使用ORM框架我们更多的是使用其查询功能,那么查询海量数据则又离不开性能,那么这篇中我们就看下mybatis高级应用之延迟加载、一级缓存、二级缓存。使用时需要注意延迟加载必须使用resultMap,resultType不具有延迟加载功能。
一、延迟加载
延迟加载已经是老生常谈的问题,什么最大化利用数据库性能之类之类的,也懒的列举了,总是我一提到延迟加载脑子里就会想起来了Hibernate get和load的区别。OK,废话少说,直接看代码。 先来修改配置项xml。
注意,编写mybatis.xml时需要注意配置节点的先后顺序,settings在最前面,否则会报错。
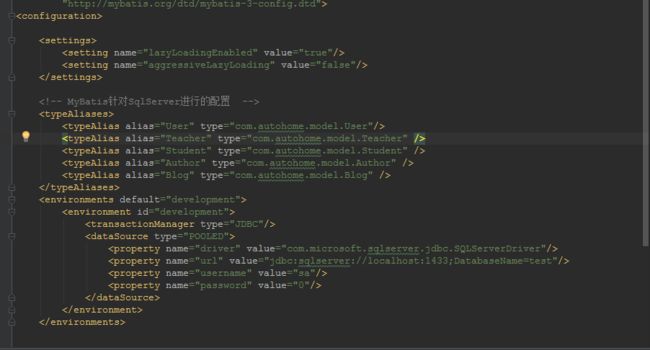
前面提到延迟加载只能通过association、collection来实现,因为只有存在关联关系映射的业务场景里你才需要延迟加载,也叫懒加载,也就是常说的用的时候再去加载。OK,那么我们来配一个association来实现:
我来编写一个加载博客列表的同时加载出博客额作者, 主要功能点在id为blogAuthorResumtMap这个resultmap上,其中使用了association,关键点是它的select属性,该属性也就是你需要懒加载调用的statment id。 当然需要懒加载的statement 返回值当然是resultmap
OK,来看测试结果:
@Test
public void getBlogAuthorByLazyloading(){
SqlSession sqlSession=null;
try{
sqlSession=sqlSessionFactory.openSession();
List list = sqlSession.selectList("com.autohome.mapper.Author.selectBlogAuthor");
for (Blog blog:list) {
System.out.println("id:"+blog.getId()+",title:"+blog.getTitle()+",category:"+blog.getCategory());
System.out.println("author:"+blog.getAuthor().getName());
}
}catch(Exception e){
e.printStackTrace();
}finally {
sqlSession.close();
}
}
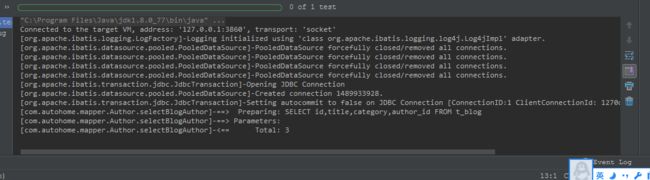
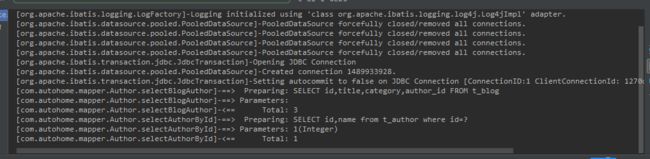
从图一中看出,执行selectBlogAuthor返回List
二、一级缓存
了解缓存前我们先看一张图片(图片来源于传智播客视频图片)。从图中可以了解一级缓存是sqlsession级别、二级缓存是mapper级别。在操作数据库时我们需要先构造sqlsession【默认实现是DefaultSqlSession.java】,在对象中有一个数据结构【hashmap】来存储缓存数据。不同的sqlsession区域是互不影响的。 如果同一个sqlsession之间,如果多次查询之间执行了commit,则缓存失效,mybatis避免脏读。

OK,在看mybatis一级缓存时,我总是觉的一级缓存有点鸡肋,两个查询如果得到一样的数据,你还会执行第二次么,果断引用第一次的返回值了。 可能还没了解到一级缓存的奥妙之处。一级缓存默认是开启的,不需要额外设置,直接使用。
public void testCache(){
SqlSession sqlSession=null;
try{
sqlSession=sqlSessionFactory.openSession();
Author author = sqlSession.selectOne("com.autohome.mapper.Author.selectAuthorById",1);
System.out.println("作者信息 id:"+author.getId()+",name:"+author.getName());
author = sqlSession.selectOne("com.autohome.mapper.Author.selectAuthorById",1);
System.out.println("作者信息2 id:"+author.getId()+",name:"+author.getName());
}catch(Exception e){
e.printStackTrace();
}finally {
sqlSession.close();
}
}
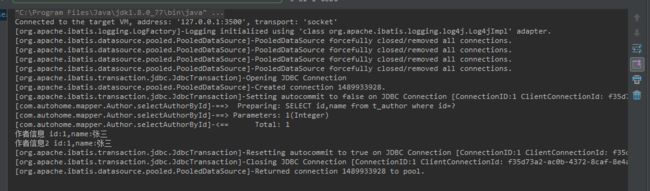
从DEBUG截图来看,当我们第一次调用方法时执行了SELECT id,name from t_author where id=? 此时缓存中还没有该数据,则执行数据库查询,当再次执行时直接从缓存中读取。
执行demo后我们来看下这个查询过程保存到缓存的源码,先看下DefaultSqlSession.java。我们调用的selectOne(),从代码中看它是直接调用selectList()然后判断返回值size大小。
@Override publicT selectOne(String statement) { return this. selectOne(statement, null); } @Override public T selectOne(String statement, Object parameter) { // Popular vote was to return null on 0 results and throw exception on too many. List list = this. selectList(statement, parameter); if (list.size() == 1) { return list.get(0); } else if (list.size() > 1) { throw new TooManyResultsException("Expected one result (or null) to be returned by selectOne(), but found: " + list.size()); } else { return null; } }
再跟踪到selectList方法,看到先构造MappedStatement对象,然后看到真正执行query()的是一个executor对象,在DefaultSqlSession.java中executor是成员变量,再翻到org.apache.ibatis.executor包中看到executor实际是一个接口。OK,那么我们debug时发现其引用是CachingExecutor。再打开CachingExecutor.java
@Override publicList selectList(String statement, Object parameter, RowBounds rowBounds) { try { MappedStatement ms = configuration.getMappedStatement(statement); return executor.query(ms, wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER); } catch (Exception e) { throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e); } finally { ErrorContext.instance().reset(); } }
从CachingExecutor.java的两个query()可以看到先去构造CacheKey 再调用抽象类BaseExecutor.query(),这个也是最关键的一步。
//先创建CacheKey publicList query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException { BoundSql boundSql = ms.getBoundSql(parameterObject); CacheKey key = createCacheKey(ms, parameterObject, rowBounds, boundSql); return query(ms, parameterObject, rowBounds, resultHandler, key, boundSql); } //再执行查询方法 public List query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException { Cache cache = ms.getCache(); if (cache != null) { flushCacheIfRequired(ms); if (ms.isUseCache() && resultHandler == null) { ensureNoOutParams(ms, parameterObject, boundSql); @SuppressWarnings("unchecked") List list = (List ) tcm.getObject(cache, key); if (list == null) { list = delegate. query(ms, parameterObject, rowBounds, resultHandler, key, boundSql); tcm.putObject(cache, key, list); // issue #578 and #116 } return list; } } return delegate. query(ms, parameterObject, rowBounds, resultHandler, key, boundSql); }
BaseExecutor.java
publicList query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException { ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId()); if (closed) { throw new ExecutorException("Executor was closed."); } if (queryStack == 0 && ms.isFlushCacheRequired()) { clearLocalCache(); } List list; try { queryStack++; list = resultHandler == null ? (List ) localCache.getObject(key) : null; if (list != null) { handleLocallyCachedOutputParameters(ms, key, parameter, boundSql); } else { list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql); } } finally { queryStack--; } if (queryStack == 0) { for (DeferredLoad deferredLoad : deferredLoads) { deferredLoad.load(); } // issue #601 deferredLoads.clear(); if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) { // issue #482 clearLocalCache(); } } return list; }
再看其中关键代码queryFromDatabase
privateList queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException { List list; localCache.putObject(key, EXECUTION_PLACEHOLDER); try { list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql); } finally { localCache.removeObject(key); } localCache.putObject(key, list); if (ms.getStatementType() == StatementType.CALLABLE) { localOutputParameterCache.putObject(key, parameter); } return list; }
OK,看了一长串,终于是有点眉目了,我们看到finally中先删除当前key缓存,然后再调用localCache.putObject把最新的结果集存入HashMap中。
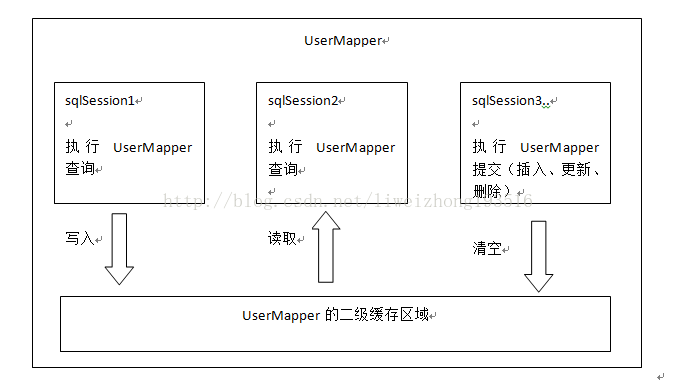
三、二级缓存
了解二级缓存之前先来看副图(图片来自传智播客视频,非本人编写),那么从图中我们可以看出,mybatis二级缓存是mapper级别,也就是说不同的sqlmapper共享不同的内存区域,不同的sqlsession共享同一个内存区域,用mapper的namespace区别内存区域。
开启mybatis二级缓存: 1、设置mybatis.xml,也就是说mybatis默认二级缓存是关闭的。
2、设置mapper。在mapper.xml内添加标签:
3、pojo实现接口Serializable。实现该接口后也就说明二级缓存不仅可以存入内存中,还可以存入磁盘。
OK,看一个二级缓存demo:
@Test
public void testCache2(){
SqlSession sqlSession=null;
SqlSession sqlSession2=null;
try{
sqlSession=sqlSessionFactory.openSession();
sqlSession2=sqlSessionFactory.openSession();
Author author = sqlSession.selectOne("com.autohome.mapper.Author.selectAuthorById",1);
System.out.println("作者信息 id:"+author.getId()+",name:"+author.getName());
sqlSession.close();
Author author2 = sqlSession2.selectOne("com.autohome.mapper.Author.selectAuthorById",1);
System.out.println("作者信息2 id:"+author2.getId()+",name:"+author2.getName());
sqlSession2.close();
}catch(Exception e){
e.printStackTrace();
}finally {
}
}
运行demo可以看出二级缓存不同的地方在于Cache Hit Ratio,发出sql查询时先看是否命中缓存,第一次则是0.0 ,再次查询时则直接读取缓存数据,命中率是0.5。当然数据结构还是HashMap。
如果数据实时性要求比较高,可以设置select 语句的

如果数据的查询实时性要求比较高,则设置select语句的useCache="false",则每次都直接执行sql。
以上这篇MyBatis 延迟加载、一级缓存、二级缓存(详解)就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持脚本之家。