爬取知乎一个问题下所有图片
代码如下:
import requests
import re
import http.cookiejar
session=requests.session()
questionurl='https://www.zhihu.com/question/25699277'
agent=r'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36'
headers0={'user-agent':agent,\
'Host':'www.zhihu.com'}
#requests.cookies=http.cookiejar.LWPCookieJar(filename='D:/pachongtest/cookies')
index_page = session.get(questionurl, headers=headers0)
cl=requests.utils.dict_from_cookiejar(session.cookies)
#print (cl)
if 'd_c0' in cl.keys():
dc0=cl['d_c0'].split('|')[0]
else:
session.cookies.clear()
index_page = session.get(questionurl, headers=headers0)
cl=requests.utils.dict_from_cookiejar(session.cookies)
dc0=cl['d_c0'].split('|')[0]
print (dc0)
#print (requests.cookies.extract_cookies_to_jar())
#try:
# requests.cookies.load(ignore_discard=True)
#except:
# pass
headers={'user-agent':agent,\
'Host':'www.zhihu.com',
'X-UDID':dc0,
'Host':'www.zhihu.com','Referer':'https://www.zhihu.com/question/25628825','authorization':'oauth c3cef7c66a1843f8b3a9e6a1e3160e20'}
#
for j in range(0,3):
url='https://www.zhihu.com/api/v4/questions/25699277/answers?sort_by=default&include=data%5B%2A%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cupvoted_followees%3Bdata%5B%2A%5D.mark_infos%5B%2A%5D.url%3Bdata%5B%2A%5D.author.follower_count%2Cbadge%5B%3F%28type%3Dbest_answerer%29%5D.topics&limit=20&offset={page}'.format(page=3+j*20)
page=requests.get(url,headers=headers)
#print (page.status_code)
allurlre=re.compile(r'data-actualsrc=\\"(.*?\.jpg)\\"',re.S)
allurl=re.findall(allurlre,page.text)
#print(page.text)
i=0
for urls in allurl:
gifpattern=re.compile('^(?!.*gif)')
m=re.match(gifpattern,urls)
if m:
print (str(i)+':'+urls)
file=requests.get(urls)
filename=r'D:\pachongtest\test'+str(j)+'_'+str(i)+'.jpg'
f=open(filename,'wb')
f.write(file.content)
f.close()
i=i+1分析:
使用f12分析下拉问题答案时发出的request,可以看到如下图:
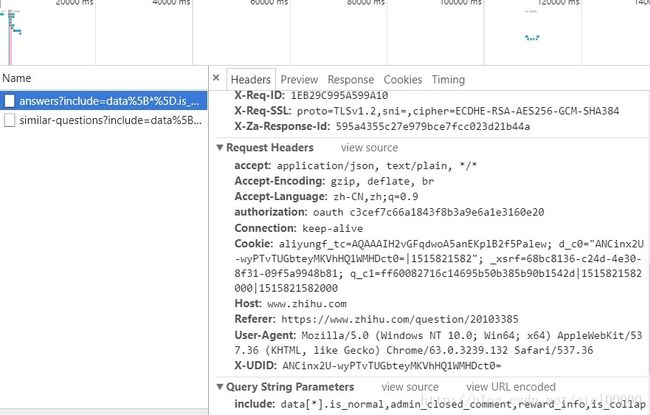
经多次观察,header中的authorization是不变的,可以照抄下来。X-UDID是第一次打开问题时得到的cookie,在d_c0中,如下图所示:
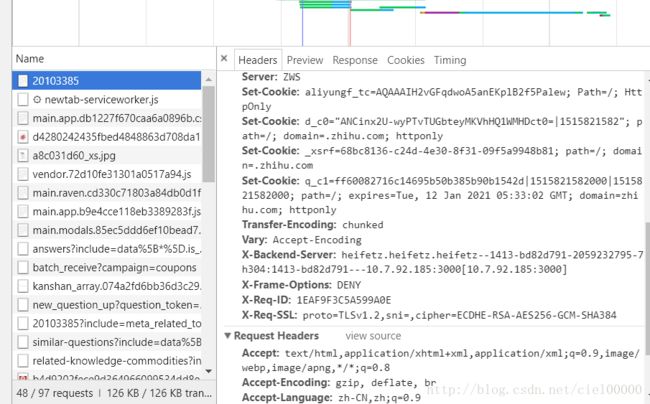
当然也可以把cookie保存在文件中。代码中采取的方法是每次获得新的cookie。然后就是正则匹配了,没有保存.gif图片,只保存了.jpg。因为电脑比较慢,只爬取了3页内容。