Spark 性能调优 序列化之使用kryo trouble shooting常见序列化错误
Kryo与Spark内部默认序列化机制优缺点
默认优点
默认情况下,Spark内部使用java的序列化机制,ObjectOutputStream/ObjectInputStream
对象输入输出流机制,来进行序列化,这种默认序列化机制的好处在于,处理起来比较方便,不需要我们自己手动做什么事情,只是,在算子里使用到的变量,必须是实现Serializable接口的,可序列化即可。
默认缺点
默认序列机制的效率不高,序列化的速度相对比较慢,序列化以后的数据,占用的内存空间还是比较大
kryo机制
spark支持使用kryo序列化机制,Kryo序列化机制,比默认的java序列化机制,速度要快,序列化后的数据要更小,大概是java序列化机制的1/10
kryo序列化如何使用
// 构建Spark上下文
SparkConf conf = new SparkConf()
.setAppName(Constants.SPARK_APP_NAME_SESSION)
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.registerKryoClasses(new Class[]{
CategorySortKey.class,
IntList.class});
首先第一步,在SparkConf中设置一个属性,spark.serializer, org.apache.spark.serializer.kryoSerializer类
Kryo之所以没有被作为默认的序列化类库的原因,主要因为kryo要求,如果达到最佳性能的话,一定要注册自定义类(比如,算子函数中使用到了外部自定义类型的对象变量这时,就必须注册类,否则kryo达不到最佳性能)
第二步,注册使用到的,需要通过kryo序列化的,一些自定义类,SparkConf.registerKryoClassed()
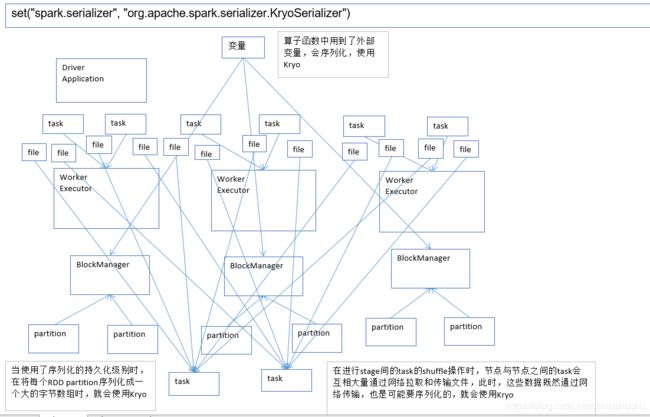
哪些地方需要使用Kryo
有三个地方
- 算子函数中使用到外部变量
算子函数使用外部变量,使用kryo以后,优化网络传输性能,可以优化集群中内存占用和消耗 - 持久化RDD时进行序列化,StorageLevel.MEMORY_ONLY_SER
优化内存占用和消耗;持久化RDD占用的内存越少,task执行的时候,创建的对象,就不至于频繁的占满内存,频繁发生GC. - shuffle
优化网络传输性能
什么样序列化错误?
client模式提交spark作业,观察本地打印的log,如果出现了类似于Serializable、Serialize等等相关的错误log,那应该就是序列化错误。
- 第一种,算子函数里用到了外部自定义类型的变量,那么此时自定义类型必须实现Implements Serializable接口 不然会出错
- 自定义类型,作为rdd类型的元素,那么自定义类型也必须可序列化 不然会出错
以上两种情况 比如 自定义排序对象就需要实现序列化
//第四步,自定义二次排序key
//第五步,将数据映射成格式的RDD,然后进行二次排序
JavaPairRDD sortKey2countRDD = categoryid2countRDD.mapToPair(new PairFunction, CategorySortKey, String>() {
private static final long serialVersionUID = -8624622546415913486L;
@Override
public Tuple2 call(Tuple2 longStringTuple2) throws Exception {
String countInfo = longStringTuple2._2();
long clickCount = Long.valueOf(StringUtils.getFieldFromConcatString(
countInfo, "\\|", Constants.FIELD_CLICK_COUNT));
long orderCount = Long.valueOf(StringUtils.getFieldFromConcatString(
countInfo, "\\|", Constants.FIELD_ORDER_COUNT));
long payCount = Long.valueOf(StringUtils.getFieldFromConcatString(
countInfo, "\\|", Constants.FIELD_PAY_COUNT));
CategorySortKey sortKey = new CategorySortKey(clickCount,
orderCount, payCount);
return new Tuple2(sortKey, countInfo);
}
});
JavaPairRDD sortedCategoryCountRDD =
sortKey2countRDD.sortByKey(false);//降序 拿取topn
- 不满足以上两种请情况,去使用第三方的,不支持序化的类型
Connection conn =
studentsRDD.foreach(new VoidFunction() {
public void call(Row row) throws Exception {
conn.....
}
});
Connection是不支持序列化的