【十八掌●武功篇】第十六掌:Spark之Scala语法快速概览
这一篇博文是【大数据技术●降龙十八掌】系列文章的其中一篇,点击查看目录:![]() 大数据技术●降龙十八掌
大数据技术●降龙十八掌
- 系列文章:
-
【十八掌●武功篇】第十六掌:Spark之Scala安装和HelloWorld
【十八掌●武功篇】第十六掌:Spark之Scala语法快速概览
【十八掌●武功篇】第十六掌:Spark之简介、安装、Demo
【十八掌●武功篇】第十六掌:Spark之RDD简介
1、 函数
(1) 一个最典型的函数实例
def max(x: Int, y: Int): Int = {
if (x > y)
x
else
y
}
- def关键字是定义一个max
- max是函数名称
- x是第一个参数名,:Int是指定参数x的类型为Int,y是第二个参数名称
- 小括号后面的:Int是表示函数返回值为Int
- =后面是函数体,=符号可以理解为将后面的函数体赋值给前面的函数定义。当函数显示地指定了返回值时,这个=是不可以省略的,如果没有显示定义返回值可以省略这个=。
- Scala和JavaScripte里类似,一行的结束可以不用分号;
- Scala的函数可以没有return,运行时,执行的最后一条语句的返回值就是函数的返回值。
在Scala命令行中运行函数定义和调用:
scala> def max(x:Int,y:Int):Int={ //定义函数
| if(x>y)
| x
| else
| y
| }
max: (x: Int, y: Int)Int
scala> max(2,3) //调用函数
res0: Int = 3
(2) 无参数,无返回值的函数
def add1() = {
println("add1....")
}
//无参数的函数可以省略 =
def add2() {
println("add2....")
}
//无返回值的函数,返回值其实是Unit类型的,
// Unit可以省略,就像第一个add1一样
def add3(): Unit = {
println("add3....")
}
调用时,如果函数没有参数,可以省略()
scala> def add3(): Unit = {
| println("add3....")
| }
add3: ()Unit
scala> add3 //可以省略()
add3....
(3) 函数体就一行代码时
//当函数体只有一行代码时,可以将花括号{}省略
//所以当无参数、无返回值、一行代码的函数,可以写为这样
def add4() = println("add3....")
(4) 匿名函数
//一个函数
def add5(x: Int, y: Int) = x + y
//改为匿名函数
(x: Int, y: Int) => x + y
匿名函数的函数体前面要用 => 符号。
(5) 将函数赋值为常量
//将匿名函数赋值给常量
val add6=(x: Int, y: Int) => x + y
//一个无参数函数
def add8() = println("add8")
//一个有参数函数
def add9(x: Int, y: Int) = x + y
//将无参数函数赋值给常量
val add10 = add8;
//将有参数函数赋值为常量,必须加 _
val add11 = add9 _;
(6) 在函数中调用函数
如果想将上面的add6传递给另外一个函数add7,add7应该定义如下:
//将函数赋值给函数
def add7(f: (Int, Int) => Int): Int = {
f(3, 8)
}
上面的(Int,Int)=>Int是定义了一个类型,类型是个匿名函数,参数f的类型就是个函数,这个函数的输入参数是两个Int类型的值,返回值也是个Int类型的值,另外add7函数的返回值也是个Int类型。
函数体中f(3,8)是说,函数体是去执行输入的那个匿名函数。
(7) 默认参数值
//name参数可以不传递,不传递时使用默认值:xiaoming
def sayName(name: String = "xiaoming") {
println("Hello!" + name)
}
定义函数时可以给参数指定一个默认值,当不传递这个函数时函数体就使用指定的默认值。一般惯例是将有默认值的参数参数列表的最后面。
(8) 变长函数
def printCourse2(course: String*): Unit = {
course.foreach(x => println(x))
}
def printCourse(course: String*): Unit = {
var txt = "";
course.foreach(x => (txt += (x + ",")))
println("input:" + txt)
}
在Scala中,定义函数时,最后一个参数可以变长,变长的意思是:参数的个数不确定,可以有很多个,类型后面添加一个*字符表示这个参数是可以变长的,调用时如下:
printCourse2(“a”,”b”,”c”)
2、 循环
(1) 循环表达式
- 1 to 10:循环1到10,包括1和10,包头包尾。
- 1.to(10) 同1 to 10
- 1 until 10 : 循环1到10,不包含10,包头不包尾。
- 1.until(10) 同 1 until 10
- Range(1,10) 同 1 to 10
- Range(1,10,2) 是从1到10,步长为2,就是循环1、3、5、7、9
(2) for 循环
def main(args: Array[String]) {
var sum = 0;
for (i <- 1 to 10) {
sum += i
}
println(sum)
}
参与循环的变量i与i取值范围之间用<-表示。
1 to 10明确表明了取值范围是1到10,包括1和10。
sum = 0
for (i <- 1 until 10)
sum += i
println(sum)
until是不包括10的,取值是1到9
for (c <- "Hello")
println(c)
遍历字符串并不需要下标。
(3) for循环嵌套
for (i <- 1 to 3; j <- 1 to 3)
println(i.toString + j.toString)(4) for循环中判断
for (i <- 1 to 3; j <- 1 to 3 ; if i>j)
println(i.toString + j.toString)(5) break、coutinue
Scala中没有break和coutinue关键字,如果想实现类似功能,可以使用scala.util.control.Breake来是实现。
object BreakDemo {
def main(args: Array[String]) {
//定义一个集合
val numList = List(1, 2, 3, 4, 5, 6, 7, 8)
//实例化一个Breaks对象,
val loop = new Breaks
loop.breakable(
//将循环放入loop.breakable中
for (num <- numList) {
println(num)
if(4==num)
{
//使用loop.break()方法来实现跳出
loop.break()
}
}
)
}
}
3、 数组
(1) 定长数组
- 定长数组定义:val list=Array(1,2,3,4,5) 或者 val list2=new ArrayInt
- 赋值:list(0)=11。下标用小括号来指定,而不像Java中一样用方括号。
(2) 变长数据
- 变长数组定义:val listBuffle=scala.collection.mutable.ArrayBufferInt
- 添加一个元素:listBuffle+=2 添加一个元素2。
- 添加多个元素:listBuffle++=Array(5,6,7) 添加了三个元素到变长数组里。
listBuffle+=(8,9,10) 添加了一个元组。 - 插入元素:listBuffle.insert(0,0)在0的位置插入一个值0。
- 删除元素:listBuffle.remove(4) 删除4位置的元素。
(3) 变长数据转为定长数组
scala> listBuffle.toArray
res17: Array[Int] = Array(0, 1, 2, 3, 5, 6, 7, 8, 9, 10)(4) 遍历数组
for(i<-listBuffle) println(i)(5) 数组变长字符串
listBuffle.mkString(“|”) 将数组变为字符串,用 | 字符隔开
listBuffle.mkString(“[“,”|”,”]”) 将数组变为字符串,用|隔开,前面添加[,后面添加]。
4、 元组
元组是可以存储不同类型元素的集合。
有两个元素的元组叫二元组。
(1) 定一个元组
scala> val tuple=(1,2,4,"a")
tuple: (Int, Int, Int, String) = (1,2,4,a)元组在Spark中很常见,比如key、value对可能就是个元组,{1001:”beijing”}
(2) 获取元素
可以用tuple._1获取第一个元素,注意元素的下标从1开始。
(3) 遍历元组
for(i<- 1 to tuple.productArity-1 ) println(tuple.productElement(i))- tuple.productArity是获取元组的长度
- tuple.productElement是获取元组的某一个下标的元素,请注意这里的下标是从0开始。
5、 集合
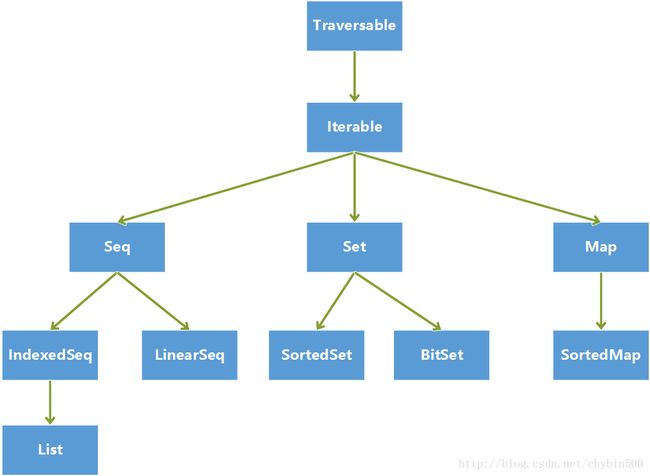
(1) Scala集合介绍
- Scala有一个非常丰富、强大可组合的集合库,集合都在scala.collection包中。
- Scala集合中有定长集合和变长集合,定长集合在scala.collection. immutable中,变长集合在scala.collection. mutable中
(2) Scala集合结构
(3) List集合
● 定义一个List:val list=List(1,2,3,4,5)
● List由head和tail组成:
scala> list.head
res34: Int = 1
scala> list.tail
res35: List[Int] = List(2, 3, 4, 5)
head是集合中第一个元素,tail是除了head外的其他元素组成的集合,也就是tail是个List集合,tail也有head和tail,如下:
scala> list.tail.tail.tail
res36: List[Int] = List(4, 5)
● 空集合用Nil表示,同List()
● 另外一种定义集合方式,是用head和tail方式定义,如下:
//head为1,tail为空集合
scala> var list2=1::Nil
list2: List[Int] = List(1)
//head为2,tail为一个集合
scala> var list3=2::list2
list3: List[Int] = List(2, 1)
//另一种定义方式
scala> var list4=1::2::3::list3
list4: List[Int] = List(1, 2, 3, 2, 1)
//上面方式可以理解为这种方式
scala> var list5=(1::(2::(3::list3)))
list5: List[Int] = List(1, 2, 3, 2, 1)
● List转换为数组
scala> list.toArray
res3: Array[Int] = Array(1, 2, 3, 5)
● List中添加、减少元素
List是定长集合,所以不能添加元素,但是变长List可以添加元素。
//定义一个变长集合
scala> val list2=scala.collection.mutable.ListBuffer[Int]()
list2: scala.collection.mutable.ListBuffer[Int] = ListBuffer()
//添加元素
scala> list2+=2
res4: list2.type = ListBuffer(2)
//添加一个元组
scala> list2+=(3,4)
res5: list2.type = ListBuffer(2, 3, 4)
//添加一个集合
scala> list2++=List(5,6)
res6: list2.type = ListBuffer(2, 3, 4, 5, 6)
//减少一个元素
scala> list2-=3
res7: list2.type = ListBuffer(2, 4, 5, 6)
//减少一个集合
scala> list2--=List(5,4)
res8: list2.type = ListBuffer(2, 6)
(4) Set
● Set中的元素是无序不重复的集合。
● 定义一个Set集合:scala> var set=Set(1,2,3,4,5)
● 定义要给可变长Set集合:val set1=scala.collection.mutable.SetInt
● 对变长Set集合,+ 、+=、++=是不同的
set1+1是创建另外一个可变Set集合,内容为添加了一个1。
set1+=1 是在原来的Set集合中添加一个元素1
(5) Map集合
● Map是键值对的集合
● 定义一个定长Map: scala> val map=Map(“zhangsan”->20,”lisi”-> 25)
● 获取值
scala> map(“zhangsan”) 是根据key获取值。
scala> map.getOrElse(“zhangsan”,0) 根据Key获取值,如果是空则返回0。
● 赋值
同Set一样,只有可变的Map集合才能赋值。
--定义一个可变的Map
scala> val b=scala.collection.mutable.Map("zs"->20,"lisi"->30)
b: scala.collection.mutable.Map[String,Int] = Map(lisi -> 30, zs -> 20)
--第一种赋值方式,添加一个wangwu
scala> b("wangwu")=35
--显示当前b的内容
scala> b
res1: scala.collection.mutable.Map[String,Int] = Map(lisi -> 30, zs -> 20, wangwu -> 35)
--第二种,添加内容方式,用+=
scala> b+=("wangma"->35,"hanliu"->40)
--删除内容,用-=
scala> b-="zs"
● 遍历Map
//第一种遍历方法
scala> for((key,value)<-b)
| println("key="+key+",value="+value)
key=lisi,value=30
key=wangma,value=35
key=hanliu,value=40
key=wangwu,value=35
//第二种遍历方式
scala> for(ele <- b.keySet)
| println("key="+ele+",value="+b.getOrElse(ele,0))
key=lisi,value=30
key=wangma,value=35
key=hanliu,value=40
key=wangwu,value=35
//只遍历值
scala> for(ele<-b.values)
| println("value="+ele)
value=30
value=35
value=40
value=35
//遍历的另外一种方式,value不一定有值时
scala> for((key,_)<-b)
| println("key="+key+",value="+b.getOrElse(key,0))
key=lisi,value=30
key=wangma,value=35
key=hanliu,value=40
key=wangwu,value=35
6、 模式匹配
Java中只能对数值进行模式匹配,但是在Scala中,除了可以对值进行模式匹配外,还可以对类型进行模式匹配,对Array和List的元素进行匹配、对case class进行匹配、甚至对有值或者没有值进行匹配。
(1) 模式匹配值
package scala.com.chybinmy.scala.spark
object MatchDemo {
def main(args: Array[String]) {
judge("A")
judge("E")
}
def judge(tag: String): Unit = {
tag match {
case "A" => println("Excellent")
case "B" => println("Good")
case "C" => println("Just so so")
case _ => println("You need word hard")
}
}
}
def judge(tag: String,name:String): Unit = {
tag match {
case "A" => println("Excellent")
case "B" => println("Good")
case "C" => println("Just so so")
case _ if name.equals("xiaoming")=>println(name+",come on!")
case _ => println("You need word hard")
}
}
(2) 匹配类型
package scala.com.chybinmy.scala.spark
object ExceptionTest extends App {
try {
val i = 1 / 0
}
catch {
case e: ArithmeticException => throw new RuntimeException("not zero!")
case e: Exception => println(e.getMessage)
}
finally {
println("finally")
}
}
当匹配类型时,case 后面的e为变量名,冒号后面的是要匹配的类型名称。
(3) 匹配classs
package scala.com.chybinmy.scala.spark
class Person
case class Teacher(name: String, subject: String) extends Person
case class Student(name: String, classroom: String) extends Person
object CaseMathTest {
def judge(person: Person): Unit = {
person match {
case Teacher(name, subject) => println("Teacher:" + name + "," + subject)
case Student(name, classroom) => println("Student:" + name + "," + classroom)
case _ => println("error!")
}
}
def main(args: Array[String]) {
judge(new Teacher("xuanyu","spark"))
judge(new Student("ming","7 ban"))
judge(null)
judge(new Person)
}
}
(4) 匹配Option
Scala中的Option是一种特殊的类型,Option有两种值:Some表示有值,None表示没有值。模式匹配Option用于判断某个变量有值还是没有值。
package scala.com.chybinmy.scala.spark
object OptionMathDemo {
def getGrade(name: String): Unit = {
val grades = Map("xx" -> "A", "yy" -> "B", "zz" -> "C")
val g = grades.get(name)
g match {
case Some(course) => println(name + ",your grade is " + course)
case None => println(name + ",no your grade")
}
}
def main(args: Array[String]) {
getGrade("xx")
getGrade("aa")
}
}
7、 异常处理
package scala.com.chybinmy.scala.spark
object ExceptionTest extends App {
try {
val i = 1 / 0
}
catch {
case e: ArithmeticException => throw new RuntimeException("not zero!")
case e: Exception => println(e.getMessage)
}
finally {
println("finally")
}
}
8、 高阶函数
输入参数的类型为函数的函数为高阶函数(higher-order function)。
package scala.com.chybinmy.scala.spark
object HigherDemo {
//定义一个高阶函数
def greetin(f: (String) => Unit, name: String): Unit = {
f(name)
}
def main(args: Array[String]) {
//定义一个函数赋值为常量
val sayHelloFunc = (name: String) => println("Helllo!" + name)
//将函数类型的常量做为参数,传递给高阶函数
greetin(sayHelloFunc, "老王!")
//将一个匿名函数做为参数传递给高阶函数
greetin((name: String) => println(name + "好!"), "张sir")
//省略匿名函数参数的类型
greetin((name) => println(name + "hao"), "小明")
//如果只有一个参数,可以省略括号
greetin(name => println("早" + name), "小红")
//List.map是个高阶函数
var list = List(1, 2, 3, 4, 5)
println(list)
println(list.map((x: Int) => x + 1))
println(list.map(x => x + 1))
//只有一个参数,并函数体中只用到一个这个参数,可以用_表示
println(list.map(_ + 1))
}
}
将函数做为参数传递给另外一个函数,是一种封装。
9、 隐式转换
(1) 一个例子
package scala.com.chybinmy.scala.spark
//定义一个特殊人群类
class SpecialPerson(val name: String)
//定义一个学生
class Stu(val name: String)
//定义一个老人类
class Older(val name: String)
object ImplicitDemo {
def main(args: Array[String]) {
//将Stu类型隐式转换为SpecialPerson类型
val stu = new Stu("xiaoping")
val ticket = buySpecialTicker(stu)
println("Buy ticket:" + ticket)
//将Oler类型隐式转换为SpecialPerson类型
val older = new Older("laoli")
val ticket2 = buySpecialTicker(older)
println("Buy older ticket:" + ticket2)
}
//买票函数,这个函数定义输入参数是SpecialPerson类型的
var ticketNumber = 0
def buySpecialTicker(p: SpecialPerson): String = {
ticketNumber += 1
"T-" + ticketNumber
}
//定义一个隐式转换函数,定义了那些类型可以隐式转换为SpecialPerson
implicit def objectToSpecialPerson(obj: Object): SpecialPerson = {
if (obj.getClass == classOf[Stu]) {
val stu = obj.asInstanceOf[Stu]
new SpecialPerson(stu.name)
}
else if (obj.getClass == classOf[Older]) {
val older = obj.asInstanceOf[Older]
new SpecialPerson(older.name)
}
else
new SpecialPerson("未知名字")
}
}
这段程序是特殊人群买票的例子,objectToSpecialPerson定义了Stu类和Older类可以隐式转换为SpecialPerson类,所以虽然buySpecialTicker函数的输入参数为SpecialPerson类型,但是调用时,可以传递Stu和Older类型的值进去,因为自动做了隐式转换。
隐式转换允许手动指定将某种类型的对象转换为其他类型的对象,最核心的就是定义了隐式转换函数。
隐式转换的强大之处就在于可以在不知不觉中加强了现有类型的功能,也就是说可以为某一个类定义一个加强版的类,并定义相互转换,从而让源类可以调用加强版类里的方法。
(2) 作用域和导入
Scala默认会使用两种隐式转换:
● 一种是从源类型或者目标类型的伴生对象内,找隐式转换函数
● 一种是当前程序的作用域内找隐式转换函数。
如果其他两种方式都找不到,那就要手动导入了。如:
var sqlContext=new SQLContext(sc)
import sqlContext.implicit._
(3) 隐式转换的时机
当在如下情况下,会尝试进行隐式转换:
● 调用某个函数,但是给函数传入的参数的类型与函数定义的接收类型不匹配。
● 使用某个类型的对象,调用某个方法,而这个方法并不存在于该类型时
● 使用某个类型的对象,调用某个方法,虽然该类型有这个方法,但是给方法传入的参数类型与方法定义的参数类型不匹配时
10、 Option
Scala中有一种特殊的类型是Option,用来表示那种有肯能存在也肯能不存在的值,Option有两种值,一种是Some,表示有值,一种是None,表示没有值。
Option通常会用于模式匹配中,用于判断某个变量有值或者没有值,比Null更加简洁
11、 Trait
Scala中的Trait是一种特殊的概念,类似于Java中的接口,在Trait中可以用来定义抽象方法。类可以使用extends关键字继承trait,继承后必须实现其中的抽象方法,实现时不需要使用override关键字,虽然Scala不支持对类进行多继承,但是支持使用with来多重继承trait。
trait还可继承于trait。
这一篇博文是【大数据技术●降龙十八掌】系列文章的其中一篇,点击查看目录:![]() 大数据技术●降龙十八掌
大数据技术●降龙十八掌