pooling 作用就是讲一个个大小不用的box框,映射成大小固定的
不足之处:
候选区域提取仍然采用selective search,整个检测流程大多消耗在这上面。之后的faster rcnn的改进之处便是针对这一点。
它用深层网络代替了候选框的方法,新的网络在生成ROI效率更高。

两者的对比,RPN将第一个卷积网络的输出特征图作为输入,它在特征图上滑动一个3*3的卷积核,构建与类别无关的候选区域,如下图所示:

这个网络最后会输出256个值,并送入两个单独的全连接层,以预测边界框和两个objectness分数,这个两个分数度量了边界框是否包含目标。
one stage 目标检测算法:
这里介绍代表性的一个YOLO(you only look once )系列算法:
其创新点在于:
1:将整张图作为输入,直接在输出层回归bounding box的位置和所属类别
2:速度快,one stage detection的开山之作
之前的物体检测方法都是首先需要产生大量可能包含带检测物体的先验框,然后用分类器判断每个先验框对应的边界框是否包含待检测物体,以及物体的类别和可致信度,还要修理边界框,最后基于一些准则,过滤掉置信度不高的框,这种基于先产生候选区在检测的方法,虽然有较高的检测率。但是运行速度较慢。
YOLO创造性的将物体检测任务当做回归任务,将候选区和检测两个阶段合二为一,事实上,YOLO也并没有真正的去掉候选区,而是直接将输入图片划分成7x7=49个网格,每个网格预测两个边界框,一共预测49x2=98个边界框。可以近似理解为在输入图片上粗略的选取98个候选区,这98个候选区覆盖了图片的整个区域,进而用回归预测这98个候选框对应的边界框。
网络结构如图所示:
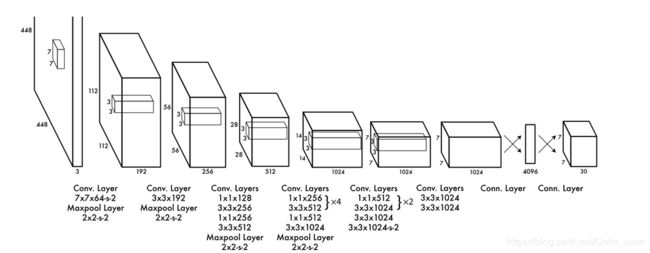
卷积层提取图像特征,两个全连接层,预测图像位置和类别概率值。
特点:
1 有全连接层,所以要求输入图像尺寸固定
2 采用非极大值抑制算法
3 定位不准确
改进算法:目前流行的算法YOLOV3,
1 使用残差模型(最好的是Darknet-53),进一步加深了网络结构,另一个使用FPN,架构,实现多尺度的检测。
这种one stage 的检测器。对类别不均衡的问题比较敏感,因为没有RPN阶段。但是优点是速度快
人脸检测是目标检测分支中一个比较特殊的领域,虽然通用的目标检测算法也可以应用在人脸检测领域,但是和专门的人脸检测算法还是有些差别的,比如 基于级联卷积神经网络,基于多任务卷积神经网络,很大程度上提高了检测的鲁棒性。
常用的目标检测数据集
PASCAL VOC
MS COCO
IMAGENET