- 一: 理解二次排序的功能, 使用自己理解的方式表达(包括自定义数据类型,分区,分组,排序)
- 二: 编写实现二次排序功能, 提供源码文件。
- 三:理解mapreduce join 的几种 方式,编码实现reduce join,提供源代码,说出思路。
一: 二次排序 使用自己理解的方式表达(包括自定义数据类型,分区,分组,排序)
1.1 二次排序的功能
1. 当客户端提交一个作业的时候,hadoop 会开启yarn 接受进行数据拷贝处理,之后交友有yarn 框架上的启动服务resourcemanager 接收,同时指派任务给nomanager ,nodemanger 会调用开 applicationmaster 处理任务,同时在 container 分配好要处理任务环境的抽象,封装了CPU、内存等多维资源以及环境变量、启动命令等任务运行相关的信息.之后输入数据,在输入数据进行数据inputspilt分割,人很掉用mapper基类将数据分割成,key-values键值对之后调用map()方法,调用该方法后会对keys-values 对分割,之后经过shuffle 过程map 的输出,就是reduce 端的输入 经过reduce段数据即可输出到hdfs 上面。 二次排序 就是首先按照第一字段排序,然后再对第一字段相同的行按照第二字段排序。
2. 在shuffle 过程中,会对数据进行分割(spilt),分区(partitioner),排序(sort),合并(combine),压缩(compress),分组(group) 之后输出到reduce端。1.2 shuffle 对job 格式定义:
1) partitioner
job.setPartitionerClass(FirstPartitioner.class);
2) sort
job.setSortComparatorClass(cls);
3) combine
job.setCombinerClass(cls);
4) compress
set by configuration
5) group
job.setGroupingComparatorClass(FirstGroupingComparator.class);二: 编写实现二次排序功能, 提供源码文件。
2.1 二次排序格式要求
1. 利用mapreduce 默认会对key 进行排序的方法对job 进行第一次排序
2. 把key和需要排序的第二个字段进行组合
2.2 二次排序Java的代码
SecoundarySortMapReduce.java
package org.apache.hadoop.studyhadoop.sort;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/**
*
* @author zhangyy
*
*/
public class SecondarySortMapReduce extends Configured implements Tool{
// step 1: mapper class
/**
* public class Mapper
*/
public static class SecondarySortMapper extends //
Mapper{
private PairWritable mapOutputKey = new PairWritable() ;
private IntWritable mapOutputValue = new IntWritable() ;
@Override
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
// line value
String lineValue = value.toString();
// split
String[] strs = lineValue.split(",") ;
// invalidate
if(2 != strs.length){
return ;
}
// set map output key and value
mapOutputKey.set(strs[0], Integer.valueOf(strs[1]));
mapOutputValue.set(Integer.valueOf(strs[1]));
// output
context.write(mapOutputKey, mapOutputValue);
}
}
// step 2: reducer class
/**
* public class Reducer
*/
public static class SecondarySortReducer extends //
Reducer{
private Text outputKey = new Text() ;
@Override
public void reduce(PairWritable key, Iterable values,
Context context)
throws IOException, InterruptedException {
// set output key
outputKey.set(key.getFirst());
// iterator
for(IntWritable value : values){
// output
context.write(outputKey, value);
}
}
}
// step 3: driver
public int run(String[] args) throws Exception {
// 1: get configuration
Configuration configuration = super.getConf() ;
// 2: create job
Job job = Job.getInstance(//
configuration, //
this.getClass().getSimpleName()//
);
job.setJarByClass(this.getClass());
// 3: set job
// input -> map -> reduce -> output
// 3.1: input
Path inPath = new Path(args[0]) ;
FileInputFormat.addInputPath(job, inPath);
// 3.2: mapper
job.setMapperClass(SecondarySortMapper.class);
job.setMapOutputKeyClass(PairWritable.class);
job.setMapOutputValueClass(IntWritable.class);
// ===========================Shuffle======================================
// 1) partitioner
job.setPartitionerClass(FirstPartitioner.class);
// 2) sort
// job.setSortComparatorClass(cls);
// 3) combine
// job.setCombinerClass(cls);
// 4) compress
// set by configuration
// 5) group
job.setGroupingComparatorClass(FirstGroupingComparator.class);
// ===========================Shuffle======================================
// 3.3: reducer
job.setReducerClass(SecondarySortReducer.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(IntWritable.class);
// set reducer number
job.setNumReduceTasks(2);
// 3.4: output
Path outPath = new Path(args[1]);
FileOutputFormat.setOutputPath(job, outPath);
// 4: submit job
boolean isSuccess = job.waitForCompletion(true);
return isSuccess ? 0 : 1 ;
}
public static void main(String[] args) throws Exception {
args = new String[]{
"hdfs://namenode01.hadoop.com:8020/input/sort" ,//
"hdfs://namenode01.hadoop.com:8020/output"
};
// create configuration
Configuration configuration = new Configuration();
// run job
int status = ToolRunner.run(//
configuration, //
new SecondarySortMapReduce(), //
args
) ;
// exit program
System.exit(status);
}
}
PairWritable.java
package org.apache.hadoop.studyhadoop.sort;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable;
public class PairWritable implements WritableComparable {
private String first;
private int second;
public PairWritable() {
}
public PairWritable(String first, int second) {
this.set(first, second);
}
public void set(String first, int second) {
this.first = first;
this.setSecond(second);
}
public String getFirst() {
return first;
}
public void setFirst(String first) {
this.first = first;
}
public int getSecond() {
return second - Integer.MAX_VALUE;
}
public void setSecond(int second) {
this.second = second + Integer.MAX_VALUE;
}
public void write(DataOutput out) throws IOException {
out.writeUTF(first);
out.writeInt(second);
}
public void readFields(DataInput in) throws IOException {
this.first = in.readUTF();
this.second = in.readInt();
}
public int compareTo(PairWritable o) {
// compare first
int comp =this.first.compareTo(o.getFirst()) ;
// eqauls
if(0 != comp){
return comp ;
}
// compare
return Integer.valueOf(this.getSecond()).compareTo(Integer.valueOf(o.getSecond())) ;
}
} FirstPartitioner.java
package org.apache.hadoop.studyhadoop.sort;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Partitioner;
public class FirstPartitioner extends Partitioner {
@Override
public int getPartition(PairWritable key, IntWritable value,
int numPartitions) {
return (key.getFirst().hashCode() & Integer.MAX_VALUE) % numPartitions;
}
}
FirstGroupingComparator.java
package org.apache.hadoop.studyhadoop.sort;
import org.apache.hadoop.io.RawComparator;
import org.apache.hadoop.io.WritableComparator;
public class FirstGroupingComparator implements RawComparator {
// object compare
public int compare(PairWritable o1, PairWritable o2) {
return o1.getFirst().compareTo(o2.getFirst());
}
// bytes compare
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
return WritableComparator.compareBytes(b1, 0, l1 - 4, b2, 0, l2 - 4);
}
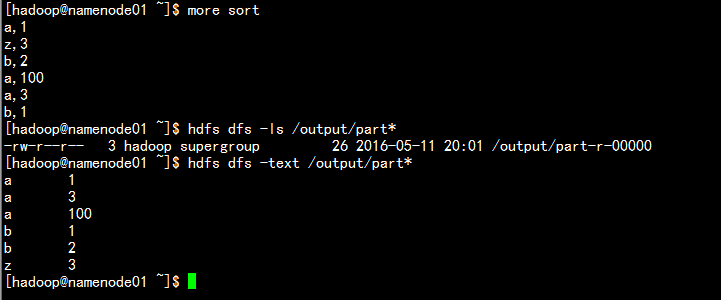
} 2.3 输出测试
上传数据处理:
hdfs dfs -put sort /input
运行输出:

三:理解mapreduce join 的几种 方式,编码实现reduce join,提供源代码,说出思路。
3.1 mapreduce join 有三种:
3.1.1 map 的端的join
map阶段不能获取所有需要的join字段,即:同一个key对应的字段可能位于不同map中。Reduce side join是非常低效的,因为shuffle阶段要进行大量的数据传输。
Map side join是针对以下场景进行的优化:两个待连接表中,有一个表非常大,而另一个表非常小,以至于小表可以直接存放到内存中。这样,我们可以将小表复制多份,让每个map task内存中存在一份(比如存放到hash table中),然后只扫描大表:对于大表中的每一条记录key/value,在hash table中查找是否有相同的key的记录,如果有,则连接后输出即可。
为了支持文件的复制,Hadoop提供了一个类DistributedCache 去实现。
3.1.2 reduce 的端的join
在map阶段,map函数同时读取两个文件File1和File2,为了区分两种来源的key/value数据对,对每条数据打一个标签(tag),比如:tag=0表示来自文件File1,tag=2表示来自文件File2。即:map阶段的主要任务是对不同文件中的数据打标签。
在reduce阶段,reduce函数获取key相同的来自File1和File2文件的value list, 然后对于同一个key,对File1和File2中的数据进行join(笛卡尔乘积)。即:reduce阶段进行实际的连接操作
3.1.3 SemiJoin
SemiJoin,也叫半连接,是从分布式数据库中借鉴过来的方法。它的产生动机是:对于reduce side join,跨机器的数据传输量非常大,这成了join操作的一个瓶颈,如果能够在map端过滤掉不会参加join操作的数据,则可以大大节省网络IO。
实现方法很简单:选取一个小表,假设是File1,将其参与join的key抽取出来,保存到文件File3中,File3文件一般很小,可以放到内存中。在map阶段,使用DistributedCache将File3复制到各个TaskTracker上,然后将File2中不在File3中的key对应的记录过滤掉,剩下的reduce阶段的工作与reduce side join相同3.2 编程代码:
DataJoinMapReduce.java
DataJoinMapReduce.java
package org.apache.hadoop.studyhadoop.join;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Mapper.Context;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/**
*
* @author zhangyy
*
*/
public class DataJoinMapReduce extends Configured implements Tool {
// step 1 : mapper
/**
* public class Mapper
*/
public static class WordCountMapper extends //
Mapper {
private LongWritable mapOutputKey = new LongWritable();
private DataJoinWritable mapOutputValue = new DataJoinWritable();
@Override
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
// split
String[] strs = value.toString().split(",");
// invalidate
if ((3 != strs.length) && (4 != strs.length)) {
return;
}
// set mapoutput key
Long cid = Long.valueOf(strs[0]);
mapOutputKey.set(cid);
// set name
String name = strs[1];
// customer
if (3 == strs.length) {
String phone = strs[2];
mapOutputValue.set("customer", name + "," + phone);
}
// order
if (4 == strs.length) {
String price = strs[2];
String date = strs[3];
mapOutputValue.set("order", name + "," + price + "," + date);
}
context.write(mapOutputKey, mapOutputValue);
}
}
// step 2 : reducer
public static class WordCountReducer extends //
Reducer {
private Text outputValue = new Text();
@Override
public void reduce(LongWritable key, Iterable values,
Context context) throws IOException, InterruptedException {
String customerInfo = new String();
List orderList = new ArrayList();
for (DataJoinWritable value : values) {
if ("customer".equals(value.getTag())) {
customerInfo = value.getData();
} else if ("order".equals(value.getTag())) {
orderList.add(value.getData());
}
}
for (String order : orderList) {
outputValue.set(key.toString() + "," + customerInfo + ","
+ order);
context.write(NullWritable.get(), outputValue);
}
}
}
// step 3 : job
public int run(String[] args) throws Exception {
// 1 : get configuration
Configuration configuration = super.getConf();
// 2 : create job
Job job = Job.getInstance(//
configuration,//
this.getClass().getSimpleName());
job.setJarByClass(DataJoinMapReduce.class);
// job.setNumReduceTasks(tasks);
// 3 : set job
// input --> map --> reduce --> output
// 3.1 : input
Path inPath = new Path(args[0]);
FileInputFormat.addInputPath(job, inPath);
// 3.2 : mapper
job.setMapperClass(WordCountMapper.class);
// TODO
job.setMapOutputKeyClass(LongWritable.class);
job.setMapOutputValueClass(DataJoinWritable.class);
// ====================shuffle==========================
// 1: partition
// job.setPartitionerClass(cls);
// 2: sort
// job.setSortComparatorClass(cls);
// 3: combine
// job.setCombinerClass(cls);
// 4: compress
// set by configuration
// 5 : group
// job.setGroupingComparatorClass(cls);
// ====================shuffle==========================
// 3.3 : reducer
job.setReducerClass(WordCountReducer.class);
// TODO
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(Text.class);
// 3.4 : output
Path outPath = new Path(args[1]);
FileOutputFormat.setOutputPath(job, outPath);
// 4 : submit job
boolean isSuccess = job.waitForCompletion(true);
return isSuccess ? 0 : 1;
}
public static void main(String[] args) throws Exception {
args = new String[] {
"hdfs://namenode01.hadoop.com:8020/join",
"hdfs://namenode01.hadoop.com:8020/output3/"
};
// get configuration
Configuration configuration = new Configuration();
// configuration.set(name, value);
// run job
int status = ToolRunner.run(//
configuration,//
new DataJoinMapReduce(),//
args);
// exit program
System.exit(status);
}
}
DataJoinWritable.java
package org.apache.hadoop.studyhadoop.join;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.Writable;
public class DataJoinWritable implements Writable {
private String tag ;
private String data ;
public DataJoinWritable() {
}
public DataJoinWritable(String tag, String data) {
this.set(tag, data);
}
public void set(String tag, String data) {
this.setTag(tag);
this.setData(data);
}
public String getTag() {
return tag;
}
public void setTag(String tag) {
this.tag = tag;
}
public String getData() {
return data;
}
public void setData(String data) {
this.data = data;
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + ((data == null) ? 0 : data.hashCode());
result = prime * result + ((tag == null) ? 0 : tag.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
DataJoinWritable other = (DataJoinWritable) obj;
if (data == null) {
if (other.data != null)
return false;
} else if (!data.equals(other.data))
return false;
if (tag == null) {
if (other.tag != null)
return false;
} else if (!tag.equals(other.tag))
return false;
return true;
}
public void write(DataOutput out) throws IOException {
out.writeUTF(this.getTag());
out.writeUTF(this.getData());
}
public void readFields(DataInput in) throws IOException {
this.setTag(in.readUTF());
this.setData(in.readUTF());
}
@Override
public String toString() {
return tag + "," + data ;
}
}
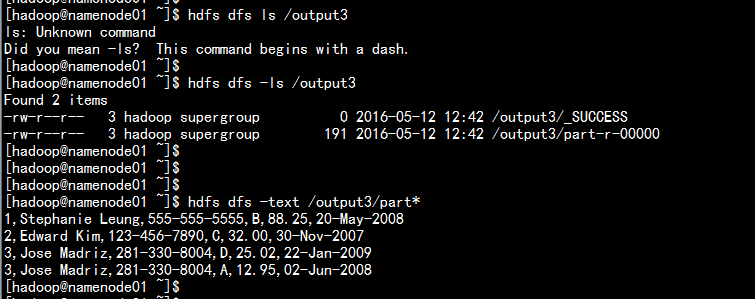
3.3 运行代码测试
上传文件:
hdfs dfs -put customers.txt /join
hdfs dfs -put orders.txt /join
运行结果: