- 一:hbase 数据检索流程
- 二:hbase 数据库java api 调用
- 三:hbase 各个服务的作用
- 四:hbase 与mapreduce集成
- 五:hbase 使用BulkLoad 加载数据
一:hbase 数据检索流程
1.1 hbase 数据检索流程图:
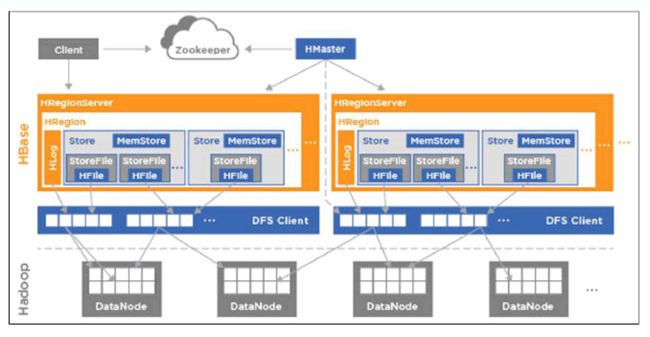
1.2 hbase 读的流程:
读流程:
1、client请求zookeeper集群(root/meta)(meta)
--有多少table,table有哪些region(startrow、stoprow)
2、client找到region对应的region server
3、region server响应客户端请求
1.3. hhbase 写的流程
1、client请求zookeeper集群,该数据应该写入哪个region
2、向region所在的region server 发起写请求
3、数据先写进HLOG(WAL)
4、然后写入memstore(flush)
5、当memstore达到阀值,写入storefile(compact)
6、当storefile达到阀值,合并成新的storefile
7、当region达到阀值,当前region会划分为两个新的region(split)
1.4 hbase 读写流程存储核心的三个机制
1. flush机制:当memstore满了以后会flush陈一个storefile
2. compact机制:当storefile达到阀值,合并storefile,合并过程中cell版本合并和数据删除
3. split机制:当region不断增大,达到阀值,region会分成两个新的region
二:hbase 数据库java api 调用
2.1 eclipse 环境配置
更改maven 的源:
上传repository.tar.gz
cd .m2
mv repository repository.bak2016612
rz repository.tar.gz
tar -zxvf repository.tar.gz
cd /home/hadoop/yangyang/hbase
cp -p hbase-site.xml log4j.properties /home/hadoop/workspace/studyhbase/src/main/rescourse
更改eclipse 的pom.xml
增加:
org.apache.hbase
hbase-server
0.98.6-hadoop2
org.apache.hbase
hbase-client
0.98.6-hadoop2
2.2 hbase java api 掉用:
package org.apache.hadoop.hbase;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.util.Bytes;
public class HbaseOperation {
/**
*
* @param args
* @throws IOException
*/
public static HTable getTable(String tableName) throws IOException {
// Get configuration
Configuration conf = HBaseConfiguration.create();
// Get Table
HTable table = new HTable(conf, tableName);
return table;
}
public static void getData() throws IOException {
HTable table = HbaseOperation.getTable("user");
// Get Data
Get get = new Get(Bytes.toBytes("1001"));
Result result = table.get(get);
Cell[] cells = result.rawCells();
for (Cell cell : cells) {
System.out.print(Bytes.toString(CellUtil.cloneFamily(cell)) + ":");
System.out.print(Bytes.toString(CellUtil.cloneQualifier(cell))
+ "==>");
System.out.println(Bytes.toString(CellUtil.cloneValue(cell)));
}
table.close();
}
/**
*
* @param args
* @throws IOException
*/
public static void putData() throws IOException {
HTable table = HbaseOperation.getTable("user");
Put put = new Put(Bytes.toBytes("1004"));
put.add(Bytes.toBytes("info"), Bytes.toBytes("name"),
Bytes.toBytes("zhaoliu"));
put.add(Bytes.toBytes("info"), Bytes.toBytes("age"),
Bytes.toBytes("50"));
put.add(Bytes.toBytes("info"), Bytes.toBytes("sex"),
Bytes.toBytes("male"));
table.put(put);
table.close();
}
public static void main(String[] args) throws IOException {
HTable table = HbaseOperation.getTable("user");
Scan scan = new Scan();
scan.setStartRow(Bytes.toBytes("1001")) ;
scan.setStopRow(Bytes.toBytes("1002")) ;
ResultScanner resultScanner = table.getScanner(scan);
for (Result res : resultScanner) {
Cell[] ress = res.rawCells();
for (Cell cell : ress) {
System.out.print(Bytes.toString(CellUtil.cloneRow(cell))
+ "\t");
System.out.print(Bytes.toString(CellUtil.cloneFamily(cell))
+ ":");
System.out.print(Bytes.toString(CellUtil.cloneQualifier(cell))
+ "==>");
System.out.println(Bytes.toString(CellUtil.cloneValue(cell)));
}
table.close();
}
}
}
三:hbase 各个服务的作用
3.1 Hmaster 作用:
1、为region server分配region
2、负责region server的负责均衡
3、发现失效的region server,需要重新分配其上的region
4、监听zk,基于zookeeper感应region server的上下线
5、监听zk,基于zookeeper来保证HA
6、不参与客户端数据读写访问
7、负载低(通常情况下可以把它和其他服务器(NN/SNN)整合在一起)
8、无单点故障(SPOF)
3.2 Hregionserver 作用:
1、维护master分配给它的region
2、响应客户端的IO访问请求(读写)
3、处理region的flush、compact、split
4、维护region的cache
3.4 zookeeper 作用:
1、保证集群里面只有一个master(HA)
2、保存了root region的位置(meta),访问入口地址
3、实时监控region server的状态,及时通知region server上下线消息给master
4、存储了hbase的schema,包括哪些table,每个表有哪些列簇
四:hbase 与mapreduce集成
4.1 hbase 获取jar命令
bin/hbase mapredcp
4.2 配置环境变量
vim .bash_profile
export HADOOP_HOME=/home/hadoop/yangyang/hadoop
export HBASE_HOME=/home/hadoop/yangyang/hbase
export HADOOP_CLASSPATH=`$HBASE_HOME/bin/hbase mapredcp`
PATH=$PATH:$HOME/bin:$JAVA_HOME/bin:${HADOOP_HOME}/bin:${MAVEN_HOME}/bin:${HBASE_HOME}:${HADOOP_CLASSPATH}
soure .bash_profile

4.3 统计一个hbase表:
cd /home/hadoop/yangyang/hadoop
bin/yarn jar /home/hadoop/yangyang/hbase/lib/hbase-server-0.98.6-cdh5.3.6.jar rowcounter user

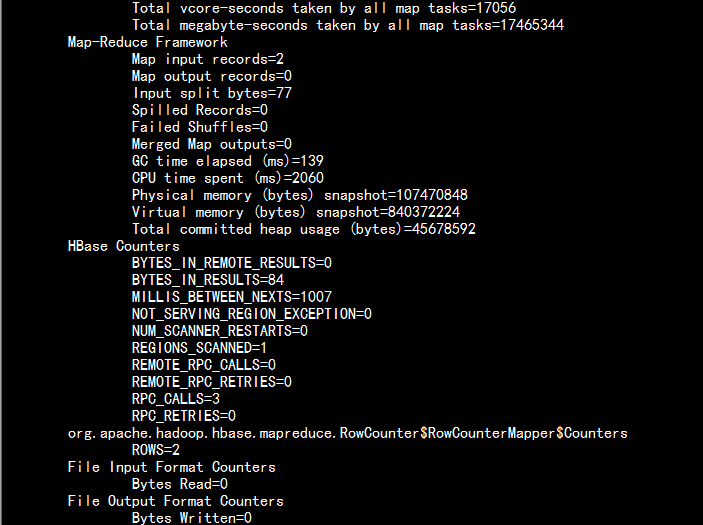
4.4 导入一个生成的hbase 表的in.tsv
vim in.tsv
---
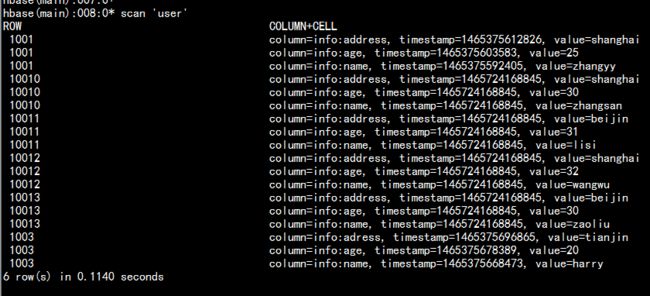
10010 zhangsan 30 shanghai
10011 lisi 31 beijin
10012 wangwu 32 shanghai
10013 zaoliu 30 beijin
hdfs dfs -put in.tsv /input
yarn jar /home/hadoop/yangyang/hbase/lib/hbase-server-0.98.6-cdh5.3.6.jar importtsv -Dimporttsv.columns=HBASE_ROW_KEY,info:name,info:age,info:address user /input/in.tsv

五: 使用BulkLoad加载数据
vim out.tsv
110 zhangsan 30 shanghai
111 lisi 31 beijin
112 wangwu 32 shanghai
113 zaoliu 30 beijin
hdfs dfs -put out.tsv /input
yarn jar /home/hadoop/yangyang/hbase/lib/hbase-server-0.98.6-cdh5.3.6.jar importtsv -Dimporttsv.bulk.output=/hfileoutput/ -Dimporttsv.columns=HBASE_ROW_KEY,info:name,info:age,info:tel user /input/out.tsv