【十八掌●武功篇】第十掌:Hive之原理与优化
这一篇博文是【大数据技术●降龙十八掌】系列文章的其中一篇,点击查看目录:![]() 大数据技术●降龙十八掌
大数据技术●降龙十八掌
- 小系列列表
-
【十八掌●武功篇】第十掌:Hive之基本语法
【十八掌●武功篇】第十掌:Hive之原理与优化
【十八掌●武功篇】第十掌:Hive之高级知识
【十八掌●武功篇】第十掌:Hive之安装过程实践
一、Hive架构
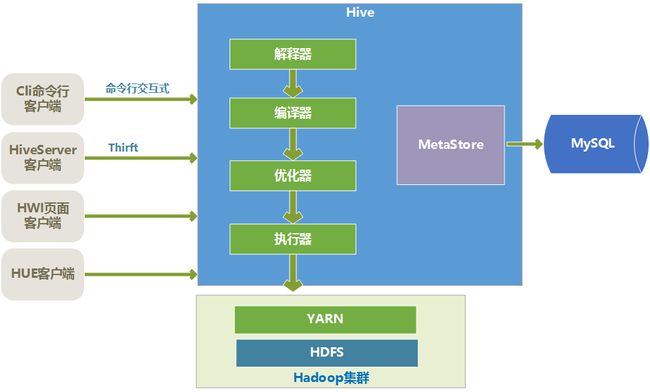
Hive的核心
Hive的核心是驱动引擎,驱动引擎由四部分组成:
解释器:解释器的作用是将HiveSQL语句转换为语法树(AST)。
编译器:编译器是将语法树编译为逻辑执行计划。
优化器:优化器是对逻辑执行计划进行优化。
执行器:执行器是调用底层的运行框架执行逻辑执行计划。
Hive的底层存储
Hive的数据是存储在HDFS上的。Hive中的库和表可以看作是对HDFS上数据做的一个映射。所以Hive必须是运行在一个Hadoop集群上的。
Hive语句的执行过程
Hive中的执行器,是将最终要执行的MapReduce程序放到YARN上以一系列Job的方式去执行。
Hive的元数据存储
Hive的元数据是一般是存储在MySQL这种关系型数据库上的,Hive和MySQL之间通过MetaStore服务交互。
| 元数据项 | 说明 |
|---|---|
| Owner | 库、表的所属者 |
| LastAccessTime | 最后修改时间 |
| Table Type | 表类型(内部表、外部表) |
| CreateTime | 创建时间 |
| Location | 存储位置 |
| 表的字段信息 | |
Hive客户端
Hive有很多种客户端。
cli命令行客户端:采用交互窗口,用hive命令行和Hive进行通信。
HiveServer2客户端:用Thrift协议进行通信,Thrift是不同语言之间的转换器,是连接不同语言程序间的协议,通过JDBC或者ODBC去访问Hive。
HWI客户端:hive自带的一个客户端,但是比较粗糙,一般不用。
HUE客户端:通过Web页面来和Hive进行交互,使用的比较多。
二、MapReduce执行过程
Hive语句最终是要转换为MapReduce程序放到Hadoop上去执行的,如果想深入了解Hive,并能够很好地优化Hive语句,了解MapReduce的执行过程至关重要,因为只有知道了MapReduce程序是怎么执行的,才能了解Hive语句是怎么执行的,才能有针对性地优化。
执行过程简介
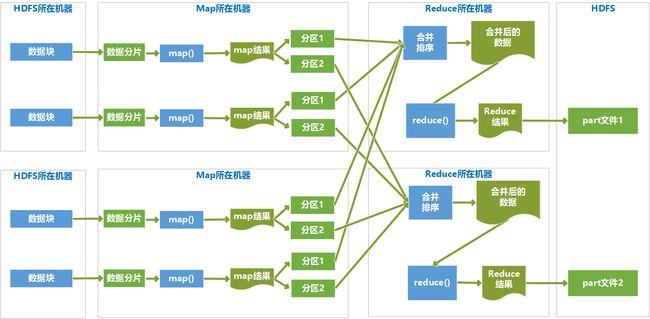
MapReduce过程大体分为两个阶段:map函数阶段和reduce函数阶段,两个阶段之间有有个shuffle。
Hadoop将MapReduce输入的数据划分为等长的小分片,一般每个分片是128M,因为HDFS的每个块是128M。Hadoop1.X中这个数是64M。
map函数是数据准备阶段,读取分片内容,并筛选掉不需要的数据,将数据解析为键值对的形式输出,map函数核心目的是形成对数据的索引,以供reduce函数方便对数据进行分析。
在map函数执行完后,进行map端的shuffle过程,map端的shuffle是将map函数的输出进行分区,不同分区的数据要传入不同的Reduce里去。
各个分区里的数据传入Reduce后,会先进行Reduce端的Shuffle过程,这里会将各个Map传递过来的相同分区的进行排序,然后进行分组,一个分组的数据执行一次reduce函数。
reduce函数以分组的数据为数据源,对数据进行相应的分析,输出结果为最终的目标数据。
由于map任务的输出结果传递给reduce任务过程中,是在节点间的传输,是占用带宽的,这样带宽就制约了程序执行过程的最大吞吐量,为了减少map和reduce间的数据传输,在map后面添加了combiner函数来就map结果进行预处理,combiner函数是运行在map所在节点的。
下面的示例图描述了整个MapReduce的执行过程:
工作机制
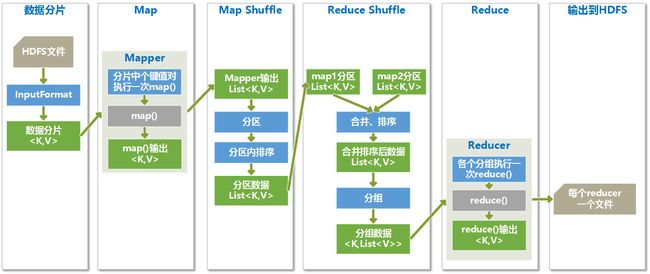
分片
HDFS上的文件要用很多mapper进程处理,而map函数接收的输入是键值对的形式,所以要先将文件进行切分并组织成键值对的形式,这个切分和转换的过程就是数据分片。
在编写MapReduce程序时,可以通过job.setInputFormatClass()方法设置分片规则,如果没有指定默认是用TextInputFormat类。分片规则类都必须继承于FileInputFormat。
Map过程
每个数据分片将启动一个Map进程来处理,分片里的每个键值对运行一次map函数,根据map函数里定义的业务逻辑处理后,得到指定类型的键值对。
Map Shuffle过程
Map过程后要进行Map端的Shuffle阶段,Map端的Shuffle数据处理过程如下图所示:
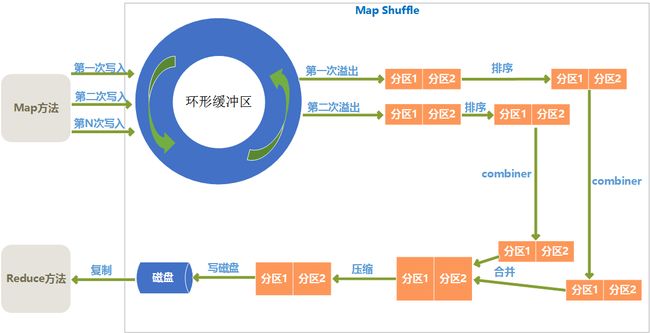
环形缓冲区
Map输出结果是先放入内存中的一个环形缓冲区,这个环形缓冲区默认大小为100M(这个大小可以在io.sort.mb属性中设置),当环形缓冲区里的数据量达到阀值时(这个值可以在io.sort.spill.percent属性中设置)就会溢出写入到磁盘,环形缓冲区是遵循先进先出原则,Map输出一直不停地写入,一个后台进程不时地读取后写入磁盘,如果写入速度快于读取速度导致环形缓冲区里满了时,map输出会被阻塞直到写磁盘过程结束。
分区
从环形缓冲区溢出到磁盘过程,是将数据写入mapred.local.dir属性指定目录下的特定子目录的过程。
但是在真正写入磁盘之前,要进行一系列的操作,首先就是对于每个键,根据规则计算出来将来要输出到哪个reduce,根据reduce不同分不同的区,分区是在内存里分的,分区的个数和将来的reduce个数是一致的。
排序
在每个分区上,会根据键进行排序。
Combiner
combiner方法是对于map输出的结果按照业务逻辑预先进行处理,目的是对数据进行合并,减少map输出的数据量。
排序后,如果指定了conmbiner方法,就运行combiner方法使得map的结果更紧凑,从而减少写入磁盘和将来网络传输的数据量。
合并溢出文件
环形缓冲区每次溢出,都会生成一个文件,所以在map任务全部完成之前,会进行合并成为一个溢出文件,每次溢出的各个文件都是按照分区进行排好序的,所以在合并文件过程中,也要进行分区和排序,最终形成一个已经分区和排好序的map输出文件。
在合并文件时,如果文件个数大于某个指定的数量(可以在min.num.spills.for.combine属性设置),就会进再次combiner操作,如果文件太少,效果和效率上,就不值得花时间再去执行combiner来减少数据量了。
压缩
Map输出结果在进行了一系列的分区、排序、combiner合并、合并溢出文件后,得到一个map最终的结果后,就应该真正存储这个结果了,在存储之前,可以对最终结果数据进行压缩,一是可以节约磁盘空间,而是可以减少传递给reduce时的网络传输数据量。
默认是不进行压缩的,可以在mapred.compress.map.output属性设置为true就启用了压缩,而压缩的算法有很多,可以在mapred.map.output.compression.codec属性中指定采用的压缩算法,具体压缩详情,可以看本文的后面部分的介绍。
Reduce Shuffle过程
Map端Shuffle完成后,将处理结果存入磁盘,然后通过网络传输到Reduce节点上,Reduce端首先对各个Map传递过来的数据进行Reduce 端的Shuffle操作,Reduce端的Shuffle过程如下所示:
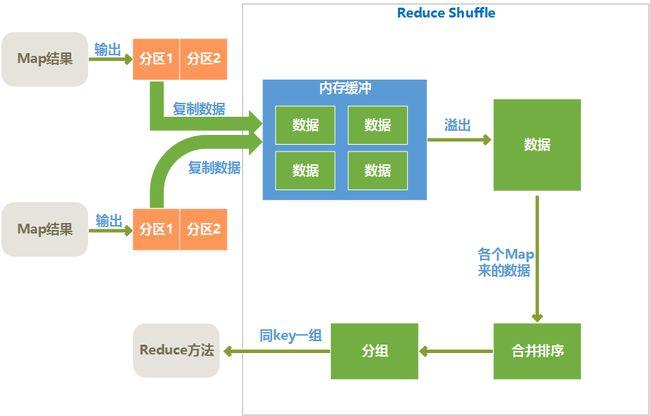
复制数据
各个map完成时间肯定是不同的,只要有一个map执行完成,reduce就开始去从已完成的map节点上复制输出文件中属于它的分区中的数据,reduce端是多线程并行来复制各个map节点的输出文件的,线程数可以在mapred.reduce.parallel.copies属性中设置。
reduce将复制来的数据放入内存缓冲区(缓冲区大小可以在mapred.job.shuffle.input.buffer.percent属性中设置)。当内存缓冲区中数据达到阀值大小或者达到map输出阀值,就会溢写到磁盘。
写入磁盘之前,会对各个map节点来的数据进行合并排序,合并时如果指定了combiner,则会再次执行combiner以尽量减少写入磁盘的数据量。为了合并,如果map输出是压缩过的,要在内存中先解压缩后合并。
合并排序
合并排序其实是和复制文件同时并行执行的,最终目的是将来自各个map节点的数据合并并排序后,形成一个文件。
分组
分组是将相同key的键值对分为一组,一组是一个列表,列表中每一组在一次reduce方法中处理。
执行Reduce方法
Reduce端的Shuffle完成后,就交由reduce方法来进行处理了。
Reduce过程
Reduce端的Shuffle过程后,最终形成了分好组的键值对列表,相同键的数据分为一组,分组的键是分组的键,值是原来值得列表,然后每一个分组执行一次reduce函数,根据reduce函数里的业务逻辑处理后,生成指定格式的键值对。
三、性能优化
Hadoop启动开销大,如果每次只做小数量的输入输出,利用率将会很低。所以用好Hadoop的首要任务是增大每次任务所搭载的数据量。Hadoop的核心能力是parition和sort,因而这也是优化的根本。
Hive优化时,把hive Sql当做mapreduce程序来读,而不是当做SQL来读。
1、HiveQL层面优化
利用分区表优化
分区表是在某一个或者某几个维度上对数据进行分类存储,一个分区对应于一个目录。在这中的存储方式,当查询时,如果筛选条件里有分区字段,那么Hive只需要遍历对应分区目录下的文件即可,不用全局遍历数据,使得处理的数据量大大减少,提高查询效率。
当一个Hive表的查询大多数情况下,会根据某一个字段进行筛选时,那么非常适合创建为分区表。
利用桶表优化
桶表的概念在前面有详细介绍,就是指定桶的个数后,存储数据时,根据某一个字段进行哈希后,确定存储在哪个桶里,这样做的目的和分区表类似,也是使得筛选时不用全局遍历所有的数据,只需要遍历所在桶就可以了。
hive.optimize.bucketmapJOIN 为true
sort-merge JOIN
hive.input.format=org.apache.hadoop.hive.ql.io.bucketizedHiveInputFormat;
hive.optimize.bucketmapjoin=true;
hive.optimize.bucketmapjoin.sortedmerge=true;
join优化
优先过滤后再join,最大限度地减少参与Join的数据量。
小表join大表原则。
应该遵守小表join大表原则,原因是Join操作在reduce阶段,位于join左边的表内容会被加载进内存,将条目少的表放在左边,可以有效减少发生内存溢出的几率。join中执行顺序是从左到右生成Job,应该保证连续查询中的表的大小从左到右是依次增加的。join on 条件相同的放入一个job.
hive中,当多个表进行join时,如果join on的条件相同,那么他们会合并为一个MapReduce Job,所以利用这个特性,可以将相同的join on的放入一个job来节省执行时间。
select pt.page_id,count(t.url) PV
from rpt_page_type pt
join
(
select url_page_id,url from trackinfo where ds='2016-10-11'
) t on pt.page_id=t.url_page_id
join
(
select page_id from rpt_page_kpi_new where ds='2016-10-11'
) r on t.url_page_id=r.page_id
group by pt.page_id;启用mapjoin
mapjoin是将join双方比较小的表直接分发到各个map进程的内存中,在map进程中进行join操作,这样就省掉了reduce步骤,提高了速度。
mapjoin相关参数如下:
<property>
<name>hive.auto.convert.joinname>
<value>truevalue>
property>
<property>
<name>hive.auto.convert.joinname>
<value>truevalue>
property>
<property>
<name>hive.auto.convert.join.noconditionaltask.sizename>
<value>10000000value>
property>
<property>
<name>hive.auto.convert.join.use.nonstagedname>
<value>falsevalue>
property>hive.auto.convert.join
为true时,join方数据量小的表会整体分发到各个map进程的内存中,在map进程本地进行join操作,这样能大大提高运算效率,牺牲的是内存容量,所以数据量小于某一个值的才允许用mapjoin分发到各个map节点里,而这个值用以下参数来配置。
hive.auto.convert.join.noconditionaltask
设置为true,hive才基于输入文件大小进行自动转换为mapjoin.
hive.auto.convert.join.noconditionaltask.size
指定小于多少的表数据放入map内存,使用mapjoin,默认是10M.
这个优化只对join有效,对left join、right join 无效。
桶表mapjoin
当两个分桶表join时,如果join on的是分桶字段,小表的分桶数时大表的倍数时,可以启用map join来提高效率。启用桶表mapjoin要启用hive.optimize.bucketmapjoin参数。
<property>
<name>hive.optimize.bucketmapjoinname>
<value>truevalue>
<description>Whether to try bucket mapjoindescription>
property>Group By数据倾斜优化
Group By很容易导致数据倾斜问题,因为实际业务中,通常是数据集中在某些点上,这也符合常见的2/8原则,这样会造成对数据分组后,某一些分组上数据量非常大,而其他的分组上数据量很小,而在mapreduce程序中,同一个分组的数据会分配到同一个reduce操作上去,导致某一些reduce压力很大,其他的reduce压力很小,这就是数据倾斜,整个job执行时间取决于那个执行最慢的那个reduce。
解决这个问题的方法是配置一个参数:set hive.groupby.skewindata=true。
当选项设定为 true,生成的查询计划会有两个 MR Job。第一个 MR Job 中, Map的输出结果会随机分布到 Reduce 中,每个 Reduce做部分聚合操作,并输出结果,这样处理的结果是相同的 Group By Key 有可能被分发到不同的 Reduce 中,从而达到负载均衡的目的,在第一个Job中通过聚合操作减少了数据量;第二个 MR Job 再根据预处理的数据结果按照 Group By Key 分布到 Reduce 中(这个过程可以保证相同的 GroupBy Key 被分布到同一个 Reduce 中),最后完成最终的聚合操作。
Order By 优化
因为order by只能是在一个reduce进程中进行的,所以如果对一个大数据集进行order by,会导致一个reduce进程中处理的数据相当大,造成查询执行超级缓慢。在要有进行order by 全局排序的需求时,用以下几个措施优化:
在最终结果上进行order by,不要在中间的大数据集上进行排序。如果最终结果较少,可以在一个reduce上进行排序时,那么就在最后的结果集上进行order by。
如果需求是取排序后前N条数据,那么可以使用distribute by和sort by在各个reduce上进行排序后取前N条,然后再对各个reduce的结果集合并后在一个reduce中全局排序,再取前N条,因为参与全局排序的Order By的数据量最多有reduce个数*N,所以速度很快。
例子:
select a.leads_id,a.user_name from
(
select leads_id,user_name from user_leads
distribute by length(user_name) sort by length(user_name) desc limit 10
) a order by length(a.user_name) desc limit 10;Group By Map端聚合
并不是所有的聚合操作都需要在 Reduce 端完成,很多聚合操作都可以先在 Map端进行部分聚合,最后在 Reduce 端得出最终结果。
hive.map.aggr = true 是否在 Map 端进行聚合,默认为 True。
hive.groupby.mapaggr.checkinterval = 100000 在 Map 端进行聚合操作的条目数目
一次读取多次插入
有些场景是从一个表读取数据后,要多次利用,这时候就可以使用multi insert语法:
from user_action_log
insert overwrite table log1 select companyid,originalstring where companyid='100006'
insert overwrite table log2 select companyid,originalstring where companyid='10002'每次hive查询,都会将数据集整个遍历一遍。当查询结果会插入多个表中时,可以采用以上语法,将一次遍历写入多个表,以达到提高效率的目的。
Join字段显示类型转换
当参与join的字段类型不一致时,Hive会自动进行类型转换,但是自动转换有时候效率并不高,可以根据实际情况通过显示类型转换来避免HIVE的自动转换。
使用orc、parquet等列式存储格式
创建表时,尽量使用orc、parquet这些列式存储格式,因为列式存储的表,每一列的数据在物理上是存储在一起的,Hive查询时会只遍历需要列数据,大大减少处理的数据量。
2、Hive架构层面优化
不执行MapReduce
hive中有个参数:hive.fetch.task.conversion,定义如下:
<property>
<name>hive.fetch.task.conversionname>
<value>minimalvalue>
<description>
Some select queries can be converted to single FETCH task minimizing latency.
Currently the query should be single sourced not having any subquery and should not have
any aggregations or distincts (which incurs RS), lateral views and joins.
1. minimal : SELECT STAR, FILTER on partition columns, LIMIT only
2. more : SELECT, FILTER, LIMIT only (TABLESAMPLE, virtual columns)
description>
property>Hive从HDFS读取数据,有两种方式:启用MapReduce读取、直接抓取。
很显然直接抓取数据比MapReduce读取数据要快的多,但是只有少数操作可以直接抓取数据,hive.fetch.task.conversion参数就是设置什么情况下采用直接抓取方法,它的值有两个:
minimal:只有 select * 、在分区字段上where过滤、有limit这三种场景下才启用直接抓取方式。
more:在select、where筛选、limit时,都启用直接抓取方式。
启用fetch more模式: set hive.fetch.task.conversion=more;
实例:
set hive.fetch.task.conversion=more;
select userid,username from user_info where cityid is not null;这个例子中,如果set hive.fetch.task.conversion=minimal,那么下面的查询语句会以MapReduce方法执行,运行时间比较长,但是改为more后,发现查询速度非常快。
本地模式执行MapReduce
Hive在集群上查询时,默认是在集群上N台机器上运行,需要多个机器进行协调运行,这个方式很好地解决了大数据量的查询问题。但是当Hive查询处理的数据量比较小时,其实没有必要启动分布式模式去执行,因为以分布式方式执行就涉及到跨网络传输、多节点协调等,并且消耗资源。这个时间可以只使用本地模式来执行mapreduce job,只在一台机器上执行,速度会很快。
启动本地模式涉及到三个参数:
| 参数名 | 默认值 | 备注 |
|---|---|---|
| hive.exec.mode.local.auto | false | 让hive决定是否在本地模式自动运行 |
| hive.exec.mode.local.auto.input.files.max | 4 | 不启用本地模式的task最大个数 |
| hive.exec.mode.local.auto.inputbytes.max | 128M | 不启动本地模式的最大输入文件大小 |
各个参数定义如下:
<property>
<name>hive.exec.mode.local.autoname>
<value>falsevalue>
<description> Let Hive determine whether to run in local mode automatically description>
property>
<property>
<name>hive.exec.mode.local.auto.input.files.maxname>
<value>4value>
<description>When hive.exec.mode.local.auto is true, the number of tasks should less than this for local mode.description>
property>
<property>
<name>hive.exec.mode.local.auto.inputbytes.maxname>
<value>134217728value>
<description>When hive.exec.mode.local.auto is true, input bytes should less than this for local mode.description>
property>
set hive.exec.mode.local.auto=true是打开hive自动判断是否启动本地模式的开关,但是只是打开这个参数并不能保证启动本地模式,要当map任务数不超过hive.exec.mode.local.auto.input.files.max的个数并且map输入文件大小不超过hive.exec.mode.local.auto.inputbytes.max所指定的大小时,才能启动本地模式。
JVM重用
因为Hive语句最终要转换为一系列的MapReduce Job的,而每一个MapReduce Job是由一系列的Map Task和Reduce Task组成的,默认情况下,MapReduce中一个Map Task或者一个Reduce Task就会启动一个JVM进程,一个Task执行完毕后,JVM进程就退出。这样如果任务花费时间很短,又要多次启动JVM的情况下,JVM的启动时间会变成一个比较大的消耗,这个时候,就可以通过重用JVM来解决。
set mapred.job.reuse.jvm.num.tasks=5
这个设置就是制定一个jvm进程在运行多次任务之后再退出,这样一来,节约了很多的JVM的启动时间。
并行化
一个hive sql语句可能会转为多个mapreduce Job,每一个job就是一个stage,这些job顺序执行,这个在hue的运行日志中也可以看到。但是有时候这些任务之间并不是是相互依赖的,如果集群资源允许的话,可以让多个并不相互依赖stage并发执行,这样就节约了时间,提高了执行速度,但是如果集群资源匮乏时,启用并行化反倒是会导致各个job相互抢占资源而导致整体执行性能的下降。
启用并行化:
set hive.exec.parallel=true;
这一篇博文是【大数据技术●降龙十八掌】系列文章的其中一篇,点击查看目录:![]() 大数据技术●降龙十八掌
大数据技术●降龙十八掌