机器学习方法篇(17)------集成学习
● 每周一言
做出决定,然后对决定负责。
导语
俗话说“三个臭皮匠,顶个诸葛亮”。单个模型的性能效果通常弱于多个模型的融合结果,而这种融合就叫做集成学习。那么集成学习有哪些常见模型?这种集成是否一定能提升模型效果呢?
集成学习
在做多人决策时,通常采取投票机制,即“少数服从多数”。我们不妨就先从投票讲讲什么是好的集成,什么是不好的集成。假设有三类样本,三种模型分别预测后进行结果融合,不同的融合结果如下图所示:
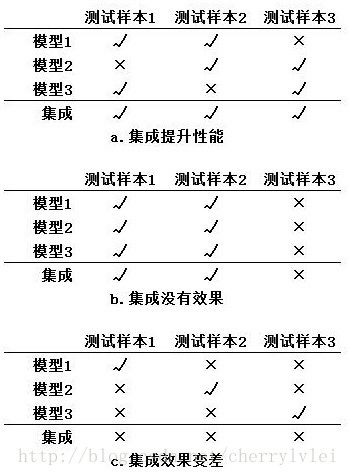
上图说明了集成学习的各个子模型需要满足两点要求: 准确性 和 多样性。准确性是指子模型把样本分类正确的概率,上图表现为a比c具备准确性;多样性指的则是子模型之间分类正确样本集合的重叠程度,上图表现为a比b具备多样性。通俗的讲就是,模型达到一定预测准确度之后,还要保证你学到的特征和我学到的特征不相同,才能同时发挥你我的作用,使融合得到正向结果。

事实上,准确性和多样性存在一定冲突。当准确性达到一定程度后,多样性一般就很难体现,需要牺牲一定的准确性来保证。
提高准确性是模型训练的普遍目标,因此不多讲,这里讲讲如何提高多样性。提高子模型多样性通常有两个方法:特征抽样 与 样本抽样。
特征抽样,是说每个子模型分别抽取一部分特征训练,让不同的特征在不同的模型当中分别发挥作用,提高多样性。同理,样本抽样是指每个子模型分别抽取一部分样本训练,让不同的样本在不同的模型中分别发挥作用,提高多样性。

说完子模型应具备的特点,下面讲讲其融合的方式。常见的融合方式分为 串行融合 和 并行融合 两种。
串行融合指的就是Boosting,Boosting算法最有名的代表是AdaBoost和GBDT。有关GBDT的介绍可以参见我之前的文章 机器学习方法篇(9)——梯度提升决策树GBDT。
并行融合指的则是Bagging,Bagging算法最有名的代表是决策树Bagging和RF随机森林。有关随机森林的介绍可以参见我之前的文章 机器学习方法篇(10)——随机森林。
除开上述两种融合方式,还有两种在各大算法比赛中作为杀手锏的融合方式 stacking 和 blending。其中blending采用不相交数据集训练不同的子模型,然后将结果取加权平均输出;而stacking稍微复杂点,但使用更为广泛,这里借用一张网上著名的图说明:
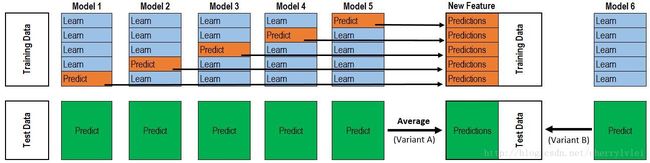
上图的大致意思是第一层子模型先对训练集进行K折预测,预测结果作为第二层模型的训练集再进行训练预测。
以上便是集成学习的讲解,敬请期待下节内容。
结语
感谢各位的耐心阅读,后续文章于每周日奉上,敬请期待。欢迎大家关注小斗公众号 对半独白!
