GIS+=地理信息+大数据——Windows部署Pandas环境及代码测试验证
--------------------------------------------------------------------------------------
Blog: http://blog.csdn.net/chinagissoft
QQ群:16403743
宗旨:专注于"GIS+"前沿技术的研究与交流,将云计算技术、大数据技术、容器技术、物联网与GIS进行深度融合,探讨"GIS+"技术和行业解决方案
转载说明:文章允许转载,但必须以链接方式注明源地址,否则追究法律责任!
--------------------------------------------------------------------------------------
题记
Python Data Analysis Library 或 pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas提供了大量能使我们快速便捷地处理数据的函数和方法。你很快就会发现,它是使Python成为强大而高效的数据分析环境的重要因素之一。
本篇文章主要介绍一下在Windows环境下关于Pandas的部署,主要是一般在Windows作为开发环境,调试代码也比较方便,由于Linux我们直接使用pip install pandas安装即可,在Windows环境下可能还需要留意一些相关内容。
系统环境
- Windows 10
- Python 3.4(由于我需要使用GIScript2015,需要Python3.4支持,所以用户使用默认的Python2.6.7也可以)
- VS2012(可选)
- PyCharm(Python 开发的IDE,可选)
部署步骤
1、如果你安装了PyCharm,在安装任何Python相关的软件包都比较方便
打开PyCharm,点击文件菜单,选择setting,选择Project interprete,选择某个Python工程,点击右上角绿色+号,可以选择相关的Python库进行安装,例如Pandas

这种方式比较方便,不过在安装过程中也提示了相关错误:Microsoft Visual C++ 10.0 is required Unable to find vcvarsall.bat
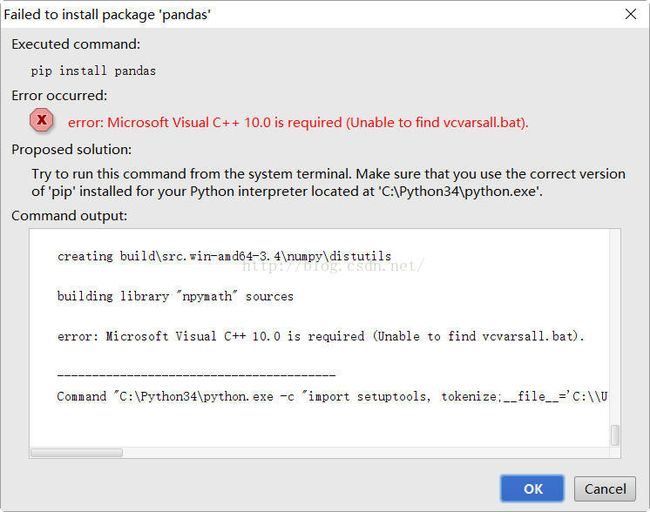
解决办法:
这是因为需要依赖于VC++2010库,如果你安装了VS201X系列IDE,你可以使用如下方式解决:
添加VS2010的环境变量,对应你安装相关VS系列环境变量,添加VS90COMNTOOLS关键字,然后设置相关的值即可。
如果你使用 python 2.x
-
Visual Studio 2010 (VS10):SET VS90COMNTOOLS=%VS100COMNTOOLS%Visual Studio 2012 (VS11):SET VS90COMNTOOLS=%VS110COMNTOOLS%Visual Studio 2013 (VS12):SET VS90COMNTOOLS=%VS120COMNTOOLS%Visual Studio 2015 (VS15):SET VS90COMNTOOLS=%VS140COMNTOOLS%
如果你使用 python 3.x
-
Visual Studio 2010 (VS10):SET VS100COMNTOOLS=%VS100COMNTOOLS%Visual Studio 2012 (VS11):SET VS100COMNTOOLS=%VS110COMNTOOLS%Visual Studio 2013 (VS12):SET VS100COMNTOOLS=%VS120COMNTOOLS%Visual Studio 2015 (VS15):SET VS100COMNTOOLS=%VS140COMNTOOLS%
如果部署环境没有安装任何VS环境,建议安装一个VS2010Express1。
http://download.microsoft.com/download/1/E/5/1E5F1C0A-0D5B-426A-A603-1798B951DDAE/VS2010Express1.iso
2、当然,如果你没有安装PyCharm,你可以在Windows环境下使用pip进行安装
a:下载pip部署包
https://pypi.python.org/pypi/pip#downloads
任意解压到某个位置
b:安装pip
C:\Users\Administrator>python c:\Python34\pip-8.0.2\setup.py install
running install
running bdist_egg
running egg_info
creating pip.egg-info
writing requirements to pip.egg-info\requires.txt
writing dependency_links to pip.egg-info\dependency_links.txt
writing pip.egg-info\PKG-INFO
writing entry points to pip.egg-info\entry_points.txt
writing top-level names to pip.egg-info\top_level.txt
writing manifest file 'pip.egg-info\SOURCES.txt'
warning: manifest_maker: standard file 'setup.py' not found
reading manifest file 'pip.egg-info\SOURCES.txt'
writing manifest file 'pip.egg-info\SOURCES.txt'
installing library code to build\bdist.win-amd64\egg
running install_lib
warning: install_lib: 'build\lib' does not exist -- no Python modules to install
creating build
creating build\bdist.win-amd64
creating build\bdist.win-amd64\egg
creating build\bdist.win-amd64\egg\EGG-INFO
copying pip.egg-info\PKG-INFO -> build\bdist.win-amd64\egg\EGG-INFO
copying pip.egg-info\SOURCES.txt -> build\bdist.win-amd64\egg\EGG-INFO
copying pip.egg-info\dependency_links.txt -> build\bdist.win-amd64\egg\EGG-INFO
copying pip.egg-info\entry_points.txt -> build\bdist.win-amd64\egg\EGG-INFO
copying pip.egg-info\not-zip-safe -> build\bdist.win-amd64\egg\EGG-INFO
copying pip.egg-info\requires.txt -> build\bdist.win-amd64\egg\EGG-INFO
copying pip.egg-info\top_level.txt -> build\bdist.win-amd64\egg\EGG-INFO
creating dist
creating 'dist\pip-8.0.2-py3.4.egg' and adding 'build\bdist.win-amd64\egg' to it
removing 'build\bdist.win-amd64\egg' (and everything under it)
Processing pip-8.0.2-py3.4.egg
creating c:\python34\lib\site-packages\pip-8.0.2-py3.4.egg
Extracting pip-8.0.2-py3.4.egg to c:\python34\lib\site-packages
Adding pip 8.0.2 to easy-install.pth file
Installing pip-script.py script to C:\Python34\Scripts
Installing pip.exe script to C:\Python34\Scripts
Installing pip3.4-script.py script to C:\Python34\Scripts
Installing pip3.4.exe script to C:\Python34\Scripts
Installing pip3-script.py script to C:\Python34\Scripts
Installing pip3.exe script to C:\Python34\Scripts
Installed c:\python34\lib\site-packages\pip-8.0.2-py3.4.egg
Processing dependencies for pip==8.0.2
Finished processing dependencies for pip==8.0.2
C:\Users\Administrator>
c:添加环境变量,将C:\Python34\Scripts;添加到环境变量
C:\Users\Administrator>path
PATH=C:\Python34\Scripts;C:\Python34\DLLs\Bin;C:\Program Files (x86)\NVIDIA Corporation\PhysX\Common;C:\Python34\;C:\instantclient_11_2;C:\app\Administrator\product\11.2.0\dbhome_1\bin;C:\Program Files (x86)\Common Files\NetSarang;C:\Windows\system32;C:\Windows;C:\Windows\System32\Wbem;C:\Windows\System32\WindowsPowerShell\v1.0\;C:\Program Files\Intel\WiFi\bin\;C:\Program Files\Common Files\Intel\WirelessCommon\;C:\strawberry\c\bin;C:\strawberry\perl\bin;C:\Program Files\Microsoft\Web Platform Installer\;C:\Program Files (x86)\Microsoft ASP.NET\ASP.NET Web Pages\v1.0\;C:\Program Files (x86)\Windows Kits\8.0\Windows Performance Toolkit\;C:\Program Files\Microsoft SQL Server\110\Tools\Binn\;C:\Program Files (x86)\SSH Communications Security\SSH Secure Shell;C:\Windows\SysWOW64;C:\Program Files\TortoiseSVN\bin;C:\WINDOWS\system32;C:\WINDOWS;C:\WINDOWS\System32\Wbem;C:\WINDOWS\System32\WindowsPowerShell\v1.0\;C:\Program Files (x86)\SSH Communications Security\SSH Secure Shelld:验证pip安装
C:\Users\Administrator>pip list
numpy (1.10.4)
pandas (0.17.1)
pip (8.0.2)
python-dateutil (2.4.2)
pytz (2015.7)
setuptools (12.0.5)
six (1.10.0)
wheel (0.29.0)e:安装pandas
C:\Users\Administrator>pip install pandas
Requirement already satisfied (use --upgrade to upgrade): pandas in c:\python34\lib\site-packages
Requirement already satisfied (use --upgrade to upgrade): pytz>=2011k in c:\python34\lib\site-packages (from pandas)
Requirement already satisfied (use --upgrade to upgrade): python-dateutil>=2 in c:\python34\lib\site-packages (from pandas)
Requirement already satisfied (use --upgrade to upgrade): numpy>=1.7.0 in c:\python34\lib\site-packages (from pandas)
Requirement already satisfied (use --upgrade to upgrade): six>=1.5 in c:\python34\lib\site-packages (from python-dateutil>=2->pandas)
3、当然,你也可以去pandas的官网下载软件包
https://pypi.python.org/pypi/pandas/0.17.1/#downloads
验证pandas
前面说了那么多部署,我们看看如果来执行一个简单的pandas代码验证一下。
由于Pandas可以用于大数据量的分析,当然特别适合于csv的文本数据,你可以先使用csv数据打开。
测试环境
-
- CPU:Intel(R) Core(TM) i7-4710MQ CPU @2.5GHz
- 内存:16GB DDR3
- 硬盘:C盘(SSD),其他盘为普通硬盘
Pandas提供了IO工具可以将大文件分块读取,完整加载约1500万条数据需要57秒左右。
__author__ = 'Administrator'
import pandas as pd
from datetime import datetime
if __name__ == '__main__':
starttime = datetime.now()
reader = pd.read_csv('c:\\1.csv', iterator=True)
try:
df = reader.get_chunk(5000000)
print(df.describe())
endtime = datetime.now()
costtime=(endtime-starttime).seconds
print('cost time:'+repr(costtime))
except StopIteration:
print ("Iteration is stopped.")当然,也可以通过使用不同分块大小来读取再调用 pandas.concat 连接DataFrame,chunkSize设置在150万条左右测试。
__author__ = 'Administrator'
import pandas as pd
from datetime import datetime
if __name__ == '__main__':
starttime = datetime.now()
reader = pd.read_csv('c:\\1.csv', iterator=True)
loop = True
chunkSize = 1500000
chunks = []
while loop:
try:
chunk = reader.get_chunk(chunkSize)
chunks.append(chunk)
except StopIteration:
loop = False
print ("Iteration is stopped.")
df = pd.concat(chunks, ignore_index=True)
print(df.describe())
endtime = datetime.now()
costtime=(endtime-starttime).seconds
print('cost time:'+repr(costtime))
测试结果
C:\Python34\python.exe D:/GIScipt/Zagi/JobWorker/Core/Sys/big.py
rate_code passenger_count trip_time_in_secs trip_distance \
count 14776615.000000 14776615.000000 14776615.000000 14776615.000000
mean 1.034273 1.697372 683.423593 2.770976
std 0.338771 1.365396 494.406260 3.305923
min 0.000000 0.000000 0.000000 0.000000
25% 1.000000 1.000000 360.000000 1.000000
50% 1.000000 1.000000 554.000000 1.700000
75% 1.000000 2.000000 885.000000 3.060000
max 210.000000 255.000000 10800.000000 100.000000
pickup_longitude pickup_latitude dropoff_longitude dropoff_latitude
count 14776615.000000 14776615.000000 14776529.000000 14776529.000000
mean -72.636340 40.014399 -72.594427 39.992189
std 10.138193 7.789904 10.288603 7.537067
min -2771.285400 -3547.920700 -2350.955600 -3547.920700
25% -73.991882 40.735512 -73.991211 40.734684
50% -73.981659 40.753147 -73.980125 40.753620
75% -73.966843 40.767288 -73.963898 40.768192
max 112.404180 3310.364500 2228.737500 3477.105500
cost time:62Pandas更多了解:
参考文献
使用Python Pandas处理亿级数据:http://www.justinablog.com/archives/1357