hadoop HA完全分布式模式原理即配置
1、概论
再hadoop1.x之前一直存在着单点故障问题,即nemenode只有一个。hadoop 2.x后引入HA的机制,HA是完全分布式结构。主要有两种一种是NFS(Network File System)方式,另外一种是QJM(Quorum Journal Manager)方式。用的最多的是QJM的方式,特点稳定性更好。

2、namenode数据同步
hadoop2.0的HA 机制有两个namenode,一个是active namenode,状态是active;另外一个是standby namenode,状态是standby。两者的状态是可以切换的,但不能同时两个都是active状态,最多只有1个是active状态。只有active namenode提供对外的服务,standby namenode是不对外服务的。active namenode和standby namenode之间通过NFS或者JN(journalnode,QJM方式)来同步数据。
为了确保两个namenode之间只有一个namenode处于激活状态,QJM方式本身就有fencing的功能通过多个journal节点增强了系统的健壮性,所以建议在生成环境中采用QJM的方式。确保一个时间内只有一个namenode处于Active状态,服务采用的是隔离(fencing)机制。
两个namenode之间的数据同步是通过QJM方式中的JournalNode(JN)来实现,active namenode会把最近的操作记录写到本地的一个edits文件中(edits file),并传输到JN中。standby namenode定期的检查,从JN把最近的edit文件读过来,然后把edits文件和fsimage文件合并成一个新的fsimage,合并完成之后会通知active namenode获取这个新fsimage。active namenode获得这个新的fsimage文件之后,替换原来旧的fsimage文件。

这样,保持了active namenode和standby namenode的数据的实时同步,standby namenode可以随时切换成active namenode(譬如active namenode挂了)。而且还有一个原来hadoop1.0的secondarynamenode,checkpointnode,buckcupnode的功能:合并edits文件和fsimage文件,使fsimage文件一直保持更新。所以启动了hadoop2.0的HA机制之后,secondarynamenode,checkpointnode,buckcupnode这些都不需要了。

图中的FailoverController组建是用来检测,Active NN节点故障,当FailoverControll检测到Active NN故障、宕机时,可以通过zookeeper自动将standby NN节点切换至activeNN。
3、QJM(Quorum Journal Manager )方式
QJM的方式可以解决上述NFS容错机制不足的问题。active namenode和standby namenode之间是通过一组journalnode(数量是奇数,可以是3,5,7...,2n+1)来共享数据。active namenode把最近的edits文件写到2n+1个journalnode上,只要有n+1个写入成功就认为这次写入操作成功了,然后standby namenode就可以从journalnode上读取了。可以看到,QJM方式有容错的机制,可以容忍n个journalnode的失败。

4、主备节点的切换
active namenode和standby namenode可以随时切换。当active namenode挂掉后,也可以把standby namenode切换成active状态,成为active namenode。自动切换则在active namenode挂掉的时候,standby namenode自动切换成active状态,取代原来的active namenode成为新的active namenode,HDFS继续正常工作。人工切换是通过执行HA管理的命令来改变namenode的状态,从standby到active,或者从active到standby。
自动切换需要使用zookeeper的机制来实行将standby namenode状态之间的自动切换为active NN。


5、Hadoop 2.x完全分布式集群的配置
(1)zookeeper的配置
a、安装目录
/home/unixnode/zookeeper-3.4.6/
b、配置zookeeper配置文件
cd /hadoop/zookeeper-3.4.6/conf/
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg
修改以下内容
dataDir=/home/unixnode/tmp/zookeeper
在最后添加:
server.1=node1:2888:3888
server.2=node2:2888:3888
server.3=node3:2888:3888
#然后创建一个tmp文件夹
mkdir /hadoop/zookeeper-3.4.6/tmp
#再创建一个空文件
touch /hadoop/zookeeper-3.4.6/tmp/myid
#对应的每个node的server的id加入每个节点中的myid文件中,每个有zookeeper不同,填入myid文件里
机器node1:
echo 1 > /home/unixnode/tmp/zookeeper/myid
node2机器:
echo 2 > /home/unixnode/tmp/zookeeper/myid
node3机器:
echo 3 > /home/unixnode/tmp/zookeeper/myid
(2)hadoop配置
a、配置hadoop-env.sh
export JAVA_HOME=/home/unixnode/hadoop/jdk1.8.0_152
b、配置core-site.xml
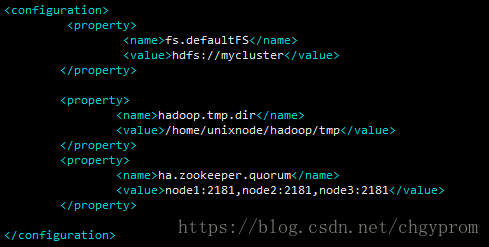
c、配置hdfs-site.xml


d、配置mapred-site.xml

e、配置yarn-site.xml

f、配置datanode 在slaves中(略)
(3)启动顺序*******务必按照顺序
1.启动zookeeper zkServer.sh start
2.格式化zkfc hdfs zkfc -formatZK
3、启动journalnode hadoop-daemon.sh start journalnode"
4、格式化namenode 选取一个节点namenode进行格式化hdfs namenode -format ,在将文件/tmp那个缓存文件复制到第二个namenode中
5、启动hdfs start-dfs.sh