概述
线上系统挂了,服务异常了,响应超时了;系统运行结果不符合预期。。。
用户被影响,甲方爸爸不开心,后果很严重。
从某种意义上讲,“在用户遇到问题之前把问题解决,问题也就不算问题了”。
文章概要:线上环境痛点》解决方案》想象空间。
1、痛点
以下痛点是本公司实践中遇到的痛点,痛点或许不具备通用性,但思路却可以借鉴。
1.1、在服务发布时,我们经常会遇到如下的问题
- 服务刚发布,是否部署成功;
- 服务刚发布,版本是否正确(实例运行版本是否是我想要部署的版本);
- 服务刚发布,文件是否缺失;
如果服务实例较少,挨个上服务器检测,也是可行的,但目前稍微有点用户的系统,都是多实例部署,一个机房动辄几十上百个实例,挨个上服务器费时费力。
事实上,如果CI & CD 给力,以上问题都将不再是问题。
1.2、在服务发布后,也会有如下问题
- 服务是否可用;
- 单个服务可用,但系统链路是否畅通呢;
- 同一个机房不同实例代码是否一致(人工疏忽、运维系统 等问题导致不一致);
此外,我们公司还涉及本地化部署(将公司系统打包部署到其他公司),本地化部署一段时间需要部署新版本,但我们却不知道上次部署的系统是什么时候的版本。直接部署最新版本?系统太大,关联系统太多,所有系统部署最新版本,部署及验证耗时费力,成本太高,肯定不行。
1.3、管理诉求
- 发布故障:在发布完成后有故障则立即告警;
- 系统运行故障:运行有故障则立即告警,力争比用户早发现异常;
- 监控自动化:总不能挨个实例看控制台吧;
- 接收告警方便高效:相关责任方能方便接收到消息(不考虑邮件);
- 监控系统本身稳定:没有收到告警就一定是没有故障吗,是否是监控系统本身故障了呢;
2、解决方案
目前市面上有很多的监控系统,稳定高效、历经众多大厂生产系统检验,如Zabbix、Prometheus(普罗米修斯)等。
但最终我并没有选择这些监控系统,而是自己搭建一套。为什么自己构建,自己搭建的比他们更优秀吗,当然不是。
更优秀的不一定是最好的,更合适的才是最好的。
自行搭建监控系统原因如下:①这些系统太重,而我仅仅是监控一个业务模块的几个服务而已;②这些系统属于公司级别的监控,需要公司级别去推行,而我需要的是几天就能上线监控系统;③这些系统面向大众,监控方案也是通用的,而我需要自己定制化一些监控指标。
通用的东西不易做精细,越定制化,做好的概率越大。
2.1、监控如何做
2.1.1、服务正常运行监控
监控端口是否可行呢?肯定不可行,端口通信正常,并不代表服务正常,所以最终选择在服务里新增专用的监控接口;
2.1.2、监控告警通知
邮件?直接pass,谁会整天看邮件呢,公司用钉钉,所以最终选择了钉钉群机器人;
2.1.3、告警内容
越少越好,只告警真正核心的内容,否则通知泛滥,反而没人关注了,公司那么多系统监控的邮件你看了多少呢?如果确实有大量内容需要通知(不是告警),请使用单独的群通知。
2.2、监控实现-代码改造
不推荐使用业务接口用于监控,监控接口应该支持快速响应且资源消耗极低。
当然,做业务级别的监控除外,业务级别监控应合理评估资源消耗,不能影响正常业务。
2.2.1、服务运行监控接口
代码中新增独立的监控接口,请求接口返回数据则表示服务正常;
@ApiOperation(value = "测试接口")
@RequestMapping(value = "/test", method = RequestMethod.GET)
public int test() {
return 1;
}
以上接口简单粗暴,返回1则表示正常,这也是第一个版本的监控实现。
最新版本的监控接口如下,原因见【相同机房不同实例版本一致监控】。
@ApiOperation(value = "查询当前服务版本号,开发版本号_修改版本号")
@RequestMapping(value = "/getVersion", method = RequestMethod.GET)
@ResponseBody
public String getVersion() {
String version = new StringBuilder().append(Version.developVersion).append("_").append(Version.modifyVersion).toString();
return version;
}
2.2.2、系统链路监控
对于固定业务而言,整体的系统链路是固定的,系统A调用系统B,系统B调用系统C。所以直接在A、B 、C系统中新增调用链接口,监控时仅需监控最上层服务A,如果调用链路有异常,则告警。
@ApiOperation(value = "测试服务调用链,返回调用链上的 log.AppName,服务IP,当前时间戳")
@RequestMapping(value = "/testCallChain", method = RequestMethod.POST)
@ResponseBody
public String testCallChain(@RequestBody CloudRequestVo cloudRequestVo) throws Exception {
String localVersion = new StringBuilder().append(cloudRequestVo.getCloudTraceID()).append(" ==> ").append(LogUtil.getCloudTraceID()).toString();
String nextService = bServiceFeignClient.testCallChain(cloudRequestVo);
return new StringBuilder(nextService).append(" <== [").append(LogUtil.getCloudTraceID()).append("]").append("[ServiceStartTime]").append(serviceStartTime).append("[Version]").append(getVersion()).toString();
}
仔细看代码,会发现服务响应内容中包含了调用链上每个服务的响应信息,这些信息里包含了CloudTraceID(含有当前实例IP、当前实例名字、当前请求时间)、ServiceStartTime(系统启动时间)、Version(系统版本信息);
2.2.3、相同机房不同实例版本一致性监控
细心的同学可能会发现,在【系统链路监控】中服务的响应数据包含了系统版本信息(Version),这个便是用于监控相同机房不同实例版本是否一致。
监控原理:
- ①开发人员完成开发后,只要需要发布生产就必须修改代码中的版本信息,版本号加1;
- ②监控脚本请求同一个机房相同服务后,若发现返回的版本信息不一致,则告警;
或许有同学会说,这种手段需要人为修改代码,忘记修改怎么办?
我们公司用的是Jenkins编译,所以我修改了相关代码,Jenkins编译时会校验版本号是否递增,如果未递增,则直接不允许编译。
/**
* Desc: 版本信息.
* developVersion:开发版本号,必须与SVN地址上的版本号一致(格式请勿改变,只能修改数字,否则Jenkins可能不允许编译)。
* modifyVersion:修改版本号,每次修改代码只要需要编译发布就必须递增该版本号,加1即可(格式请勿改变,只能修改数字,否则Jenkins可能不允许编译)。
*/
public class Version {
// start
public static int developVersion = 8102;
public static int modifyVersion = 9;
// end
// 注意:start、end中间不能加任何东西,只允许修改版本号。
}
Note:
- 为避免监控接口地址和业务接口地址冲突,建议所有监控地址统一前缀,如:
- 服务运行监控接口地址:IP:PORT/test/getVersion ;
- 系统链路监控地址:IP:PORT/test/testCallChain;
- 相同机房不同实例版本一致性监控接口地址:直接使用getVersion接口返回数据,不单独开接口;
PS:版本一致性监控,最初考虑使用命令SSH连接远程服务器执行shell脚本做校验,此方案太繁琐被pass了。
2.3、监控实现-监控及告警
2.3.1、开启钉钉群机器人
钉钉群机器人用于接收告警信息。如何开启钉钉群机器人,此处不赘述了。开启机器人后,拿到webhook地址,则可以使用http请求向钉钉群发消息了。
详细说明参考钉钉开放平台文档:https://ding-doc.dingtalk.com/doc#/serverapi2/qf2nxq 。
2.3.2、监控实现
准备工作:
待监控实例的IP、端口,并按实例及机房分组;
待监控业务的顶层实例IP、端口;
监控逻辑:
定时请求监控接口,如果有异常,则调用钉钉机器人接口告警。
监控频率:
频率不宜过高,影响业务就不好了。(PS监控接口都是相当轻量的接口)
调用链监控频率建议设置长一些,毕竟服务连通性正常,调用链异常可能性较少。
监控正常通知:
没有收到告警就一定是没有故障吗,是否是监控系统本身故障了呢。
所以还需要每天定时向监控群发个通知“XXX监控运行正常”。
2.3.3、监控平台
只要能访问生产服务,且能发起Http请求就可以。
我使用的是 XXL-JOB作为监控平台,直接使用GLUE模式,可以随时完善监控代码,并查看监控系统运行日志。使用教程可以查看XXL-JOB官方教程http://www.xuxueli.com/xxl-job/#/。
公司同事可直接联系我获取监控脚本,替换待监控实例的IP端口即可使用(在新增专用测试接口前可临时使用已有接口)。
3、想象空间
3.1、告警渠道多元化
钉钉、微信、电话、企业内部通讯工具,只要渠道支持http请求就行。
3.2、业务监控
①业务级别监控、实例内部定制数据监控;
②集成已有监控系统,很多企业使用ELK作为日志系统,并有很多监控面板,完全可以采集监控面板的数据做通知告警。
3.3、自动化测试
当业务稳定后,完全可以实现自动化测试。代码一发,自动化测试一跑,发现并解决基础异常后,QA才介入进行复杂场景的测试,甚至当复杂业务场景的数据接收及响应数据的结构稳定清晰后,复杂场景也可以自动化测试。
3.4、其他通知场景
非得是系统监控告警吗?有了钉钉群机器人,任何提醒都可以做,比如重要的线上业务的阶段性通知,甚至是一些定时提醒。
4、后记
此监控系统从1月份上线,已经迭代优化运行半年多了。现在每天最开心的事情就是早晚收到监控系统正常运行的通知,而其他时间都不收到异常通知。此监控系统也确实在服务部署及线上运营过程中为我们提前发现了很多问题。
监控做了,系统就无忧了?告警了但没人从根本上解决问题,也并没什么卵用;兄弟业务团队的系统异常也可能互相影响。真正的系统高可用,得公司发力,从系统架构、业务、管理等方面综合下手,就不BB了。 当然自己的业务模块自己必须负责。
如果是一个业务模块,这套监控系统的思路或许很适合,如果是大规模微服务做统一监控,建议还是使用市面上成熟的监控系统。
思路比工具更重要,想象空间留给大家。
最后上张监控告警图片吧:
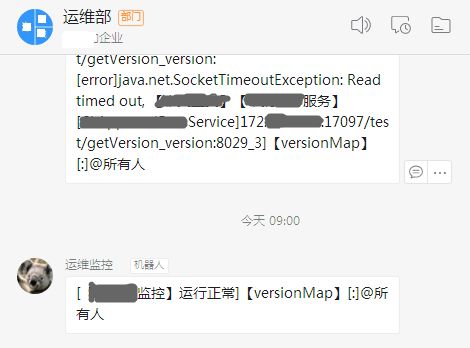
祝君好运!
Life is all about choices!
将来的你一定会感激现在拼命的自己!
【CSDN】【GitHub】【OSCHINA】【微信公众号】