回顾及总结--评价指标(分类指标)。
对学习器的泛化性能进行评估,不仅仅需要有效可行的实验估计方法,还需要有衡量模型泛华能力的评价标准,这就是性能度量。我们通常会根据不同的业务选出适合的业务指标。
评价指标大概有
1、回归的有:RMSE(平方根误差)、MAE(平均绝对误差)、MSE(平均平方误差)、Coefficient of determination (决定系数)。
2、分类的有:精度、召回率、精确率、F值、ROC-AUC 、混淆矩阵、PRC。
3、聚类的有:兰德指数、互信息、轮廓系数。
分类
1.精度(Accuracy)
意义:被正确分类的样本占总样本的比。
![]()
优点:简单
缺点:精度只是简单地计算出比例,但是没有对不同类别进行区分。因为不同类别错误代价可能不同。例如:判断这个病人是不是病危,如果不是病危错误判断为病危,那只是损失一点医务人员的时间和精力,如果是把病危的人判断为非病危状态,那损失的就是一条人命。他们之间存在重要性差异,这时候就不能用精度。对于样本不均衡的情况,也不是用精度来衡量。例如:有A类1000个,B类5个,如果我把这1005个样本都预测成A类,正确率=1000/1005=99.5%。
2. 混淆矩阵
混淆矩阵(Confusion Matrix)
|
|
预测为正样本 |
预测为负样本 |
| 标签为正样本 |
TP(True Positive对的正样本) |
FN(false Negative错的负样本) |
| 标签为负样本 |
FP(False Positive错的正样本) |
TN(true Negative 对的负样本) |
(1).True Postitve Rate(真正率):正样本中被预测对比例。
![]()
(2).False Negative Rate(假负率):正样本被预测错的比例。
![]()
(3).False Positive Rate(假正率):负样本被预测错的比例。
![]()
(4).True Negative Rate(真负率):负样本被预测对的比例。
![]()
(5).Accuracy(准确率):就是精度。
![]()
(6).Average per-class accuracy(平均准确率):每个类别下的准确率的算术平均。

3.精确率(Precision)
意义:查准。就是预测出来为正样本的结果中,有多少是正确分类。
![]()
通俗理解:做个谨慎认真的人,分类阈值较高
4.召回率(recall)
意义:真实为正样本的结果中,有多少是正确分类。
![]()
通俗理解:宁杀错不放过,分类阈值较低
但是,两者有时候就比较难去平衡到。
怎么说?
比如说,10个好苹果,10个坏苹果。
|
|
预测为好苹果 |
预测为坏苹果 |
| 标签为好苹果 |
2 |
8 |
| 标签为坏苹果 |
0 |
10 |
准确率为(2+10)/20=0.6;
精确率为(2)/2=1
召回率为(2)/10=0.2
虽然 精确率很高,但是不能说明这个模型很好。
再举个栗子。
10个好苹果,10个坏苹果。
|
|
预测为好苹果 |
预测为坏苹果 |
| 标签为好苹果 |
10 |
0 |
| 标签为坏苹果 |
10 |
0 |
准确率为(10)/20=0.5;
精确率为(10)/20=0.5
召回率为(10)/10=1
虽然召回率很高,但是不能说明这个模型很好。
所谓鱼与熊掌不兼得。(虽然这两个栗子都有点极端)。但是如果你想检测更多准确地正样本出来,出错是必不可少的。
这时候下面几个指标就出来了~~~
5.F值(F1-score)
通俗的语言就是:β 越大,Recall的权重越大, 越小,Precision的权重越大。
由于Fβ Score 无法直观反映数据的情况,同时业务含义相对较弱,实际工作用到的不多。
意义:精确率与召回率的调和平均值,它的值更接近于Precision与Recall中较小的值
(β=1)
补充:调和平均数是各变量值倒数的算术平均数的倒数,因而也称为倒数平均数。其计算形式也有简单调和平均数和加权调和平均数两种。加权调和平均数按照调和平均数的定义,是各变量值倒数的加权算术平均数的倒数。

6.ROC
ROC叫作受试者工作特性曲线,反应敏感度和特异度连续变量的综合指标。纵坐标为敏感度,横坐标是特异度。
ROC是一个以TPR为纵坐标,FPR为横坐标构造出来的一幅图。
我们当然希望TPR越高越好,因为证明覆盖率高;我们也希望FPR越低越好,这证明精确率高。
在鱼与熊掌不能兼得的时候,我们找一个界值,这个值越靠近左上角越好。
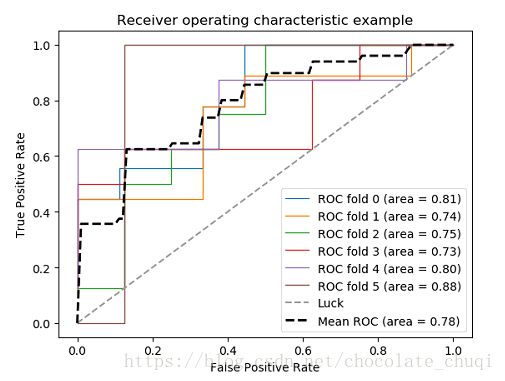
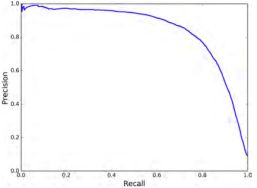
简单,直观,可以通过图直接判断。而且把灵敏度和特异性结合,可以同时衡量两者关系。一般来说,如果ROC是光滑的,那么基本可以判断没有太大的overfitting。
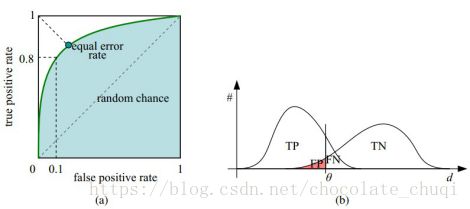
ROC曲线和它相关的比率
(a)理想情况下,TPR应该接近1,FPR应该接近0。
ROC曲线上的每一个点对应于一个threshold,对于一个分类器,每个threshold下会有一个TPR和FPR。
比如Threshold最大时,TP=FP=0,对应于原点;Threshold最小时,TN=FN=0,对应于右上角的点(1,1)
(b)随着阈值theta增加,TP和FP都减小,TPR和FPR也减小,ROC点向左下移动;
注:ROC可以在正负样本非均衡中使用原因是:纵坐标TPR只是正样本的正确预测概率,而FPR只是负样本中预测错误的概率,和比例没有关系。
7.AUC
AUC(Area under Curve):Roc曲线下的面积,介于0.1和1之间。Auc作为数值可以直观的评价分类器的好坏,值越大越好。
Auc = 1 ,完美分类,对应于roc可以完全做到(1,1)的点。
0.5
AUC的物理意义是任取一个正例和任取一个负例,正例排序在负例之前的概率。AUC反应的是分类器对样本的排序能力。另外值得注意的是,AUC对样本类别是否均衡并不敏感,这也是不均衡样本通常用AUC评价分类器性能的一个原因。
8.比较PR曲线,F1值,ROC曲线,AUC值
PR线是以Precision为纵坐标、Recall为横坐标。ROC是以为TPR为纵坐标、FPR为横坐标。在ROC空间,ROC曲线越凸向左上方向效果越好,因为这说明精确率高且覆盖率大。与ROC曲线左上凸不同的是,PR曲线是右上凸效果越好。
ROC和PR曲线都被用于评估机器学习算法对一个给定数据集的分类性能,每个数据集都包含固定数目的正样本和负样本。而ROC曲线和PR曲线之间有着很深的关系。
定理1:对于一个给定的包含正负样本的数据集,ROC空间和PR空间存在一一对应的关系,也就是说,如果recall不等于0,二者包含完全一致的混淆矩阵。我们可以将ROC曲线转化为PR曲线,反之亦然。
定理2:对于一个给定数目的正负样本数据集,一条曲线在ROC空间中比另一条曲线有优势,当且仅当第一条曲线在PR空间中也比第二条曲线有优势。(这里的“一条曲线比其他曲线有优势”是指其他曲线的所有部分与这条曲线重合或在这条曲线之下。)
当正负样本差距不大的情况下,ROC和PR的趋势是差不多的,但是当负样本很多的时候,两者就截然不同了,ROC效果依然看似很好,但是PR上反映效果一般。解释起来也简单,假设就1个正例,100个负例,那么基本上TPR可能一直维持在100左右,然后突然降到0.如图,(a)(b)分别为正负样本1:1时的ROC曲线和PR曲线,二者比较接近。而(c)(d)的正负样本比例不为为1:1,这时ROC曲线效果依然很好,但是PR曲线则表现的比较差。这就说明PR曲线在正负样本比例悬殊较大时更能反映分类的性能。
两者都要看光不光滑,如果不光滑说明有很大问题是过拟合。
AUC(Area Under Curve)即指曲线下面积占总方格的比例。有时不同分类算法的ROC曲线存在交叉,因此很多时候用AUC值作为算法好坏的评判标准。面积越大,表示分类性能越好。
F1兼顾了分类模型的准确率和召回率,可以看作是模型准确率和召回率的调和平均数,最大值是1,最小值是0。
--摘自
http://www.fullstackdevel.com/computer-tec/data-mining-machine-learning/501.html
参考:
https://blog.csdn.net/heyongluoyao8/article/details/49408319
https://blog.csdn.net/a819825294/article/details/51699211
https://www.zhihu.com/search?type=content&q=RMSE%20MAE%20MSE
https://zhuanlan.zhihu.com/p/36305931