数据分析方法分为四大类:
1、单纯的数据加工方法
a.描述性统计分析(集中、离中趋势分析和数据分布)
b.相关性分析
2、基于数理统计的数据分析方法
方差分析、回归分析(特指一元线性回归)、因子分析
3、基于数据挖掘的数据分析方法
a.聚类分析
b.分类分析(决策树、人工神经网络、贝叶斯分类法、支持向量机随机森林、关联规则、回归分析)
4、基于大数据的数据分析方法
与数据挖掘使用的工具不同(使用Hadoop、Mathout、Spark、Storm)
数理统计与数据挖掘的联系:都来源于统计基础理论,例如概率论和随机事件。
数理统计与数据挖掘的区别:a.数理统计需要对分布和变量间的关系作假设,数据挖掘不对分布作任何假设;b.数理统计在预测中常表现为一组函数关系式,数据挖掘则重点在于结果,往往没有得出明确的函数关系式。
数据分析的目的是为业务发展答疑解惑及分析层次,涉及公司运营的方方面面,特别是客户与市场的数据分析。
分析的层级:常规报表、即席查询、多维分析(钻取or OLAP)、警报、统计分析、预报、预测型建模、优化
数据挖掘是一种发现知识的手段,通过合理的方法从数据中获取与数据挖掘项目相关的知识。
大数据(数据挖掘)是对传统小数据分析的扩展:数据量(海量)、数据精度(下降)、算法(特殊)、关注点(关注时间、效率和知识发现,关注相关分析而非因果分析)
CRISP-DM方法论:将项目生命周期分为业务理解、数据理解、数据准备、建模、模型评估、模型发布。
SEMMA方法论:定义业务问题、环境评估、数据准备、循环挖掘、上线发布、检视;其中的循环挖掘包括数据整理、样本探索、变量修改、建模、模型检验。
描述性统计分析:
1、直方图
易混淆点:常见的是频数分布直方图(长方形的高代表频数);统计意义上的是频率分布直方图(长方形面积=频数/组距),无纵向刻度。
注意点:有的区间分布本身就不均匀,在水平轴上要按照实际比例划分区间。
2、数据的计量尺度
包括定类尺度(性别/民族)、定序尺度(职称/质量等级)、定距尺度(摄氏度/纬度)、定比尺度(质量/长度)。
定距与定比的区别:定比的“0“表示”没有“。
3、数据的集中趋势
a. 平均值
受极端值的影响
b. 分位数
要先把数据按顺序排列,常见的有百分位数(Xp%)、四分位数、中位数。
c. 众数
一组数据中出现次数最多的值;有三种情况:无众数,有一个众数,有多个众数。
4、数据的离中趋势
a. 极差(全距)
b. 分位距
四分位距=第三个四分位数-第一个四分位数
排除了数列中两端各25%的数值的影响。
c. 平均差
各数值与算术平均年数的离差对的绝对值的算术平均数。
d. 方差和标准差
方差的平方根就是标准差(s)。
标准差体现了平均数的代表性,指出了数值离平均数有多远。
e. 离散系数
标准差之类的数据类型有缺点:受计量单位的影响,受变量平均水平高低的影响(例如数值的整体绝对值越高,得出的标准差也越大)。
要比较平均水平不同的两组数,就需要用离散系数。
常见的离散系数:标准差系数(Vs)=标准差与算术平均数的百分比,数值越小,波动越小
5、数据分布的测定
正态分布
a. 偏态系数
SK=0 分布对称
SK<0 负偏态,向左偏
SK>0 正偏态,向右偏
b. 数据峰度
K>0 尖顶峰度
K<0 平顶峰度
c. 偏度与峰度的作用
SK≈0、K≈3 可以认为是正态分布。
6、数据的展示-统计图
a. 条形图与扇形图
b. 折线图
c. 茎叶图
茎(数值的高位),叶(数值的低位)
整数时,可以把个位作为“叶”;小数时,可以把小数部分作为“叶”。
d. 箱线图

数理统计基础:
1、抽样估计基础
a. 随机事件
随机现象:重复性、明确性、随机性,需要大量的重复的随机实验。
样本空间(Ω):随机现象的一切可能的组合的集合。
随机事件:样本空间的一个子集,也就是在样本空间里满足一些前提的某些结果的集合。
b.随机事件的概率
是随机事件出现的可能性的度量。
事件A的概率是P(A),事件A与B同时发生的概率是P(AB)。
条件概率:在事件B已发生的条件下,事件A发生的概率P(A│B)=P(AB)/P(B)。
在条件概率中,随着条件的增加,事件A的条件概率也在增加。
相互独立事件:P(A)=P(A│B)即说明A关于B是独立的。
概念延伸:有回放抽样(独立),无回放抽样(非独立)。
c. 随机变量及其概率分布
随机变量(大写字母):表示随机现象结果的变量。
常见的做法是把刻画试验结果的数值直接定义成随机变量的取值,例如寿命、产量、次数等。
离散型随机变量、连续型随机变量
随机变量的概率分布:知道了随机变量所有值的可能性(分布),就找到了随机试验的规律性。
离散随机变量的分布:每一个取值的概率在0与1之间,所有取值的概率之和是1。
连续随机变量的分布:用概率密度函数来表示;可以从直方图做出概率密度曲线(纵轴会由频率变成概率)。
概率密度曲线与x轴所夹面积为1,求随机事件的概率变成求某个区间关于概率密度曲线的积分。
d. 随机变量的数学特征
随机变量的数学期望:变量值按概率的加权平均,也就是所有变量值乘以对应的概率再全部相加。
表示为E(X)
随机变量的数学期望表征的是概率分布的中心位置。
方差Var(X)大,随机变量的取值分布宽;方差小,取值分布窄。
方差的平方根是标准差STD。
对于相互独立的随机变量,方差可相加,标准差不能相加。
2、正态分布及三大分布
a. 正态分布的概率密度函数
X~N(μ,σ2)
μ:平均值;σ:标准差
b. 正态分布的特征
对称性、非负性、由μ和σ完全控制
μ控制位置,σ控制离散程度。
c. 标准正态分布
μ=0,且σ=1
所有的正态分布都可以通过平移和伸缩变换成标准正态分布。
查标准正态分布表的方法:
在表中查Φ(x),先在左边找到小数点第二位之前的数值,再从顶部找到小数点第二位,两者相交的数值即是。
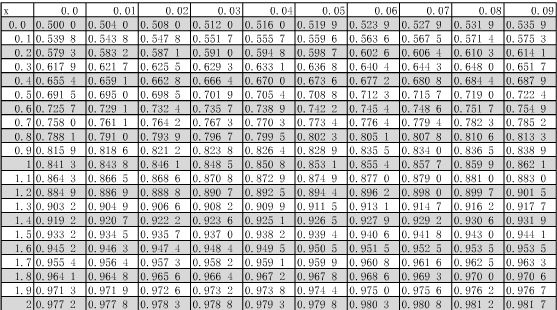
Φ(x)表示总体中小于x的概率即 P(X 当X≥0时,直接查Φ(x)即可得到P(X≤x) 当X<0时,由Φ(x)=1-Φ(-x)可知P(│X│≤x)=2Φ(x)-1 区间(x1,x2)的概率是Φ(x2)-Φ(x1) 如果X不是标准正态分布,需要先转化成标准正态分布后才能查表: X~N(μ,σ2) → (X-μ)/σ~N(0,1) 标准正态分布的“3σ原则”:68.3%,95.4%,99.7% χ2分布(卡方分布):用于分类变量的卡方检验 t分布:在信息不足的情况下,一般使用t分布 F分布:用于方差比例检验、方差分析、回归分析和方差齐性检验 在自然界与生产中,一些现象受到许多相互独立的随机因素的影响,如果每个因素所产生的影响都很微小时,总的影响可以看作是服从正态分布的。 随机变量之和:当n充分大时,独立随机变量(ξ)之和近似服从正态分布N(数学期望之和,方差之和);从均值为μ、方差为σ^2;(有限)的任意一个总体中抽取样本量为n的样本,当n充分大时,样本均值的抽样分布近似服从均值为μ、方差为(σ^2)/n 的正态分布。 独立随机变量的规范和:如果ξ都有有穷数学期望和方差,就可以把ξ之和的分布转化为标准正态分布 隶美弗-拉普拉斯积分定理 林德伯格定理 李亚普诺夫定理 当随机因素对总的影响均匀地小,同时又是独立的,并且总数在15个以上,可以认为其和的分布是正态的。 总体:研究对象的全体。 个体:组成总体的每一个元素被称为个体,它是被分析和测量的对象,特性包括同质性(有相同的观测变量)、大量性、差异性(值不同)。 总体指标:可以对应到数理统计里的平均数、方差、标准差等。 总体与随机变量:总体是一组个体观测数据的集合,即样本空间,测量就等于随机试验,总体的分布也就等同于随机变量的分布。 样本:因为无法测量所有个体,所以进行抽样,样本就是用来代表总体的子集,样本容量就是样本中的个体数目。 样本个数:就是总体中可以抽样的全部次数;总体容量M,样本容量n,样本个数就是M的n次方。 样本指标:就是针对样本内部的值做统计(方差、平均值之类),可以用来推断总体指标。 总体指标与样本指标的区别与联系:1. 样本指标是一个随机变量但通过抽样计算可知,总体指标是一个确定的值但是未知的。2. 必须通过样本指标来推断总体指标,所有可能样本指标的平均数等于总体相应指标,如果样本单位数增大,样本指标就会接近总体指标。 抽样估计,又叫抽样推断,也叫参数估计,包括了调查和估计。 先按随机原则抽样调查,再用数理统计进行研究。 若X1,X2,...,Xn是从总体X中获得的样本,那么X1,X2,...,Xn就是独立同分布的随机变量,样本的观测值x1,x2,...xn就是数据。 抽样方法:重复抽样,不重复抽样 大数定律:如果随机变量总体存在有限的平均数和方差,则对于充分大的抽样单位数n,可以易趋近与1的概率来期望抽样平均数与总体平均数的绝对差为任意小。也就是抽样数越多,抽样平均数就越接近总体平均数。 中心极限定理:只要总体变量存在有限的平均数和方差,那么不管总体变量的分布如何,随着抽样单位数的增加,抽样平均数就趋近与正态分布。 大数定律论证了抽样平均数趋近于总体平均数的趋势,中心极限定理说明了抽样平均数与总体平均数对的离差不超过一定范围的概率。 不含未知参数的样本函数称为统计量,统计量的分布称为抽样分布。 从某种意义上讲,样本统计量就是样本指标。 样本均值统计量,它的分布服从正态分布(总体的均值和方差)。 抽样一次,以此样本统计量的值作为总体指标。 用样本平均数来估计全体的平均数μ,就是点估计。 优良点估计要做到无偏性、有效性(抽样分布的方差要小)、一致性。 样本容量越大精度越高。 点估计以误差存在为前提,且误差大小及可靠度不可知。 凡进行抽样就要一定会产生误差。 实际误差就是样本统计量和总体指标之间的差距。 因为一次抽样的实际误差无法计算,所以抽样误差的大小通过抽样平均误差来反映。 抽样平均误差是抽样平均数的标准差,即先计算出各个样本的平均数,再计算所有平均数的标准差。 分析人员可以要求有一个允许误差范围Δ。 抽样平均数以总体平均数为中心,在+-Δ之间波动。 抽样估计精度是抽样估计的准确程度,这与抽样误差相对: 估计精度=1-误差率 误差率等于误差范围除以样本平均数。 因为抽样误差是一个随机变量,所以抽样平均数落在一个区间是有概率的。 抽样误差范围与估计置信度呈反比。 概率度(t)= 区间估计是根据样本指标的分布率,按照一定要求,先确定出θ1与θ2,使总体指标θ的概率P(θ1≤θ≤θ2)=1-α α被称为显著性水平;1-α称为置信系数(置信概率) 置信区间表达了区间估计的准确性,置信系数表达了可靠性。 准确性与可靠性不能兼得,只能提出其中一个条件,然后推导出另一个条件的变动情况。 以95%的置信系数为例,如果做一百次独立的抽样统计,会有一百个样本平均数,也会有一百个区间估计,而这一百个区间估计里有95个正确地包含全体平均数μ。我们只做一次抽样的话,得到的这一个区间估计会包含着μ的机会是95%. 共同步骤:计算样本指标来作为总体的估计值,再计算样本标准差来推算抽样平均误差 给定误差范围,求概率保证程度:抽样误差除以抽样平均误差得出t,再查《正态分布概率表》得出置信度 给定置信度,求极限误差的可能范围:根据置信度查出t,再根据t求出误差(即极限误差) 简单随机抽样 分层抽样:先分组,再按各组频数占总体频数的比重分配抽样数目 等距抽样:先排列数据,再等距抽样 整群抽样:例如按整箱、整村进行抽样 多阶段抽样 假设检验遵循的推断依据是小概率原理,这个小概率就是假设检验的显著性水平α α越小,所做出的拒绝原假设的判断力越强,但这与“反证法”不同。 设立原假设(虚无假设)H0和备择假设H1 。 H0总包含等号,H0与H1对立。 依据涉及的总体分布,构造一个适用于检验H0的统计量,例如使统计量服从标准正态分布。 确定小概率事件的临界值α,也就是统计量的分布中面积(概率)为α的区间,一般取α<0.05或α<0.01 。 用α推算出统计量的拒绝域。 用随机抽样得到的值来计算出统计量的抽样值,看是否在拒绝域内。 在分析软件中已经取代临界值检验 P值就是,出现统计量观测值以及更极端值的概率。 α>P,则拒绝原假设 α α=P,可增加样本容量 单因素方差分析是指将所获得的数据按某些项目(因子)分类后,再分析各组(两个组以上)数据之间有无差异的方法。即变异分解过程。 适用条件:因素水平间的因变量要服从正态分布、适用于分类水平为两个以上的分类变量、总体方差相等。 假设: H0:μ1=μ2=...=μr H1:μ1,μ2,...,μr不全相等 SST(总离差平方和):反映了全部试验数据之间的差异 SSM(组间离差平方和):反映了每组数据均值和总平均值的误差 SSE(组内离差平方和):反映了组内数据和组内平均的随机误差 SST=SSE+SSM 差分运算把非平稳 主键:PRIMARY KEY 非空:NOT NULL 唯一:UNIQUE 创建表:CREATE TABLE 修改表:ALTER TABLE 导入外部文本:LOAD DATA[LOCAL] INFILE 查看表结构:DESC 删除表:DROP TABLE 单表查询和过滤:SELECT 字段列表 FROM 表名 横向多表链接: 纵向多表连接: 更新字段中的内容:UPDATE 删除记录:DELETE FROM 表名 WHERE 创建视图:CREATE VIEW “和”:AND “或”:OR 在集合内:IN 在范围内:BETWEEN 相同:LIKEd. 基于正态分布的三大分布
3、中心极限定理
a. 中心极限定理的提法

b. 中心极限定理的内容
c. 中心极限定理的意义应用
抽样估计:
1、抽样估计的基本概念
a. 总体及总体指标
b. 样本及样本指标
c. 抽样估计的思想
d. 抽样轨迹的理论基础
e. 样本统计量及分布
2、抽样估计的方法--点估计
a. 点估计
b. 点估计精度和样本容量的关系
c. 点估计的优缺点
3、抽样估计的误差
a. 抽样估计的实际误差
b. 抽样估计的平均误差
c. 抽样估计的极限误差
4、抽样估计的方法--区间估计
a. 抽样估计的精度及置信度
b. 区间估计的方法
c. 区间估计的步骤
5、抽样的组织形式和抽样数目的确定
a. 抽样的组织形式
b. 必要抽样数目的确定
假设检验:
1、基本原理
2、分析方法
3、P值检验
方差分析
时间序列
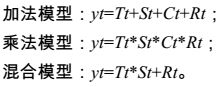
![]()
![]()

SQL


![]()