国际化支持概念与理解
国际化支持
Globalization(G11N)
首先明确G11N的概念划分,只有一个公式:
G11N = I18N +L10N
其中I18N 指的是internationalization, L10N 指的是localization。
其实i18n 和l10n 区别还是挺大的,i18n更多指的是在编程技术上支持产品实现国际化,而l10n则指的是本地化相关,包括翻译质量等等这些。将这两点划分开才能更好地理解国际化支持的内容。
i18n 支持定义
首先在做java国际化支持分析之前,先给出我司关于i18n支持程度的一个定义:,
level 1: 输入输出产品安装相关,包括键盘输入法、路径等等
level 2: 与locale相关的,比如日历,日期,数字格式,排序,currency等
level 3: 就是指的string 抽取,以及layout显示相关。
三者并没有上下级层级关系,而是并行的。
区分i18n supported locales 和l10n supported locales
明确了i18n和l10n的各自概念范围,那么就有一个问题了,这两者所对应的支持locale 是否是一致的呢?这个大概公说公有理婆说婆有理吧,但是明确这两者的区别还是蛮重要的,如下图所示:
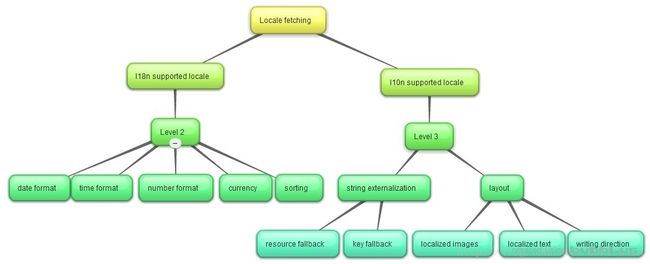
可以看出,i18n supported locales影响的是level 2的支持范围,而l10n supported locales则影响的是level3 的支持范围。
在很多情况下,由于产品的市场覆盖和预算要求,只能支持部分locale的本地化,但是产品又希望在英文的产品界面下,能够对其他locale的用户有比较友好的展示,比如日历和数字等等,这种情况下,两个locale support的集合就有了不一致。但并非所有的产品经理都觉得在英文页面上展示非英文的数字格式等是合理的需求,所以此时两者的取值集合是一致的。
总的来说,虽然两个locale set的取值集合可能会一致,但是从概念的角度来说,还是应该明确地区分,同时也建议程序员在设计i18n framework的时候,将两者分开,以保留更多的灵活度,当然,由于分开的设计也可能会引入各自locale fallback 行为的不一致,这一点会在后面详细讨论。
locale解析
在此之前
在locale被解析之前,有一些规范化的工作可能会有必要,譬如说locale 字串本身的格式化和locale 的定制化映射,具体取决于所用的编程语言和技术框架,例如java就无需这些处理,但是比如extjs可能就需要开发人员特殊注意。
locale 规范化
包括两个方面:
1)locale字串大小写
2)下划线还是短横线: dash vs underscore?
定制映射表
譬如extjs无法处理 一些常见的locale映射,例如:
zh-Hant-TW -> zh-TW
zh-Hans-CN -> zh-CN
因此在这种情况下,可能需要将locale进行映射,拿到映射的locale进入下一步的解析工作。其实本质上这个定制的映射表也就是一种locale fallback行为的定义。
locale fallback
这一节是我比较不喜欢的章节……
locale fallback我个人还是比较喜欢java的fallback 行为的,定义的很清晰很规范,因此在这里我也主要讲一下java的fallback机制吧。
在搞明白java的fallback机制之前,首先要了解locale的格式组成。
locale
locale的BCP 47标准
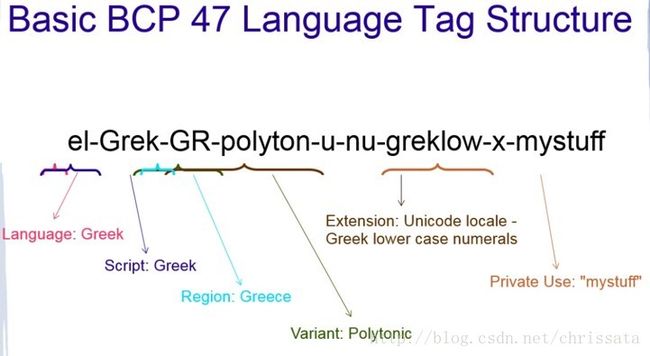
可见一共可以由下面几个部分:
Language
Script
Country(region)
Variant
Extensions
Private Use
常见的locale大概就到variant就很长了……
以zh-Hans-CN为例, zh就是language,Hans就是script,CN就是country(region)部分了。
结构直接用L-S-C-V代表了比较简洁明了
Java locale fallback 机制
知道了LSCV,后面就非常简单啦
就是一个rule + 2个特例:
一个rule是指:
First keep L & S, remove V, C in order;
Then let S = NULL, Remove V, C in order.
L-S-C-V
L-S-C
L-S
L-C-V
L-C
L
两个特例是指 zh-cn/zh-tw 和另外一个 norwegian的语言,如下。
[L(“zh”), S(“Hant”), C(“TW”)]
[L(“zh”), S(“Hant”)]
[L(“zh”), C(“TW”)]
[L(“zh”)]
norwegian:
[L(“nb”), C(“NO”), V(“POSIX”)]
[L(“no”), C(“NO”), V(“POSIX”)]
[L(“nb”), C(“NO”)]
[L(“no”), C(“NO”)]
[L(“nb”)]
[L(“no”)]