FPN-Feature Pyramid Networks论文理解
论文链接:https://arxiv.org/abs/1612.03144
FPN 创新点
- 低层特征信息与高层语义信息的特征融合
- 有利于小目标的检测
写在前面的话
FPN的全称是Feature Pyramid Networks[特征金字塔网络], 图像金子塔是什么?图像金字塔其实在很早便被提出,像比如SIFT,SURF,HOG等传统的特征提取方法均使用了图像金字塔,想了解传统特征提取方法的参考博文http://wanglichun.tech/algorithm/Sift.html,但是在深度学习中,一直没有被使用,其实主要原因在于深度学习中图像的计算量较大,采用金字塔,多一个scale就相当于多了一倍的计算量,这个时候内存很有可能扛不住了,可是为了达到多尺度的检测该怎么办呢?
那既然图像金字塔行不通,那我们是否可以在特征图上想想办法呢?毕竟特征图的感受野不一样~~~~
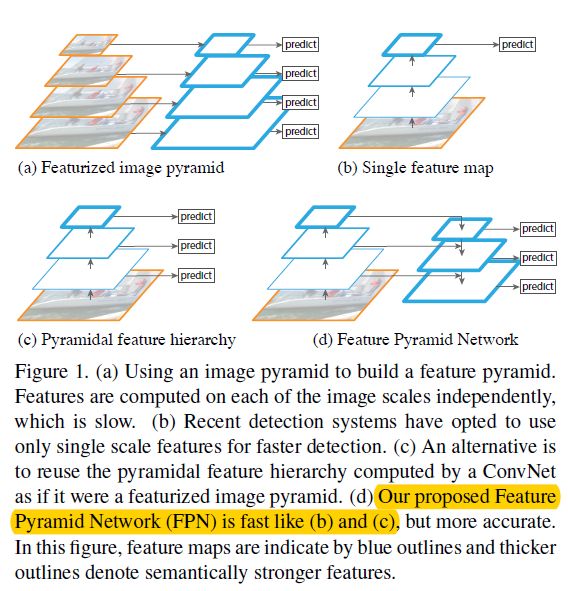
看下面这张图,图(a)代表的是图像特征金子塔(注意,背景是有图片的),图(b)是在一个特征图上进行预测,典型代表就是Faster R-CNN,图©是同时在多个特征图上进行预测,但是特征图间没有特征融合,代表作品就是SSD,图(d)就是本文的主角了。不仅仅在每个特征图进行预测,而且存在一条自顶到下的特征融合,将高层的语义信息与低层的高分辨率进行融合,提高特征的表达能力,更好的实现物体检测。
下面来详细介绍一下 Feature Pyramid Networks

先放一张图,其实FPN主要就包含两部分,一个是bottom-up pathway,另一个是top-down pathway
Bottom-up pathway
Bottom-Up pathway代表的是网络的前向传播过程,这个与正常的网络没有差别,论文中作者展示的是resnet网络,对于每一个stage(就是resnet中,特征图大小相同的一组层),作者定义了一个pyramid level(这里注意这个level在后面会频繁的使用,就是代表每个stage提取的不同大小的特征),并且使用每个stage的最后一层输出特征图作为predict的feature map,特别对于resnet,使用每一个residual block的output作为输出,这里用符号表示对应的卷积输出就是**{C2,C3,C4,C5}**对应stride就是{4,8,16,32}(注,这里没有使用conv1,作者说是由于它较大的内存消耗)
Top-down pathway 论文最大的创新点就在于此
该过程就是上图中右边部分的过程,作者通过对高层的feature map进行上采样,然后与低层feature map进行特征融合来进行predict,为什么要这样做呢?因为低层的特征虽然语义信息较少,但是其由于下采样的次数较少,所以其保留了更好的位置信息。(另外这里作者说明了,上采样采用最近邻方法进行)
那具体是怎么做的呢?
首先,对于C5(上面提到的,就是backbone网络的最后输出的特征图),利用1*1卷积操作,产生最初的feature map,然后对产生的feature map进行上采样,与相同大小的bottom-up map进行融合(bottom-up man就是前向传播时候的特征图),这里bottom-up采用1*1的卷积进行channel降维,然后与top-down map采用element-wise-add操作,最后在每个merge feature map上面利用3*3卷积来得到最终的feature map并进行预测,为什么用3*3呢?这里作者解释到,3*3可以减少上采样带来的失真效应,最终得到的feature map这里暂时表示为{P2,P3,P4,P5}
对于Top-down的特征图,论文中固定feature map的channel数为256.所以上面的channel降维都降到256就可以了
Applications
这里作者主要是在RPN以及faster rcnn为例进行了应用
首先对于RPN部分:
传统的RPN通过一个3*3的卷积产生256维的特征图,然后分别利用1*1的卷积分为两路,一路是进行是否是物体的判断,另一路是判断其坐标框的回归,是否为物体的定义以及bounding box的回归目标是对应的anchor。
FPN做了哪些改进呢?
作者主要是利用FPN替换了原始RPN只在单一的特征层进行操作,作者在每个level上进行RPN原始的操作(包括3*3以及后面的1*1进行分类和回归),因为这里是在所有的level上进行操作,所以就不需要在每个level进行多尺度的anchor了,这里就类似于SSD,分别在不同的level检测不同大小的物体,作者设置的是{P2,P3,P4,P5,P6}分别对应{ 3 2 2 , 6 4 2 , 12 8 2 , 25 6 2 , 51 2 2 32^2,64^2,128^2,256^2,512^2 322,642,1282,2562,5122},anchor的比例就是{1:2,1:1,2:1},所以一共是15个anchor
(注,这里作者一共设置了5个size,分别在5个层,这里作者解释到,P6是在P5层的基础上进行下采样得到的,用于检测512*515大小的目标,对应于resnet faster-rcnn中roi-pooling后面的那个卷积)
对于anchor的label与原始的anchor一致,都是IOU最大以及0.5以上为正,0.3以下为负
实验对比结果见下图:
从图中(c)可以看出,FPN的效果还是很赞的,AR代表平均召回率。
另外作者做了一些其他的对比实验,验证FPN网络中横向连接以及纵向融合的效果,其中d是只有横向连接,e是只有纵向融合,f是只在P2层进行特征提取,可见,d->e->f的效果在增加,均要比base-line的效果要好,但是比本文方法较差。可见对于横向连接,纵向融合还是有一定的效果的。这里anchor的数量为什么会差距那么大,主要原因是由于在不同的分辨率上,图像大小不一样,所以采样出来的额anchor数量也就不一样。并且从下面巨大数量的anchor也说明了anchor取得特别多,其实对于效果不一定就会有很大提升。

Fast R-CNN部分:
原始的Fast R-CNN部分,在最后的卷积层提取proposal,通过roi-pooling送入到后面的分类网络以及回归网络,在Fast R-CNN中,改变的方法自然是不仅仅在最后的卷积层,而是根据图像的尺寸选择不同的level进行特征提取,然后进行roi-pooling,那level应该如何选择呢?用下面的公式:
![]()
举个例子,首先对于k0的定义,如果采用resnet作为基础网络,由于其利用C4作为最后的特征提取层,所以设k0 == 4 , 这样对于输入为112*112的roi计算出来的k=3。
然后针对每一个level提取的roi,经过roi-pooling(7*7),后面接2个1024维的fc层,最后接分类和回归网络,这里就与fast-rcnn保持一致了。
这里需要注意的是,fast rcnn中,其实是在conv4后面接的roi-pooling,然后接conv5,然后接fc,而fpn中是在conv5后面接roi-pooling然后直接接fc层的。
下图是作者对fast rcnn部分的测试结果:可以看出FPN的效果还是挺明显的,另外跟RPN一样,作者同样做了一些横向的对比,对比结果可想而知,这里就不多说了。

下图是论文与其他算法的精度对比:

到这里,基本上对FPN网络的介绍就差不多了,FPN仍然采用two stage的方法,精度较faster r-cnn有所提高,但是速度相比较于ssd还是有很大的瓶颈,不过FPN的思想值得借鉴,这在之后的论文中也多次提到
补充:
- 问:横向连接的作用是什么?
答:如果不进行特征的融合(也就是说去掉所有的1x1侧连接),虽然理论上分辨率没变,语义也增强了,但是AR下降了10%左右!作者认为这些特征上下采样太多次了,导致它们不适于定位。
- 问:为什么 FPN 相比去掉深层特征 upsample(bottom-up pyramid)对于小物体检测提升明显?(RPN 步骤 AR 从 30.5 到 44.9,Fast RCNN 步骤 AP 从 24.9 到 33.9)
答:对于小物体,一方面它提高了小目标的分辨率信息;
另一方面,如图中的挎包一样,从上到下传递过来的更全局的情景信息可以更准确判断挎包的存在及位置。