《推荐系统开发实战》之推荐系统的灵魂伴侣-数据挖掘
转载请注明出处:http://blog.csdn.net/gamer_gyt
博主微博:http://weibo.com/234654758
Github:https://github.com/thinkgamer
公众号:搜索与推荐Wiki
个人网站:http://thinkgamer.github.io
个性化推荐是数据挖掘(Data Mining)中的一个目的明确的应用场景,所以,可以利用数据挖掘技术为推荐系统做一些基本工作,如了解数据、异常值处理、对用户群进行分类、对物品的价格进行聚类、构建用户的价格段偏好等,从而让推荐系统能够“千人千面”。本篇文章主要介绍一下常见的数据挖掘算法应用案例。
数据预处理
数据预处理(Data Preprocessing)是指:在使用数据进行建模或分析之前,对其进行一定的处理。真实环境中产生的数据往往都是不完整、不一致的“脏数据”,无法直接用来建模或进行数据分析。为了提高数据挖掘质量,需要先对数据进行一定的处理。
常见的数据预处理包括:标准化、离散化、抽样、降维、去噪等。
数据标准化
数据标准化(Normalization)是指:将数据按照一定的比例进行缩放,使其落入一个特定的小区间。其中,最典型的就是数据的归一化处理,即将数据统一映射到0~1之间。
数据标准化的好处有:加快模型的收敛速度,提高模型的精度。
常见的数据标准化方法包括:
- Min-Max标准化
Min-Max标准化是指对原始数据进行线性变换,将值映射到[0,1]之间。其计算公式为:

- Z-Score标准化
Z-Score(也叫Standard Score,标准分数)标准化是指:基于原始数据的均值(mean)和标准差(standard deviation)来进行数据的标准化。Z-Score标准化的计算公式为:

- 小数定标(Decimal scaling)标准化
小数定标标准化是指:通过移动小数点的位置来进行数据的标准化。小数点移动的位数取决于原始数据中的最大绝对值。小数定标标准化的计算公式为:

例如,一组数据为[-309, -10, -43,87,344,970],其中绝对值最大的是970。为使用小数定标标准化,用1000(即j=3)除以每个值。这样,-309被标准化为-0.309,970被标准化为0.97。
- 均值归一化法
均值归一化是指:通过原始数据中的均值、最大值和最小值来进行数据的标准化。均值归一化法的计算公式为:
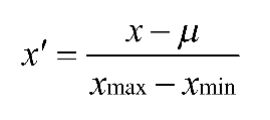
- 向量归一化
向量归一化是指:通过用原始数据中的每个值除以所有数据之和来进行数据的标准化。向量归一化的计算公式为:

- 指数转换
指数转换是指:通过对原始数据的值进行相应的指数函数变换来进行数据的标准化。常见的函数方法有lg函数、Softmax函数和Sigmoid函数。
由于篇幅原因,数据标准化的具体实现不贴代码了,可在《推荐系统开发实战》一书中找到找到!
数据离散化
数据离散化(也叫数据分组)是指将连续的数据进行分组,使其变为一段段离散化的区间。
根据离散化过程中是否考虑类别属性,可以将离散化算法分为有监督算法和无监督算法两类。由于有监督算法(如基于熵进行数据的离散化)充分利用了类别属性的信息,所以在分类中能获得较高的正确率。
常见的数据离散化方法有以下几种:
- 等宽分组
- 等频分组
- 单变量分组
- 基于信息熵分组
由于篇幅原因,基于信息熵的数据离散化实例这里贴代码了,可在《推荐系统开发实战》一书中找到!
数据抽样
数据抽样也叫数据采样。数据抽样是选择数据子集对象的一种常用方法。
- 在统计学中,抽样的目的是实现数据的调查和分析。
- 在数据挖掘中,抽样的目的是压缩数据量,减小数据挖掘算法的资源开销。
在数据挖掘中,抽样主要是从海量数据中产生训练集(Train Set)、测试集(Test Set)和验证集(Validation Set)。训练集、测试集和验证集三者的区别如下:
- 训练集用来进行模型训练。
- 测试集用来衡量模型的一些统计指标,如准确率、召回率等。在训练模型的过程中不允许使用测试集,否则会导致模型过拟合。
验证集用来验证模型、辅助构建模型。在使用机器学习算法时,验证集是可选的。
“过拟合”表示:模型学习特征过于彻底时,噪声数据也会进入模型,导致后期测试时不能很好地识别数据,泛化能力太差。“欠拟合”表示:没有很好地捕捉到数据特征,不能很好地拟合数据。
常见的数据抽样方法包括:
- 随机抽样
- 分层抽样
- 系统抽样
- 渐进抽样
数据降维
在构建机器学习模型时,有时特征是极其复杂的,当特征的维度达到几千维时,模型训练将会耗费大量的时间。另外,如果特征较多,还会出现多重共线性、稀疏性的问题。
因此,需要简化属性、去噪、去冗余,以求取更典型的属性,但同时又希望不损失数据本身的意义,这时就需要对特征进行降维。
数据降维分为线性降维和非线性降维。
- 线性降维:分为主成分分析(PCA)、线性判断分析(LDA)。
- 非线性降维:分为基于核函数的KPCA、KICA、KDA和基于特征值的ISOMAP、LLE、LE、LPP、LTSA、MVU等。
数据清理
“脏数据”对算法模型的直接影响是不能被使用,间接影响是降低模型的精度。这种情况下就需要对数据进行清理,包括(但不局限于):不合格数据修正、缺失值填充、噪声值处理、离群点处理。
- 不合格数据修正
- 缺失值填充
- 噪声值处理
- 离群点处理
相似度计算
相似度计算在数据挖掘和推荐系统中有着广泛的应用场景。例如:
- 在协同过滤算法中,利用相似度计算用户之间或物品之间的相似度。
- 在利用k-means进行聚类时,利用相似度计算公式计算个体到簇类中心的距离,进而判断个体所属的类别。
- 利用KNN进行分类时,利用相似度计算个体与已知类别之间的相似性,从而判断个体所属的类别等。
下面将依次介绍常见的相似度计算方法。 - 欧式距离
- 曼哈顿距离
- 切比雪夫距离
- 马氏距离
- 夹交余弦距离
- 杰卡德相似系数与杰卡德距离
- 相关系数与相关距离
数据分类
分类算法是数据挖掘中常用的基本算法之一,属于有监督学习算法(Supervised Learning)。
在实际应用场景中,往往利用分类算法对基础数据进行处理,或者做一些基础模型供推荐系统使用。
KNN算法
KNN算法的原理和具体的代码实现,这里不过多介绍,可参考《推荐系统开发实战》
KNN是一个分类算法,但可以使用KNN的原始算法思路进行推荐,即,为每个内容或物品寻找K个与其最相似的内容或物品,然后推荐给用户。
例如,在一个简单的电商网站中,用户浏览了一本图书,则推荐系统会依据图书的一些性质特征为用户推荐前 K个与该图书最相似的图书。
对性别进行预测在电商网站中也常用到。某些用户在填写注册信息时并没有注明性别,或者填写的数据不正确。如果在性别未知的情况下进行商品推荐,则容易将男性商品推荐给女性,或者将女性商品推荐给男性。这种情况下就需要对用户性别进行判定。这时候KNN算法就可以被派上用场了。
决策树
在点击率预估场景中我们经常使用的GBDT/XGBoost,其底层也是一棵棵决策树。了解决策树的算法和原因对我们后续学习GBDT也是很重要的。
决策树(Decision Tree)是根据一系列规则对数据进行分类的过程。分为回归决策树和分类决策树。
- 回归决策树是对连续变量构建决策树。
- 分类决策树是对离散变量构建决策树。
其中分类决策树的代表为ID3算法,C4.5和CART既可构建分类决策树也可以构建回归决策树。
朴素贝叶斯算法
在电商网站中,往往会存在一些异常用户,包括恶意刷单用户、爬虫爬取数据的用户等。这些异常用户产生的数据信息在推荐场景中往往是没有用的,即所说的“脏数据”。那么在准备推荐算法相关数据时,应过滤掉这些异常用户所产生的数据。
这个时候就可以使用贝叶斯算法了,贝叶斯算法是一类算法的总称,这些算法均以贝叶斯定理为基础。
贝叶斯理论是以18世纪的一位神学家托马斯•贝叶斯(Thomas Bayes)的名字命名的。通常,在事件B已经发生的前提下事件A发生的概率,与事件A已经发生的前提下事件B发生的概率是不一样的,然而这两者是有关系的。贝叶斯定理就是针对这种关系所做的陈述。
P(A|B)表示在事件B已经发生的前提下事件A发生的概率。其基本求解公式为:

贝叶斯定理便是基于条件概率的等式定理,其计算公式如下:

特征独立性假设是指,假设每个特征之间是没有联系的,朴素贝叶斯算法则是建立在这样的基础之上的。
朴素贝叶斯算法有三种常见模型:
- 多项式模型
- 高斯模型
- 伯努利模型。
数据聚类
聚类算法也是数据挖掘中常用的基本算法之一,属于无监督学习算法(Unsupervised Learning)。在实际应用场景中,会利用聚类算法对基础数据进行处理,或者做一些基础模型供推荐系统使用。
K-means算法
在电商网站中,商品的数目很多,对应的商品价格也很多。但对于用户来讲,并不是对所有价格的商品都感兴趣。例如,一个经常网购1000元左右手机的用户,通常没必要向他推荐价格超过5000元的手机。
所以,需要对商品的价格进行聚类,进而求出用户感兴趣的价格段,从而提高推荐系统的准确度和可信赖度。
这时候基于kMeans算法进行商品价格聚类算法就随之产生了。
kMeans(K均值聚类算法)的基本原理是:
(1)随机初始化K个初始簇类中心,对应K个初始簇类,按照“距离最近”原则,将每条数据都划分到最近的簇类;
(2)第一次迭代之后,更新各个簇类中心,然后进行第二次迭代,依旧按照“距离最近”原则进行数据归类;
(3)直到簇类中心不再改变,或者前后变化小于给定的误差值,或者达到迭代次数,才停止迭代。
具体的执行步骤如下:
(1)在数据集中初始K个簇类中心,对应K个初始簇类;
(2)计算给定数据集中每条数据到K个簇类中心的距离;
(3)按照“距离最近”原则,将每条数据都划分到最近的簇类中;
(4)更新每个簇类的中心;
(5)迭代执行步骤(2)~步骤(4),直至簇类中心不再改变,或者变化小于给定的误差区间,或者达到迭代次数;
(6)结束算法,输出最后的簇类中心和对应的簇类。
二分-Kmeans算法
二分-kMeans算法(二分-K均值聚类算法)是分层聚类(Hierarchical Clustering)的一种,是基于kMeans算法(K-均值聚类算法)实现的。
在二分-kMeans算法中,调用kMeans(k =2)把一个簇类分成两个,迭代此过程,直至分成k个。其实现的具体思路为:
(1)初始化簇类表,使之包含所有的数据;
(2)对每一个簇类应用k均值聚类算法(k = 2);
(3)计算划分后的误差,选择所有被划分的聚簇中总误差最小的并保存;
(4)迭代步骤(2)和步骤(3),簇类数目达到K后停止。
相对于kMeans算法,二分-kMeans的改进点有以下两点:
- 加速了kMeans的执行速度,减少了相似度的计算次数;
- 能够克服“kMeans收敛于局部最优”的缺点。
关联分析
关联分析的目的是,找到具有某种相关性的物品。这种分析在推荐系统中也有很大的作用,如经常出现在一个购物篮中的商品就可以相互推荐。关联算法最常见的就是Apriori。
该算法中涉及的一些概念解释为:
- 关联分析(Association Analysis):从大规模数据集中寻找商品的隐含关系。
- 项集(Item Set):包含0个或多个项的集合。
- 频繁项集:那些经常一起出现的物品集合。
- 支持度计数(Support Count):一个项集出现的次数(即,整个交易数据集中包含该项集的事物数)。
- 项集支持度:一个项集出现的次数与数据集所有事物数的百分比,计算公式如下:

- 项集置信度(confidence):数据集中同时包含A、B的百分比,计算公式如下:

Apriori算法使用一种称为逐层搜索的迭代方法,其中k项集用于探索(k+1)项集(如使用频繁1项集找到频繁2项集),其实现过程如下:
- (1)通过扫描数据库,累计每个项的计数,并收集满足最小支持度的项,找出频繁1项集的集合。该集合记作L1;
- (2)使用L1找出频繁2项集的集合L2,使用L2找出L3;
- (3)如此下去,直至不能再找到频繁k项集,每找出一个Lk需要一次完整的数据库扫描。
数据挖掘在推荐系统中的应用非常广泛,无论是数据预处理还是基础模型开发,他都发挥着举足轻重的作用,因此在理解推荐算法的同时,对数据挖掘也要进行一定程度的掌握。关于文中的更多详细内容请持续关注《推荐系统开发实战》

注:《推荐系统开发实战》是小编近期要上的一本图书,预计本月(7月末)可在京东,当当上线,感兴趣的朋友可以进行关注!
