1、介绍
Bireme 是一个 Greenplum / HashData 数据仓库的增量同步工具。目前支持 MySQL、PostgreSQL 和 MongoDB 数据源
官方介绍文档:https://github.com/HashDataInc/bireme/blob/master/README_zh-cn.md
1、数据流
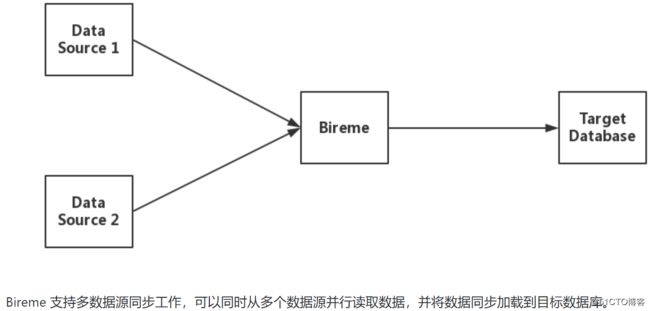
Bireme 采用 DELETE + COPY 的方式,将数据源的修改记录同步到 Greenplum / HashData ,相较于INSERT + UPDATE + DELETE的方式,COPY 方式速度更快,性能更优
2、数据源
2.1、Maxwell + Kafka 是 bireme 目前支持的一种数据源类型,架构如下图: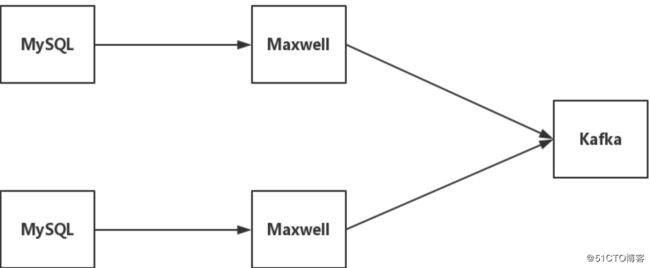
Maxwell 是一个 MySQL binlog 的读取工具,它可以实时读取 MySQL 的 binlog,并生成 JSON 格式的消息,作为生产者发送给 Kafka
2.2、Debezium + Kafka 是 bireme 支持的另外一种数据源类型,架构如下图: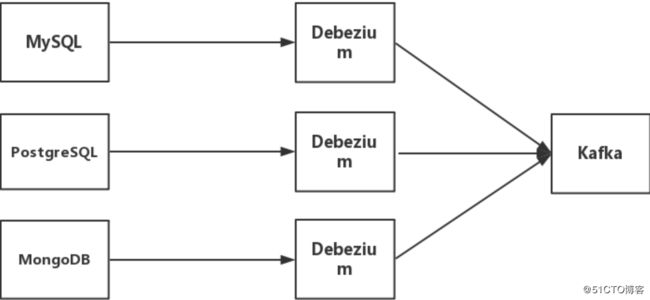
Debezium 是一个CDC工具,可以将数据库的增删改转换为事件流,并把这些修改发送给 Kafka
3、工作原理
Bireme 从数据源读取数据 (Record),将其转化为内部格式 (Row) 并缓存,当缓存数据达到一定量,将这些数据合并为一个任务 (Task),每个任务包含两个集合,delete 集合与insert 集合,最后把这些数据更新到目标数据库。
每个数据源可以有多个 pipeline,对于 maxwell,每个 Kafka partition 对应一个 pipeline;对于 debezium,每个 Kafka topic 对应一个 pipeline
4、本文搭建实例图形

2、配置相关数据源、目标数据源和java环境
1、mysql数据源
1、数据库,create database syncdb1;
2、用户权限,需要拥有select权限和binlog拉取权限,此处使用root权限
3、同步的表(切换到syncdb1数据库),create table tb1(a int, b char(10), primary key(a));2、pgsql目的数据库
1、用户,create user syncdb with password 'syncdb';
2、数据库,create database syncdb with owner 'syncdb';
3、同步的表(使用syncdb用户切换到syncdb数据库),create table tb1(a int, b char(10), primary key(a));3、java环境的安装
1、下载二进制安装包:jdk-8u101-linux-x64.tar.gz
2、解压二进制包并做软链接:tar xf jdk-8u101-linux-x64.tar.gz && ln -s /data/jdk1.8.0_101 /usr/java
3、配置路径和java环境变量:vim /etc/profile.d/java.sh
export JAVA_HOME=/usr/java
export JRE_HOME=$JAVA_HOME/jre
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
4、source生效:source /etc/profile.d/java.sh
5、安装jsvc,yum install jsvc
3、kafka的安装和启动配置
1、下载地址:https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/
2、kafka官方文档:http://kafka.apache.org/
3、解压缩:tar xf kafka_2.11-2.0.0.tgz && cd kafka_2.11-2.0.0
4、ZooKeeper
启动,bin/zookeeper-server-start.sh config/zookeeper.properties
关闭,bin/zookeeper-server-stop.sh config/zookeeper.properties5、Kafka server
启动,bin/kafka-server-start.sh config/server.properties
启动,bin/kafka-server-stop.sh config/server.properties6、Topic
创建,bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic world
查询,bin/kafka-topics.sh --list --zookeeper localhost:2181
删除,bin/kafka-topics.sh --delete --zookeeper localhost:2181 --topic world7、Producer(不是本实验必须的,作为学习使用)
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
>hello
>jiaming
>8、Consumer(不是本实验必须的,作为学习使用)
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
hello
jiaming
4、maxwell的安装和启动配置
1、下载地址:https://github.com/zendesk/maxwell/releases
2、maxwell官方文档:https://github.com/zendesk/maxwell
3、解压缩:tar xf maxwell-1.17.1.tar.gz && cd maxwell-1.17.1
4、修改配置文件,cp config.properties.example config.properties && vim config.properties
log_level=info
# kafka info
producer=kafka
kafka.bootstrap.servers=localhost:9092
kafka_topic=world
ddl_kafka_topic=world
# mysql login info
host=118.190.209.102
port=5700
user=root
password=1234565、启动maxwell,bin/maxwell --config config.properties
6、maxwell默认在源数据库生成库maxwell记录相关信息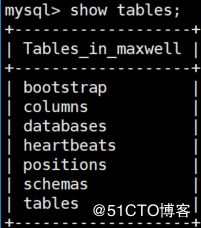
5、bireme的安装和启动配置
1、下载地址:https://github.com/HashDataInc/bireme/releases
2、bireme官方文档:https://github.com/HashDataInc/bireme/blob/master/README_zh-cn.md
3、解压缩:tar xf bireme-1.0.0.tar.gz && cd bireme-1.0.0
4、修改配置文件,vim etc/config.properties
# target database where the data will sync into.
target.url = jdbc:postgresql://118.190.209.102:5432/syncdb
target.user = syncdb
target.passwd = syncdb
# data source name list, separated by comma.
data_source = maxwell1
# data source "mysql1" type
maxwell1.type = maxwell
# kafka server which maxwell write binlog into.
maxwell1.kafka.server = 127.0.0.1:9092
# kafka topic which maxwell write binlog into.
maxwell1.kafka.topic = world
# kafka groupid used for consumer.
maxwell1.kafka.groupid = bireme
# set the IP address for bireme state server.
state.server.addr = 0.0.0.0
# set the port for bireme state server.
state.server.port = 80805、修改配置文件,vim etc/maxwell1.properties(表映射配置)
note:maxwell1.properties的maxwell1一定要和bireme的data_source保持一致
syncdb1.tb1 = public.tb1
syncdb2.tb1 = public.tb16、启动bireme,bin/bireme start
7、监控,http://192.168.1.129:8080/pretty (state.server.addr:state.server.port)
6、测试
1、mysql数据源
insert into tb1 select 1,'a';
insert into tb1 select 2,'b';2、pgsql目标数据库
syncdb=# select * from tb1;
a | b
---+------------
1 | a
2 | b
(2 rows)
7、优势和存在问题
1、优势
1、可以实现多个库表的汇总功能,syncdb1.tb1/syncdb2.tb1 可以汇总到pgsql的一张表tb1中
2、中间使用kafka消息队列,对于大数据量性能方面提升较好2、存在问题
1、maxwell会***数据源库,生成maxwell库,用来存在相应binlog消费位点position信息,只能在数据源生成库
2、第一次启动maxwell时,只能以当前的binlog position位点开始解析,事先需要先同步数据源数据库到目标数据库的一份全量数据