基于Hive+sparkSQL的人力资源系统实例
1.功能介绍:

2.数据源介绍:
2.1employee职工信息:
职工姓名,职工id,职工性别,职工年龄,入职年份,职位,部门id
Michael,1,male,37,2001,developer,2
Andy,2,female,33,2003,manager,1
Justin,3,female,23,2013,specialist,3
John,4,male,22,2014,developer,2
Herry,5,male,23,2010,developer,1
Brewster,6,male,27,2001,manager,2
Brice,7,female,33,2003,manager,3
Justin,8,male,23,2013,specialist,3
John,9,male,22,2014,developer,1
Herry,10,female,27,2010,specialist,32.2dept部门信息:
部门名称,部门编号
management,1
development,2
HumanResouce,32.3checkwork职工考勤信息
职工id,年,月,加班小时数,迟到小时数,旷工小时数,早退小时数
1,2015,12,0,2,4,0
2,2015,8,5,0,5,3
3,2015,3,16,4,1,5
4,2015,3,0,0,0,0
5,2015,3,0,3,0,0
6,2015,3,32,0,0,0
7,2015,3,0,16,32,3
8,2015,19,0,0,0,3
9,2015,6,0,2,4,0
10,2015,10,30,0,2,2
1,2014,12,56,40,0,22
2,2014,12,4,2,4,11
3,2014,12,5,8,8,20
4,2014,12,7,0,12,8
5,2014,12,1,3,7,9
6,2014,12,0,2,11,10
7,2014,12,2,1,11,14
8,2014,12,0,0,6,18
9,2014,12,6,1,8,17
10,2014,12,0,2,2,22.4salary工资信息
职工id,工资
1,5000
2,10000
3,6000
4,8000
5,5000
6,11000
7,15000
8,5500
9,6500
10,45003.创建数据库
//创建与使用HRS数据库
sqlContext.sql("create database HRS")
//使用数据库
sqlContext.sql("use HRS")4.创建数据表
特别说明:
row format delimited fields terminated by ‘,’
lines terminated by ‘\n’
每一行字段以,分隔 每一行以\n分隔
以后不再说明
4.1创建员工数据表
sqlContext.sql("create table if not exists employee"
+"(name String,id Int,gender String, age Int,year int,position String, deptId int)"
+"row format delimited fields terminated by ','lines terminated by '\n'")4.2创建 部门数据表
sqlContext.sql("create table if not exists deparment
(name String,deptID INT)"
+"row format delimited fields terminated by ','lines terminated by '\n'")4.3创建考勤表
sqlContext.sql("create table if not exists attendance(id int,year int,"
+"month int,overtime int,latetime int,absenteeism int,leaveearlytime int)"
+"row format delimited fields terminated by ','lines terminated by '\n'")4.4创建工资表
sqlContext.sql("create table if not exists salary(id int,salary int)"
+"row format delimited fields terminated by ','lines terminated by '\n'")5.加载数据
说明:
从本地的路径下加载数据,不从hdfs上加载数据 overwrite表示覆盖当前表的数据
5.1本地加载员工信息
sqlContext.sql("load data local inpath '/home/data/hrms/employee.txt'"
+"overwrite into table employee")5.2本地加载部门信息
sqlContext.sql("load data local inpath '/home/data/hrms/dept.txt'"
+"overwrite into table deparment")5.3本地加载考勤信息
sqlContext.sql("load data local inpath '/home/data/hrms/checkWork.txt'"
+"overwrite into table attendance")5.4本地加载工资信息
sqlContext.sql("load data local inpath '/home/data/hrms/salary.txt'"
+"overwrite into table salary")6查询
6.1查看各个表的schema信息
//员工
sqlContext.sql("select *from employee")
//部门
sqlContext.sql("select *from deparment")
//考勤
sqlContext.sql("select *from attendance")
//工资
sqlContext.sql("select *from salary") 部门职工数的查询,将employee表与department join操作,根据部门名称分组,统计部门员工数量
sqlContext.sql("select d.name ,count(*) as empNum from employee e join deparment d on e.deptid=d.deptid group by d.name").show结果:

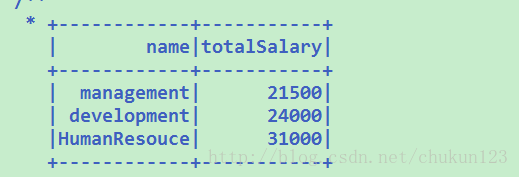
对各个部门的薪资的 总数排序
sqlContext.sql("select d.name ,sum(s.salary) as totalSalary from employee e join deparment d on e.deptid=d.deptid join salary s on e.id=s.id group by d.name order by totalSalary").show结果:
对各个部门的薪资的 平均值排序
sqlContext.sql("select d.name ,avg(s.salary) as avgSalary from employee e join deparment d on e.deptid=d.deptid join salary s on e.id=s.id group by d.name order by avgSalary").show结果:

查询各部门员工的考勤信息
sqlContext.sql("select d.name,sum(info.attinfo)
as deptattinfo,info.year from"+
+"overtime-latetime-absenteeism-leaveearlytime as attinfo"
+" from employee e join attendance a on e.id=a.id )"
+" info join deparment d on info.deptid=d.deptid group by d.name,info.year").show结果:

合并前面所有的查询
sqlContext.sql("select edept.name, edept.empNum,edst.totalSalary,edsa.avgSalary,eda.deptattinfo,eda.year from "
+"(select d.name ,count(*) as empNum from employee e join deparment d on e.deptid=d.deptid group by d.name) edept"
+" join "
+"(select d.name ,sum(s.salary) as totalSalary from employee e join deparment d on e.deptid=d.deptid join salary s on e.id=s.id group by d.name order by totalSalary) edst"
+" on (edept.name=edst.name)"
+" join "
+"(select d.name ,avg(s.salary) as avgSalary from employee e join deparment d on e.deptid=d.deptid join salary s on e.id=s.id group by d.name order by avgSalary) edsa"
+" on (edst.name=edsa.name) "
+" join "
+"(select d.name,sum(info.attinfo) as deptattinfo,info.year from"
+"(select e.id,e.deptid,a.year,a.month,overtime-latetime-absenteeism-leaveearlytime as attinfo from employee e join attendance a on e.id=a.id )"
+" info join deparment d on info.deptid=d.deptid group by d.name,info.year) eda"
+" on (edsa.name=eda.name)"
+" order by edept.name").show结果:

就是使用sparkSQL进行简单的创建,加载数据,查询数据的基本操作。
程序运行在spark集群,hive上,所以必须搭建spark与hive的环境。具体环境的搭建,参考网上教程,这里就不在演示环境的搭建过程了。