- 使用load 方式加载数据到Hive 表中,注意分区表加载数据的特殊性
- 如何保存HiveQL 查询结果:保存到表中,保存到本地文件(注意指定列分隔符)
- 常见查询练习,如group by、having、join、sort by、order by 等。
一:hive 表的操作
1.1.1 hive的库的创建与数据库的查看:
hive(default)> create database yangyang;
hive(default)> use yangyang;
hive(yangyang)>desc database yangyang;
1.1.2 hive 表的创建查看与数据导入
创建emp 表:
hive(yangyang)> create table emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int
)
row format delimited fields terminated by '\t';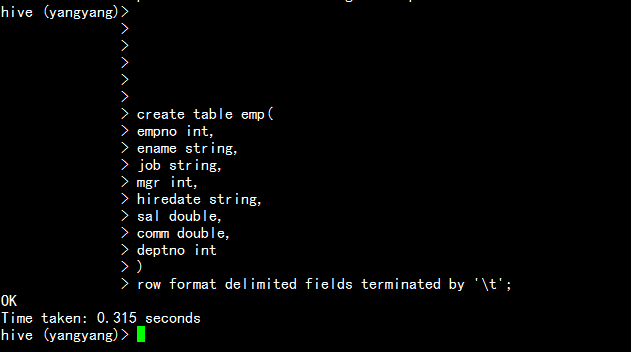
1.1.3 hive 创建表的三种方式:
1. 直接在数据库中创建:
hive(yangyang)>create table dept(
deptno int,
dname string,
loc string
)
row format delimited fields terminated by '\t';
2.使用已经存在的数据库进行数据抽取从新生成一张表:
create table emp2 as select * from emp;
1.此方法抽取的表数据与表结构都会存在
2.创建表的时候会执行mapreduce 的后端程序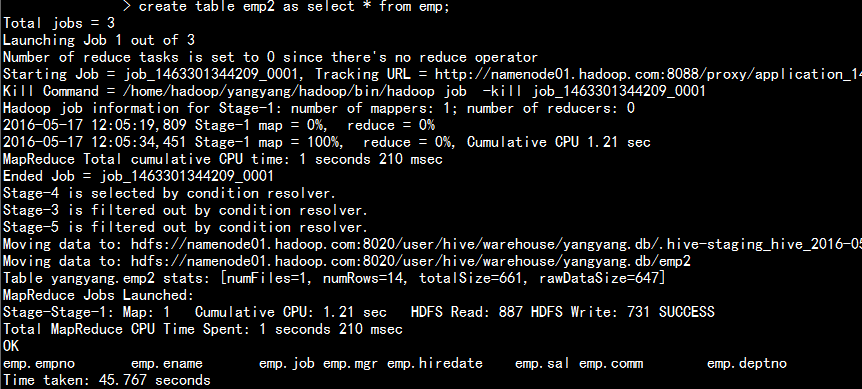
3.创建一张空表带数据结构
create table emp3 like emp;
select * from emp3;

1.1.4 hive 数据的导入处理:
1. 正常空表导入:
load data local inpath "/home/hadoop/emp.txt" into table emp;
load data local inpath "/home/hadoop/dept.txt" into table dept; 
2. 从hdfs 中导入数据
指定 hdfs 目录进行数据导入:
load data inpath "/user/hive/warehouse/yangyang.db/emp/emp.txt" into table emp3;
3. 加载数据进行数据覆盖:
hdfs dfs -put emp.txt /user
load data inpath "/user/emp.txt" overwrite into table emp;
注释:hive 在导入数据的时候不是空表的时候默认是追加导入append
一般在导入重复数据的时会增加overwrite 进行数据覆盖。4.创建表的时候用select完成
create table emp5 as select * from emp;
5.创建数据用insert into 创建表
先创建一个空表:
create table emp4 like emp ;
然后插入数据:
insert into table emp4 select * from emp; 
1.1.5hive库的导出:
1.导出到本地系统:
insert overwrite local directory '/home/hadoop/exp'
row format delimited fields terminated by '\t' select * from emp ;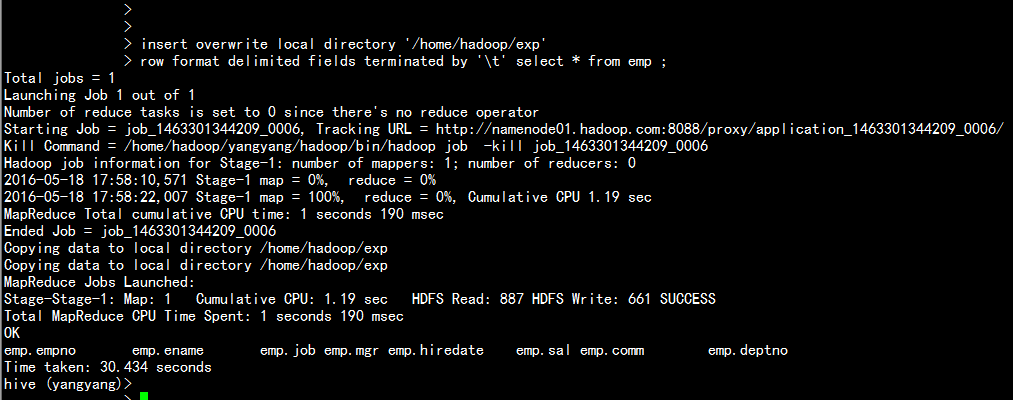
2. 导出到hdfs文件系统上面:
insert overwrite directory '/emp.txt' select * from emp ;
3. 导出文本文件:
hive -e 'select * from yangyang.emp' >> 1.txt
4.采用sqoop 数据导入导出。
hive 表的查看方式:
select * from dept;
select * from emp;

desc formatted dept;
desc formatted emp;
查询前几个字段:
select emp.ename from emp limit 2;
去重复查询:
select distinct(deptno) from emp limit 2;
输出结果进行排序:
select * from emp order by empno;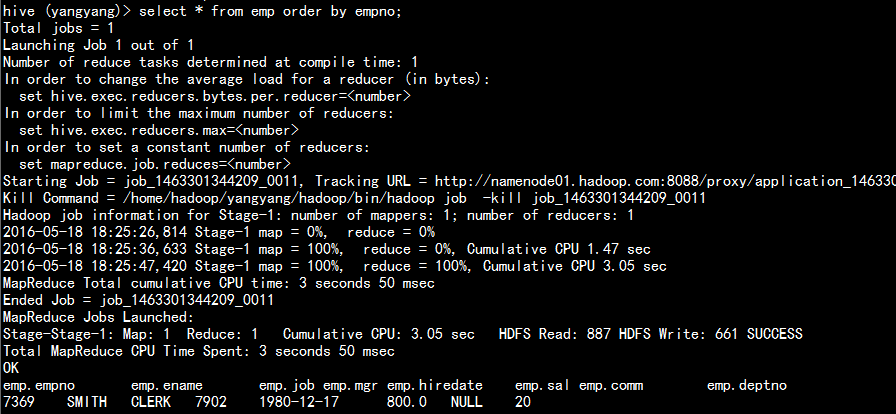
统计行数:
select count(empno) from emp; 
除去重复统计:
select count(distinct deptno) from emp;
分组统计:
select deptno,count(ename) from emp group by deptno ;
分组统计求最大值:
select deptno,max(sal) from emp group by deptno ;
分组之后过了统计:
select deptno,count(ename) from emp group by deptno having count(ename)>3;
设置mapreduce的个数。
hive >set mapreduce.job.reduces=3;
hive > insert overwrite local directory '/home/hadoop/exp1'
row format delimited fields terminated by '\t' select * from emp sort by empno;

1.1.6 关于hive 的排序功能:
order by
--全局排序 asc desc
sort by
--局部排序,每个reduce进行排序,全局不排序
distribute by
--类似与分区partition,通常和sort by联合使用
--通常sort by放在distribute by之后
cluster by
--相当于distribute by和sort by的结合(分区和排序字段一样)insert overwrite local directory '/home/hadoop/exp2'
row format delimited fields terminated by '\t' select * from emp
distribute by deptno sort by empno;
hive 的join 查询
右连接
select dept.dname,emp.ename from dept right join emp on emp.deptno=dept.deptno ;
左连接
select dept.dname,emp.ename from emp left join dept on emp.deptno=dept.deptno ; 
查询是否要走mapreduce 程序:
hive.fetch.task.conversion
more
Some select queries can be converted to single FETCH task minimizing latency.
Currently the query should be single sourced not having any subquery and should not have
any aggregations or distincts (which incurs RS), lateral views and joins.
1. minimal : SELECT STAR, FILTER on partition columns, LIMIT only
2. more : SELECT, FILTER, LIMIT only (TABLESAMPLE, virtual columns)
select emp.empno,emp.ename from emp;
select count(empno) from emp;
explain 查看hive命令的更多的解析状态:
explain select count(empno) from emp;


hive 查询中的四个查询
order by 分组查询 (全局数据的排序/只有一个reduce 输出)
select * from emp order by empno desc;

sort by 对每个reduce 的内部进行排序 对全局结果来说 是没有排序的
设置hive中的mapreduce 的数目
set mapreduce.job.reduces=3
select * from emp sort by empno asc;

distribute by
分区partition
类似于MapReduce中分区partition,对数据进行分区,结合sort by进行使用
insert overwrite local directory '/root/emp.txt' select * from emp distribute by deptno sort by empno asc ;
注意事项:
distribute by 必须要在sort by 前面。
>> cluster by
当distribute by和sort by 字段相同时,可以使用cluster by ;
insert overwrite local directory '/root/emp.txt' select * from emp cluster by empno ;