定义:正则表达式是一种可以用于模式匹配和替换的规范,一个正则表达式就是由普通的字符(例如字符a到z)以及特殊字符(元字符)组成的文字模式,它 用以描述在查找文字主体时待匹配的一个或多个字符串。正则表达式作为一个模板,将某个字符模式与所搜索的字符串进行匹配。注:区分大小写
Java中处理正则表达式的类:
java.lang.String 、 java.util.regex.Pattern(模式类) 、java.util.regex.Matcher(匹配类)
例子:
String formula = "xa+xb+xc*(xd-xe)-xf/xg";
//第一种方式,用String.splite直接分隔
String spiltRules = "\\+|-|\\*|/|=|\\(|\\)";
String[] array = formula.split(spiltRules);
for (String s : array) {
System.out.println(s);
}
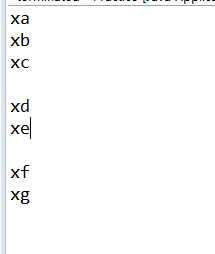
控制台输出结果:
//第二种,用.Pattern和Matcher模式
List list=new ArrayList();
Matcher matcher=Pattern.compile("\\bx\\w{1}").matcher(formula);
while (matcher.find()) {
list.add(matcher.group(0));
System.out.println(matcher.group(0));
}
System.out.println(list);
控制台输出结果:
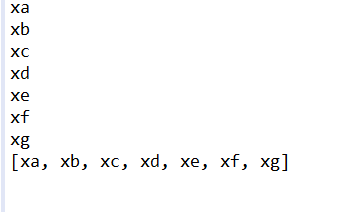
1、用formula.split()会出现空格,原因是在formula.split()之后,如果有两个连续的,规则中能匹配到的运算符,就会在array中出现空的一个元素,如用此方法分隔字符窜,要将分隔出来的元素存入变量集合。
2、如果使用java中Pattern.compile(),先定义匹配规则,这里"\\bx\\w{1}"意思为,以x开头,然后任意一位数字或者字母结束.匹配成功后存入新的list,由于利用正则表达式匹配相关需要的字段,就不会存在上面那种如果多个运算符连在一起,会出现空元素的情况,这个集合可以不用再经过处理就可以直接使用。
source="xa+xb+xc*(xd-xe)-xf/xg"
正则表达式通用匹配符
| 正则表达式 | 说明 | 示例 |
| . | 匹配任何单个符号,包括所有字符 | match="." result: x a + x b + x c * (x d - x e ) - x f / x g |
| ^xxx | 在开头匹配正则xxx | match="^x" result:xa |
| xxx$ | 在结尾匹配正则xxx | match=".g$" result:xg |
| [abc] | 能够匹配字母a,b或c | match="[xa]" result:x a x x x x x x |
| [abc][12] | 能够匹配由1或2跟着的a,b或c | |
| [^abc] | 当^是[]中的第一个字符时代表取反,匹配除了a,b或c之外的任意字符。 |
(“[^ab][^12].”, “c3#”) – true(“[^ab]..[^12]“, “xcd3″) – true |
| [a-e1-8] | 匹配a到e或者1到8之间的字符 | (“[a-e1-3].”, “d#”) – true(“[a-e1-3]“, “2″) – true |
| xx|yy | 匹配正则xx或者yy | (“x.|y”, “xa”) – true(“x.|y”, “y”) – true |
java正则表达式元字符
| 正则表达式 | 说明 |
| \d | 任意数字,等同于[0-9] |
| \D | 任意非数字,等同于[^0-9] |
| \s | 任意空白字符,等同于[\t\n\x0B\f\r] |
| \S | 任意非空白字符,等同于[^\s] |
| \w | 任意英文字符,等同于[a-zA-Z0-9] |
| \W | 任意非英文字符,等同于[^\w] |
| \b | 单词边界,也就是指单词和空格间的位置 |
| \B | 非单词边界 |
正则表达式量词
| 正则表达式 | 说明 |
| x? | x没有出现或者只出现一次 |
| x* | x出现0次或更多 |
| X+ | X出现1次或更多 |
| X{n} | X正好出现n次 |
| X{n,} | X出现n次或更多 |
| X{n.m} | X出现至少n次但不多余m次 |
例如:[abc]+表示a,b,c出现一次或者多次
(abc)+ 表示abc出现一次或者多次
正则表达式capturing group
Capturing group是用来对付作为一个整体出现的多个字符。你可以通过使用()来建立一个group。输入字符串中和capturing group相匹配的部分将保存在内存里,并且可以通过使用Backreference调用。
你可以使用matcher.groupCount方法来获得一个正则pattern中capturing groups的数目。例如((a)(bc))包含3个capturing groups; ((a)(bc)), (a) 和 (bc)。
Matcher类有start()和end()索引方法,他们可以显示从输入字符串中匹配到的准确位置。
列二:
\d 表示匹配一个数字字符。等价于 [0-9]。后面的{3}就是连续匹配三位.
所以\d{3}-\d{8} 和 \d\d\d-\d\d\d\d\d\d\d\d 的意思一样,代表"3个数字-8个数字"的格式的字符串.
注:
关于"\b"和"\\b"的区别:
\b : 就是正则表达式中单纯的语法;
\\b :这是java中转义(转译)字符,"\\"代表反斜杠. 在字符串中定义的话,在正则匹配规则中,等同于"\b".
Matcher matcher = ttern.compile("\\bx\\w{1}").matcher(formula);// 用正则匹配 就比如说这句,"\\bx\\w{1}"在最后使用的时候,就是"\bx\w{1}"
补充一点转译字符:
特殊字符:
\":双引号
\':单引号
\\:反斜线
控制字符:
\' 单引号字符
\\ 反斜杠字符
\r 回车
\n 换行
关于转译字符,详细一点的可以去这看看,或者去百度上搜索一下. http://blog.csdn.net/generalyy0/article/details/7307267
顺便提供一个正则表达式的使用语法说明,校验,测试的网站.