后端服务性能压测实践
标签: 性能 压测 后端服务 压测实践
作者:王清培(Plen wang)
- 背景
- 环境检测
- 压力机及压力工具检测
- Linux openfiles limit 设置
- 排查周边依赖
- 空接口压测检测
- 聚合报告中 throughput 计算
- 压测及性能排查方法
- 关注各纬度 log
- Linux 常规命令
- 性能排查两种方式(从上往下、从下往上)
- 总结
背景
最近大半年内有过两次负责性能压测的一些工作。一件事情做了一次可能还无法总结出一些东西,两次过后还是能发现一些共性问题,所以总结下性能压测的一般性实践。但是问题肯定不止这些,还有更多深层次的问题等着发现,等我们遇到了在逐个解决再来总结分享。
做性能压测的原因就不多说了,一般两个时间点是必须要做的,大促前、新系统上线。压测都是为了系统在线上的处理能力和稳定性维持在一个标准范围内,做到心中有数。
从整个行业来看,抛开一些大厂不说,全自动化的性能压测环境还是比较少的,要想建设好一套全自动化的性能压测环境起码涉及到几个问题,CI\CD、独立、隔离的压测环境,自动化压测工具、日常压测性能报警、性能报表分析、排查/解决性能问题流程等等。这样才能将性能压测常规化,一旦不是常规化性能压测,就会有代码、中间件配置滞后于生产环境的问题。时间一长,就等于要重新开始搭建、排查压测环境。
如果性能压测的环境是全自动化的,那么就可以把性能压测工作常规化变成研发过程中的一个例行的事项,执行起来效率就会非常高,压测的时候也会比较轻松,好处也是比较明显的。
但是大多数的时候我们还是需要从零开始进行性能压测的工作。毕竟搭建这样一套环境给企业带来的成本也是巨大的。性能压测对环境敏感,必须划分独立的部署、隔离单元,才能在后续的常规压测流程中直观的阅读压测报告。
题外话,如果有了自动化的压测环境,也还是需要去了解下整个压测环境的基本架构,毕竟压测环境不是真实的生产环境,有些问题我们需要知道是正常的还是不正常的。
环境检测
当我们需要进行性能压测时首先要面对的问题就是环境问题,环境问题包含了常见的几个点:
1.机器问题(实体机还是虚拟机、CPU、内存、网络适配器进出口带宽、硬盘大小,硬盘是否 SSD、内核基本参数配置)
2.网络问题(是否有跨网段问题、网段是否隔离、如果有跨网段机器,是否能访问、跨网段是否有带宽限速)
3.中间件问题(程序里所有依赖的中间件是否有部署,中间件的配置是否初始化、中间件 cluster 结构什么样、这些中间件是否都进行过性能压测、压测的纬度是什么,是 benchmark 还是针对特定业务场景的压测)
这些环境问题第一次排查的时候会有点累,但是掌握了一些方法、工具、流程之后剩下的也就是例行的事情,只不过人工参与的工作多点。
上面的问题里,有些问题查看是比较简单的,这里就不介绍了,比如机器的基本配置等。有些配置只需要你推动下,走下相关流程回头验收下,比如网段隔离等,也还是比较简单的。
比较说不清楚的是中间件问题,看上去都是能用的,但是就是压不上去,这时候就需要你自己去进行简单的压测,比如 db 的单表插入、cache 的并发读取、mq 的落地写入等。这时候就涉及到一个问题,你需要对这些中间件都有一定深度的了解,要知道内在的运行机制,要不然出现异常情况排查起来确实很困难。
其实没有人能熟悉市面上所有的中间件,每一个中间件都很复杂,我们也不可能掌握一个中间件的所有点,但是常用的一些我们是需要掌握的,至少知道个大概的内部结构,可以顺藤摸瓜的排查问题。
但是事实上总有你不熟悉的,这个时候求助下大家的力量互相探讨再自己摸索找点资料,我们没遇到过也许别人遇到过,学技术其实就是这么个过程。
压力机及压力工具检测
既然做性能压测就需要先对压测机、压力工具先进行了解,压测工具我们主要有 locust、jmeter、ab,前两者主要是压测同事进行准出验收测试使用的。
后两者主要是用来提交压测前的自检使用,就是开发自己用来检查和排错使用的。这里需要强调下 ab 其实是做基准测试的,不同于 jmeter 的作用。
需要知道压力机是否和被压测机器服务器在一个网段,且网段之间没有任何带宽限制。压力机的压测工具配置是否有瓶颈,一般如果是 jmeter 的话需要检查 java 的一些基本配置。
但是一般如果压力机是固定不变的,一直在使用的,那么基本不会有什么问题,因为压力机压测同事一直维护者,反而是自己使用的压测工具的参数要做好配置和检测。
用 jmeter 压测的时候,如果压测时间过长,记得关掉 监听器->图形结果 面板,因为那个渲染如果时间太长基本会假死,误以为会是内存的问题,其实是渲染问题。
在开发做基准压测的时候有一个问题就是办公网络与压测服务器的网络之间的带宽问题,压力过大会导致办公网络出现问题。所以需要错开时间段。
大致梳理好后,我们需要通过一些工具来查看下基本配置是否正常。比如,ethtool 网络适配器信息、nload 流量情况等等,当然还有很多其他优秀的工具用来查看各项配置,这里就不罗列了。
使用 ethtool 查看网络适配器信息前需要先确定当前机器有几个网络适配器,最好的办法是使用 ifconfig 找到你正在使用的网络适配器。

排除 127.0.0.1 的适配器外,还有三个适配器信息,只有第一个 bond0 才是我们正在使用的,然后使用 ethtool 查看当前 bond0 的详细适配器信息。重点关注下 speed 域,它表示当前网络适配器的带宽。

虽然网络适配器可能配置的没有问题,但是整个网络是否没问题还需要咨询相关的运维同事进行排查下,中间还可能存在限速问题。
要确定网络带宽确实没有问题,我们还需要一个实时的监控网络流量工具,这里我们使用nload来监控下进出口流量问题。

这个工具还是很不错的,尤其是在压测的过程中可以观察流量的进出口情况,尤其是排查一些间隙抖动情况。
如果发现进口流量一直很正常,出口流量下来了有可能系统对外调用再放慢,有可能是下游调用 block,但是 request 线程池还未跑满,也有可能内部是纯 async ,request 线程根本不会跑满,也有可能是压测工具本身的压力问题等等。但是我们至少知道是自己的系统对外调用这个边界出了问题。
Linux openfiles limit 设置
工作环境中,一般情况下 linux 打开文件句柄数上限是不需要我们设置的,这些初始化的值运维同事一般是设置过的,而且是符合运维统一标准的。但是有时候关于最大连接数设置还要根据后端系统的使用场景来决定。
以防万一我们还是需要自己检查下是否符合当前系统的压测要求。
在 Linux 中一切都是文件,socket 也是文件,所以需要查看下当前机器对于文件句柄打开的限制,查看 ulimit -a 的 open files 域,也可以直接查看ulimit -n 。

如果觉得配置的参数需要调整,可以通过编辑 /etc/security/limits.conf 配置文件。
排查周边依赖
要想对一个服务进行压测,就需要对这个服务周边依赖进行一个排查,有可能你所依赖的服务不一定具备压测条件。并不是每个系统的压测都在一个时间段内,所以你在压测的时候别人的服务也许并不需要压测等等。
还有类似中间件的问题,比如,如果我们依赖中间件 cache ,那么是否有本地一级 cache ,如果有的话也许对压测环境的中间件 cache 依赖不是太大。如果我们依赖中间件 mq ,是不是在业务上可以断开对 mq 的依赖,因为我们毕竟不是对 mq 进行压测。还有我们所依赖服务也不关心我们的压测波动。
整理出来之后最好能画个草图,再重新 git branch -b 重新拉一个性能压测的 branch 出来根据草图进行调整代码依赖。然后压测的时候观察流量和数据的走向,是否符合我们梳理之后的路线。
空接口压测检测
为了快速验证压测服务一个简单的办法,就是通过压测一个空接口,查看下整个网络是否通畅,各个参数是否大体上正常。

一般在任何一个后端服务中,都有类似 __health_check 的 endpoint,方便起见可以直接找一个没有任何下游依赖的接口进行压测,这类接口主要是为了验证服务器的 online、offline__ 状态。
如果当前服务没有类似 __health_check__ 新建一个空接口也可以,而且实践证明,一个服务在生产环境非常需要这么一个接口,必要情况下可以帮助来排查调用链路问题。
《发布!软件的设计与部署》Jolt 大奖图书 第17章 透明性 介绍了架构的透明性设计作用。
聚合报告中 throughput 计算
我们在用 jmeter 进行压测的时候关于 聚合报告 中的 throughput 理解需要统一下。
正常情况下在使用 jmeter 压测的时候会仔细观察 throughput 这一列的变化情况,但是没有搞清楚 thourghput 的计算原理的时候就会误以为是 tps/qps 下来了,其实有时候是整个远程服务器根本就没有 response 了。
throughput=samples/压测时间
throughput(吞吐量) 是单位时间内的请求处理数,一般是按 second 计算,如果是压测 write 类型的接口,那么就是 tps 指标。如果压测 read 类型的接口,那么就是 qps 指标。这两种类型的指标是完全不一样的,我们不能搞混淆了。
200(throughput) tps=1000(write)/5(s)
1000(throughput) qps=2000(read)/2(s)
当我们发现 throughput 逐渐下来的时候要考虑一个时间的纬度。
也就是说我们的服务有可能已经不响应了,但是随着压测时间的积累,整个吞吐量的计算自然就在缓慢下滑,像这种刺尖问题是发现不了的。
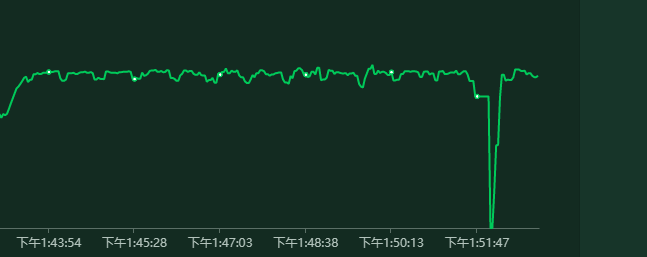
这一点用ui版本的 jmeter 尤其明显,因为它的表现方式就是在欢欢放慢。用 Linux 版本的 jmeter 还好点,因为它的输出打印是隔断时间才打印。
关于这个点没有搞清楚非常影响我们对性能压测的结果判断。所以我们在压测的时候一定要有监控报表,才能知道在整个压测过程中服务器的各项指标是否出现过异常情况。
大多数的时候我们还会使用 apache ab 做下基本的压测,主要是用来与 jmeter 对比下,两个工具压测的结果是否相差不大,主要用来纠偏一些性能虚高问题。
apache ab 与 jmeter 各有侧重,ab 可以按固定请求数来压,jmeter 可以按时间来压,最后计算的时候需要注意两者区别。ab 好像是没有请求错误提示和中断的,jmeter 是有错误提示,还有各个纬度断言设置。
我们在使用压测工具的时候,大致了解下工具的一些原理有助于准确的使用这款工具。
压测及性能排查方法
在文章的前面部分讲到了 排查周边依赖 的环境检查步骤。其实要想顺利的进行压测,这一步是必须要有的。经过这一步分析我们会有一个基本的 系统依赖 roadmap 。
基于这份 系统依赖 roadmap 我们将进行性能压测和问题定位及性能优化。
合理的系统架构应该是上层依赖下层,在没有确定下游系统性能的情况下,是没办法确定上游系统性能的瓶颈在哪里。
所以压测的顺序应该尽可能的从下往上依次进行,这样可以避免无意义的排查由于下游吞吐量不够带来的性能问题。越是下游系统性能要求越高,因为上游系统的性能瓶颈直接依赖下游系统。
比如,商品系统的 v1/product/{productid} 前台接口,吞吐量为 qps 8000,那么所有依赖这个接口的上游服务在这个代码路径上最高吞吐量瓶颈就是 8000 ,代码路径不管是 tps 还是 qps 都是一样的瓶颈。
上层服务可以使用 async方式来提高 request 并发量,但是无法提高代码路径在 v1/product/{productid} 业务上的吞吐量。
我们不能将并发和吞吐量搞混淆了,系统能扛住多少并发不代表吞吐量就很高。可以有很多方式来提高并发量,threadpool 提高线程池大小 、socket 类c10k 、nio事件驱动,诸如此类方法。
关注各纬度 log
当在压测的过程中定位性能问题的性价比较高的方法就是请求处理的log,请求处理时长log,对外接口调用时长log,这一般能定位大部分比较明显的问题。当我们用到了一些中间件的时候都会输出相应的执行log。
如下所示,在我们所使用的开发框架中支持了很多纬度的执行log,这在排查问题的时候就会非常方便。

slow.log 类型的慢日志还是非常有必要记录下来的,这不仅在压测的时候需要,在生产上我们也是非常需要。
如果我们使用了各种中间件,那就需要输出各种中间件的处理日志,mq.log、cache.log、search.log 诸如此类。
除了这些 log 之外,我们还需要重点关注运行时的 gc log。
我们主要使用 Java 平台,在压测的时候关注 gc log 是正常的事。哪怕不是 Java 程序,类似基于 vm 的语言都需要关注 gc log 。根据 jvm gcer 配置的不同,输出的日志也不太一样。
一般电商类的业务,以响应为优先时 gc 主要是使用 cms+prenew ,关注 full gc 频次,关注 cms 初始标记、并发标记、重新标记、并发清除 各个阶段执行时间, gc 执行的 real time ,pernew 执行时的内存回收大小等 。
java gc 比较复杂涉及到的东西也非常多,对 gc log 的解读也需要配合当前的内存各个代的大小及一系列 gc 的相关配置不同而不同。
《Java性能优化权威指南》 java之父gosling推荐,可以长期研究和学习。
Linux 常规命令
在压测的过程中为了能观察到系统的各项资源消耗情况我们需要借助各种工具来查看,主要包括网络、内存、处理器、流量。
###netstat
主要是用来查看各种网络相关信息。
比如,在压测的过程中,通过 netstat wc 看下 tcp 连接数是否和服务器 threadpool 设置的匹配。
netstat -tnlp | grep ip | wc -l
如果我们服务器的 threadpool 设置的是50,那么可以看到 tcp 连接数应该是50才对。然后再通过统计 jstack 服务器的 request runing 状态的线程数是不是>=50。
request 线程数的描述信息可能根据使用的 nio 框架的不同而不同。
还有使用频率最高的查看系统启动的端口状态、tcp 连接状态是 establelished 还是 listen 状态。
netstat -tnlp
再配合 ps 命令查看系统启动的状态。这一般用来确定程序是否真的启动了,如果启动了是不是 listen 的端口与配置中指定的端口不一致。
ps aux | grep ecm-placeorder
netstat 命令很强大有很多功能,如果我们需要查看命令的其他功能,可以使用man netstat 翻看帮助文档。
vmstat
主要用来监控虚拟处理器的运行队列统计信息。
vmstat 1

在压测的时候可以每隔 1s 或 2s 打印一次,可以查看处理器负载是不是过高。procs 列 r 子列就是当前处理器的处理队列,如果这个值超高当前 cpu core 数那么处理器负载将过高。可以和下面将介绍的 top 命令搭配着监控。
同时此命令可以在处理器过高的时候,查看内存是否够用是否出现大量的内存交换,换入换出的量多少 swap si 换入 swap so 换出。是否有非常高的上下文切换 system cs 每秒切换的次数,system us 用户态运行时间是否很少。是否有非常高的 io wait 等等。
关于这个命令网上已经有很多优秀的文章讲解,这里就不浪费时间重复了。同样可以使用 man vmstat 命令查看各种用法。
mpstat
主要用来监控多处理器统计信息
mpstat -P ALL 1
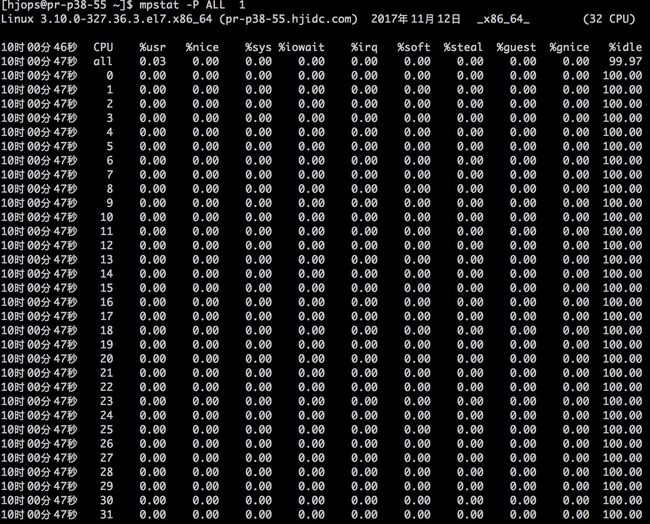
我这是一个 32 core 的压测服务器,通过 mpstat 可以监控每一个虚拟处理器的负载情况。也可以查看总的处理器负载情况。
mpstat 1

可以看到 %idle 处于闲置状态的 cpu 百分比,%user 用户态任务占用的 cpu 百分比,%sys 系统态内核占用 cpu 百分比,%soft 软中断占用 cpu 百分比,%nice 调整任务优先级占用的 cpu 百分比等等。
iostat
主要用于监控io统计信息
iostat 1

如果我们有大量的 io 操作的话通过 iostat 监控 io 的写入和读取的数据量,同时也能看到在 io 负载特别大的情况下 cpu 的平均负载情况。
top
监控整个系统的整体性能情况
top 命令是我们在日常情况下使用频率最高的,可以对当前系统环境了如指掌。处理器 load 率情况,memory 消耗情况,哪个 task 消耗 cpu 、memory 最高。
top

top 命令功能非常丰富,可以分别根据 %MEM、%CPU 排序。
load average 域表示 cpu load 率情况,后面三段分别表示最近1分钟、5分钟、15分钟的平均 load 率。这个值不能大于当前 cpu core 数,如果大于说明 cpu load 已经严重过高。就要去查看是不是线程数设置的过高,还要考虑这些任务是不是处理时间太长。设置的线程数与任务所处理的时长有直接关系。
Tasks 域表示任务数情况,total 总的任务数,running 运行中的任务数,sleeping 休眠中的任务数,stopped 暂停中的任务数,zombie 僵尸状态任务数。
Swap 域表示系统的交换区,压测的时候关注 used 是否会持续升高,如果持续升高说明物理内存已经用完开始进行内存页的交换。
free
查看当前系统的内存使用情况
free -m

total 总内存大小,used 已经分配的内存大小,free 当前可用的内存大小,shared 任务之间的共享内存大小,buffers 系统已经分配但是还未使用的,用来存放文件 matedata 元数据内存大小,cached 系统已经分配但是还未使用的,用来存放文件的内容数据的内存大小。
-/+buffer/cache
used 要减去 buffers/cached ,也就是说并没有用掉这么多内存,而是有一部分内存用在了 buffers/cached 里。
free 要加上 buffers/cached ,也就是说还有 buffers/cached 空余内存需要加上。
Swap 交换区统计,total 交换区总大小,used 已经使用的交换区大小,free 交换区可用大小。只需要关注 used 已经使用的交换区大小,如果这里有占用说明内存已经到瓶颈。
《深入理解LINUX内核》、《LINUX内核设计与实现》可以放在手边作为参考手册遇到问题翻翻。
性能排查两种方式(从上往下、从下往上)
当系统出现性能问题的时候可以从两个层面来排查问题,从上往下、从下网上,也可以综合运用这两种方法,压测的时候可以同时查看这两个纬度的信息。
一边打开 top 、free 观察 cpu 、memory 的系统级别的消耗情况,同时一边在通过 jstack 、jstat 之类的工具查看应用程序运行时的内部状态来综合定位。
总结
本篇文章主要还是从抛砖引玉的角度出发,整理下我们在做一般性能压测的时候出现的常规问题及排查方法和处理流程,并没有多么高深的技术点。
性能问题一旦出现也不会是个简单的问题,都需要花费很多精力来排查问题,运用各种工具、命令来逐步排查,而这些工具和命令所输出的信息都是系统底层原理,需要逐一去理解和实验的,并没有一个银弹能解决所有问题。