CornerNet,CenterNet关键代码解读: kp,_decode,left pooling
今天大致看了一下CornerNet的代码,对其中的关键代码做一些整理。
由于CenterNet(CenterNet:Keypoint Triplets for Object Detection)是在CornerNet的基础上修改来的,所以基本是一致的
cornernet的主要结构基本都定义在./models/py_utils文件夹下,主干结构定义在./models/py_utils/kp.py这个文件夹内,部分结构也在kp_utils.py中实现,corner pooling在_cpools文件夹下使用c++语言实现。
接下来我主要总结了一下,网络的结构定义class kp(nn.Module),_decode()函数以及,corner pooling中的left pooling函数。
首先,我来介绍一下网络的定义 class kp(nn.Module),其在kp.py文件中定义,该类主要实现了网络的整体结构,以及train和test的前向的过程,可以说是本网络的精髓所在。
class kp(nn.Module):
def __init__(
self, n, nstack, dims, modules, out_dim, pre=None, cnv_dim=256,
make_tl_layer=make_tl_layer, make_br_layer=make_br_layer,
make_cnv_layer=make_cnv_layer, make_heat_layer=make_kp_layer,
make_tag_layer=make_kp_layer, make_regr_layer=make_kp_layer,
make_up_layer=make_layer, make_low_layer=make_layer,
make_hg_layer=make_layer, make_hg_layer_revr=make_layer_revr,
make_pool_layer=make_pool_layer, make_unpool_layer=make_unpool_layer,
make_merge_layer=make_merge_layer, make_inter_layer=make_inter_layer,
kp_layer=residual
):
super(kp, self).__init__()
## nstack是一个最开始我也没弄懂是干嘛的函数,后来突然想起来论文中给了intermediate supervision的介绍,才知道这个其实是实现的这个,翻译为中继监督,后面会有介绍,这个在作者的代码中默认取的是2
self.nstack = nstack
## decode就是网络输出了heatmap,embedding,offset后如何进行点匹配以及最终选择哪些点对作为结果的函数,这个类介绍完会去介绍那个函数。
self._decode = _decode
curr_dim = dims[0]
## self.pre定义的是网络的头部,网络先接了一个kernel size 7x7的conv以及一个residual结构
self.pre = nn.Sequential(
convolution(7, 3, 128, stride=2),
residual(3, 128, 256, stride=2)
) if pre is None else pre
### CornerNet的主干结构是hourglasses,这里是就是其主干结构,make_xx_layer都是定义在kp_utils.py文件中的,感兴趣可以看一下,这里不详细介绍了,知道其实hourglasses主干结构就可以了。**并且注意到了吗,这里的定义都使用了for循环 for _ in range(nstack),其实作者所有的结构都定义了两个,两个结构通过前面提到的中继监督连接到一起。**
self.kps = nn.ModuleList([
kp_module(
n, dims, modules, layer=kp_layer,
make_up_layer=make_up_layer,
make_low_layer=make_low_layer,
make_hg_layer=make_hg_layer,
make_hg_layer_revr=make_hg_layer_revr,
make_pool_layer=make_pool_layer,
make_unpool_layer=make_unpool_layer,
make_merge_layer=make_merge_layer
) for _ in range(nstack)
])
### hourglasses输出后,接一个卷积层
self.cnvs = nn.ModuleList([
make_cnv_layer(curr_dim, cnv_dim) for _ in range(nstack)
])
## 然后定义的是接的两个分支,分别去输出top left 以及 bottom right的分支
self.tl_cnvs = nn.ModuleList([
make_tl_layer(cnv_dim) for _ in range(nstack)
])
self.br_cnvs = nn.ModuleList([
make_br_layer(cnv_dim) for _ in range(nstack)
])
## keypoint heatmaps ,用于输出tl以及br的热图,这里是8 * 256 *256的
self.tl_heats = nn.ModuleList([
make_heat_layer(cnv_dim, curr_dim, out_dim) for _ in range(nstack)
])
self.br_heats = nn.ModuleList([
make_heat_layer(cnv_dim, curr_dim, out_dim) for _ in range(nstack)
])
## tags ## 用于输出 embeddings值 1 * 256 * 256的
self.tl_tags = nn.ModuleList([
make_tag_layer(cnv_dim, curr_dim, 1) for _ in range(nstack)
])
self.br_tags = nn.ModuleList([
make_tag_layer(cnv_dim, curr_dim, 1) for _ in range(nstack)
])
for tl_heat, br_heat in zip(self.tl_heats, self.br_heats):
tl_heat[-1].bias.data.fill_(-2.19)
br_heat[-1].bias.data.fill_(-2.19)
## 下面这三个其实是中继结构,即将输出再接入下一个输入,后面的train以及test函数中会用到。
self.inters = nn.ModuleList([
make_inter_layer(curr_dim) for _ in range(nstack - 1)
])
self.inters_ = nn.ModuleList([
nn.Sequential(
nn.Conv2d(curr_dim, curr_dim, (1, 1), bias=False),
nn.BatchNorm2d(curr_dim)
) for _ in range(nstack - 1)
])
self.cnvs_ = nn.ModuleList([
nn.Sequential(
nn.Conv2d(cnv_dim, curr_dim, (1, 1), bias=False),
nn.BatchNorm2d(curr_dim)
) for _ in range(nstack - 1)
])
### 这里定义的是输出的回归坐标 : 2 * 256 * 256
self.tl_regrs = nn.ModuleList([
make_regr_layer(cnv_dim, curr_dim, 2) for _ in range(nstack)
])
self.br_regrs = nn.ModuleList([
make_regr_layer(cnv_dim, curr_dim, 2) for _ in range(nstack)
])
self.relu = nn.ReLU(inplace=True)
def _train(self, *xs):
image = xs[0]
tl_inds = xs[1]
br_inds = xs[2]
## image 最先过的网络,是7x7的卷积,数据表示为inter,这里注意一下这个inter,后面会用到。
inter = self.pre(image)
## 保存输出的
outs = []
layers = zip(
self.kps, self.cnvs,
self.tl_cnvs, self.br_cnvs,
self.tl_heats, self.br_heats,
self.tl_tags, self.br_tags,
self.tl_regrs, self.br_regrs
)
## 这个for循环的意思就是对应的nstack。
for ind, layer in enumerate(layers):
kp_, cnv_ = layer[0:2]
tl_cnv_, br_cnv_ = layer[2:4]
tl_heat_, br_heat_ = layer[4:6]
tl_tag_, br_tag_ = layer[6:8]
tl_regr_, br_regr_ = layer[8:10]
#### 下面都没什么好说的,就是网络一层一层的过。
kp = kp_(inter)
cnv = cnv_(kp)
tl_cnv = tl_cnv_(cnv)
br_cnv = br_cnv_(cnv)
tl_heat, br_heat = tl_heat_(tl_cnv), br_heat_(br_cnv)
tl_tag, br_tag = tl_tag_(tl_cnv), br_tag_(br_cnv)
tl_regr, br_regr = tl_regr_(tl_cnv), br_regr_(br_cnv)
tl_tag = _tranpose_and_gather_feat(tl_tag, tl_inds)
br_tag = _tranpose_and_gather_feat(br_tag, br_inds)
tl_regr = _tranpose_and_gather_feat(tl_regr, tl_inds)
br_regr = _tranpose_and_gather_feat(br_regr, br_inds)
# 结果保存一下
outs += [tl_heat, br_heat, tl_tag, br_tag, tl_regr, br_regr]
##这里比较重要,这里就是中继结构的核心,还记得前面提到的inter吗?这里就是先将inter进行了self.inters_操作,然后将前面的输出cnv(哪里输出的上面找),过一下self.cnvs_结构,然后对其进行求和,之后过了relu以及self.inters结构,最后作为输入进入到nstack==1的结构,在来一遍,其实self.inters_与self.cnvs_的结构是一样的,都是卷积层。
if ind < self.nstack - 1:
inter = self.inters_[ind](inter) + self.cnvs_[ind](cnv)
inter = self.relu(inter)
inter = self.inters[ind](inter)
return outs
### test与train函数同理,唯一不同的是,train函数将nstack==0和nstack==1的输出都放到了output中,而test只试讲nstack==1的结果放到了output中这里就不详细介绍了。
def _test(self, *xs, **kwargs):
image = xs[0]
inter = self.pre(image)
outs = []
layers = zip(
self.kps, self.cnvs,
self.tl_cnvs, self.br_cnvs,
self.tl_heats, self.br_heats,
self.tl_tags, self.br_tags,
self.tl_regrs, self.br_regrs
)
for ind, layer in enumerate(layers):
kp_, cnv_ = layer[0:2]
tl_cnv_, br_cnv_ = layer[2:4]
tl_heat_, br_heat_ = layer[4:6]
tl_tag_, br_tag_ = layer[6:8]
tl_regr_, br_regr_ = layer[8:10]
kp = kp_(inter)
cnv = cnv_(kp)
if ind == self.nstack - 1:
tl_cnv = tl_cnv_(cnv)
br_cnv = br_cnv_(cnv)
tl_heat, br_heat = tl_heat_(tl_cnv), br_heat_(br_cnv)
tl_tag, br_tag = tl_tag_(tl_cnv), br_tag_(br_cnv)
tl_regr, br_regr = tl_regr_(tl_cnv), br_regr_(br_cnv)
outs += [tl_heat, br_heat, tl_tag, br_tag, tl_regr, br_regr]
if ind < self.nstack - 1:
inter = self.inters_[ind](inter) + self.cnvs_[ind](cnv)
inter = self.relu(inter)
inter = self.inters[ind](inter)
return self._decode(*outs[-6:], **kwargs)
decode这个函数的作用是处理模型的输出结果,利用(heatmap, emd,offset)的输出,求出模型的检测结果,下面介绍一下这个函数。
def _decode(
tl_heat, br_heat, tl_tag, br_tag, tl_regr, br_regr,
K=100, kernel=1, ae_threshold=1, num_dets=1000
):
batch, cat, height, width = tl_heat.size()
## 首先将top_left以及bottom right 利用sigmoid映射到0-1,
tl_heat = torch.sigmoid(tl_heat)
br_heat = torch.sigmoid(br_heat)
# perform nms on heatmaps 对其进行nms操作,其实就是maxpooling,保留max部分,kernel_size = 3 x 3。
tl_heat = _nms(tl_heat, kernel=kernel)
br_heat = _nms(br_heat, kernel=kernel)
## 在top left以及bottom right,找到最大的前K个点,并记录下他们的得分,位置,类别,坐标等信息,下面返回的结果分别代表的是:
## 类别得分,位置索引,类别,y坐标,x坐标
tl_scores, tl_inds, tl_clses, tl_ys, tl_xs = _topk(tl_heat, K=K)
br_scores, br_inds, br_clses, br_ys, br_xs = _topk(br_heat, K=K)
#下面是将坐标扩充, 为后面拿到所有的坐标组合做准备。这里扩充完之后变成了下面的样子 左边是横向的扩充,右边是纵向的扩充
#[1,1,1 [ 1,2,3,
# 2,2,2 1,2,3,
# 3,3,3] 1,2,3 ]
# 这样就可以组合出所有的枚举坐标了。也就是下面干的事情
tl_ys = tl_ys.view(batch, K, 1).expand(batch, K, K)
tl_xs = tl_xs.view(batch, K, 1).expand(batch, K, K)
br_ys = br_ys.view(batch, 1, K).expand(batch, K, K)
br_xs = br_xs.view(batch, 1, K).expand(batch, K, K)
#根据上面的索引,将offset拿出来。
if tl_regr is not None and br_regr is not None:
tl_regr = _tranpose_and_gather_feat(tl_regr, tl_inds)
tl_regr = tl_regr.view(batch, K, 1, 2)
br_regr = _tranpose_and_gather_feat(br_regr, br_inds)
br_regr = br_regr.view(batch, 1, K, 2)
#更新坐标,将热图求的坐标跟offset做求和操作。
tl_xs = tl_xs + tl_regr[..., 0]
tl_ys = tl_ys + tl_regr[..., 1]
br_xs = br_xs + br_regr[..., 0]
br_ys = br_ys + br_regr[..., 1]
# all possible boxes based on top k corners (ignoring class)
## 这里首先不考类别,暴利的求出左上角点和右下角点的所有的组合框,即每个左上角点都与右下角点组合
bboxes = torch.stack((tl_xs, tl_ys, br_xs, br_ys), dim=3)
### 拿出所有的左上角点和右下角点的embedding的值,用于后面验证距离,只有距离相近,才能被判断为是同一个类别
tl_tag = _tranpose_and_gather_feat(tl_tag, tl_inds)
tl_tag = tl_tag.view(batch, K, 1)
br_tag = _tranpose_and_gather_feat(br_tag, br_inds)
br_tag = br_tag.view(batch, 1, K)
### 计算左上角点以及右下角点的距离的绝对值。
dists = torch.abs(tl_tag - br_tag)
#### 拿出所有的左上角和右下角的 类别得分
tl_scores = tl_scores.view(batch, K, 1).expand(batch, K, K)
br_scores = br_scores.view(batch, 1, K).expand(batch, K, K)
##### 将所有的得分求平均
scores = (tl_scores + br_scores) / 2
# 由于前面是枚举了所有可能的组合情况,所以肯定会有很多错误的匹配情况,这里开始,根据一系列条件,干掉错误的匹配情况。
# reject boxes based on classes 将左上角和右下角类别不同的干掉
tl_clses = tl_clses.view(batch, K, 1).expand(batch, K, K)
br_clses = br_clses.view(batch, 1, K).expand(batch, K, K)
cls_inds = (tl_clses != br_clses)
# reject boxes based on distances 将距离大于阈值的干掉,这里是0.5
dist_inds = (dists > ae_threshold)
# reject boxes based on widths and heights 左上角不在右下角上方的干掉
width_inds = (br_xs < tl_xs)
height_inds = (br_ys < tl_ys)
##将上面提到的全部干掉
scores[cls_inds] = -1
scores[dist_inds] = -1
scores[width_inds] = -1
scores[height_inds] = -1
scores = scores.view(batch, -1)
### 拿到过滤后的topk的得分,以及topk的index
scores, inds = torch.topk(scores, num_dets)
scores = scores.unsqueeze(2)
##下面分别利用index过滤,拿到topkscore对应的坐标以及类别等
bboxes = bboxes.view(batch, -1, 4)
bboxes = _gather_feat(bboxes, inds)
clses = tl_clses.contiguous().view(batch, -1, 1)
clses = _gather_feat(clses, inds).float()
tl_scores = tl_scores.contiguous().view(batch, -1, 1)
tl_scores = _gather_feat(tl_scores, inds).float()
br_scores = br_scores.contiguous().view(batch, -1, 1)
br_scores = _gather_feat(br_scores, inds).float()
##拼接到一起后返回
detections = torch.cat([bboxes, scores, tl_scores, br_scores, clses], dim=2)
return detections
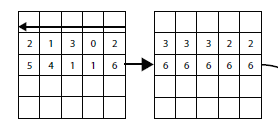
Corner Pooling是用C++来完成的,这里,这里主要简单介绍一下left pooling的做法,其他的同理,其实实现的就是下面这个过程
std::vector pool_forward(
at::Tensor input
) {
// Initialize output output的形状跟input是一致的,所以先根据input构建出output
at::Tensor output = at::zeros_like(input);
// Get width 拿到长度
int64_t width = input.size(3);
// Copy the last column,left pooling是一行,从右往左进行的,所以最后一个的input的值和output的值是一致的,下面三行代码就是实现复制的代码。
at::Tensor input_temp = input.select(3, width - 1);
at::Tensor output_temp = output.select(3, width - 1);
output_temp.copy_(input_temp);
// 接下来就是从倒数第二个开始,逐个比较,永远把最大的放到output当前的位置上。
at::Tensor max_temp;
for (int64_t ind = 1; ind < width; ++ind) {
input_temp = input.select(3, width - ind - 1);
output_temp = output.select(3, width - ind);
max_temp = output.select(3, width - ind - 1);
at::max_out(max_temp, input_temp, output_temp);
}
return {
output
};
}