Pandas数据分析⑤——数据分组与函数使用(Groupby/Agg/Apply/mean/sum/count)
Pandas系列目录如下:
Pandas数据分析①——数据读取(CSV/TXT/JSON)
Pandas数据分析②——数据清洗(重复值/缺失值/异常值)
Pandas数据分析③——数据规整1(索引和列名调整/数据内容调整/排序)
Pandas数据分析④——数据规整2(数据拼接/透视)
Pandas数据分析⑥——数据分析实例(货品送达率与合格率/返修率/拒收率)
Pandas数据分析⑦——数据分析实例2(泰坦尼克号生存率分析)
之前有篇SQL聚合函数的文章
(https://blog.csdn.net/cindy407/article/details/90341410),讲述了SQL中分组函数groupby及相应的聚合函数使用。在Pandas数据分析中,Groupby也是使用频率非常高的方法,两者其实非常相似,看完本篇你就知道怎么用啦!
一、Groupby基本使用
① groupby可以通过传入需要分组的参数实现对数据的分组,参数可以是单列,也可以是多列,分组后可以对单列进行函数处理,也可以对多列进行函数处理
(两种写法:先筛选列再groupby或者先groupby再筛选列,结果都一样,只是如果先聚合,聚合列可以只写列名,不加变量名,因为没有筛选某列前,可以直接搜索到列)
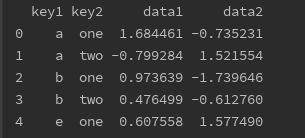
df = pd.DataFrame({'key1':list('aabbe'),
'key2':['one', 'two', 'one', 'two', 'one'],
'data1':np.random.randn(5),
'data2':np.random.randn(5)})
print(df)
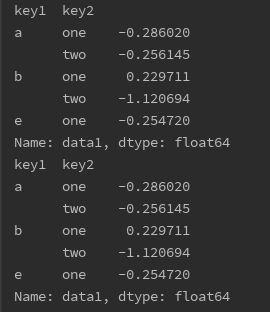
print(df['data1'].groupby([df['key1'],df['key2']]).mean())
print(df.groupby(['key1','key2'])['data1'].mean()) # 先筛选groupby要加df,先groupby()再写列,列不用加df,两者结果一样
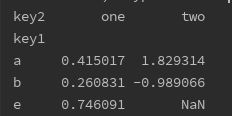
print(df['data2'].groupby([df['key1'], df['key2']]).mean().unstack()) # 增加透视效果
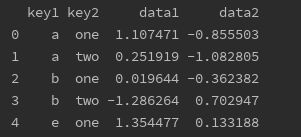
print(df.groupby([df['key1'], df['key2']],as_index=False).mean()) #分组键一般会作为分层索引,如果不想要,可以在group()中加上参数:as_index=False,会按从0开始的数据索引
print(df.groupby('key1').describe())
print(df.groupby('key1').size())
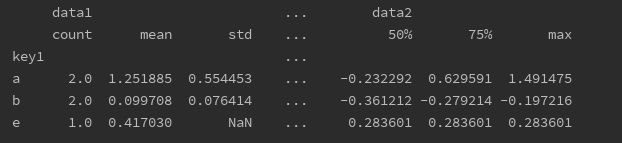
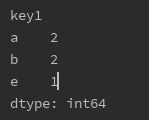
二、Group by与Agg
Groupby与agg使用,可以对单列或多列进行单一或多个不同的聚合函数处理, 常用函数如min,max,median,std,count,size,sum等,直接用函数加()即可,函数名要用;如果想同时用多个函数,用agg(函数名1,函数名2…),常用函数名要加上’’;函数名会默认为分组后的列名,如果想改列名,传入二元元组;如果希望不同列用不同函数,用agg({'列名1’:[‘函数名1’,‘函数名2,…],‘列名2’:[‘函数名2’,…],将字典单独赋值给变量会更优雅’'
print(df.groupby(['key1', 'key2']).agg('mean')) # 常用聚合函数用引号即可引用
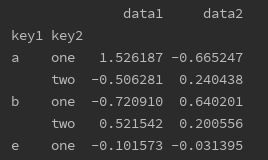
print(df.groupby(['key1', 'key2']).agg(['mean','std','sum','count'])) # 列表可以同时使用多个函数
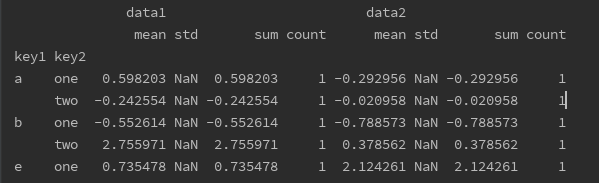
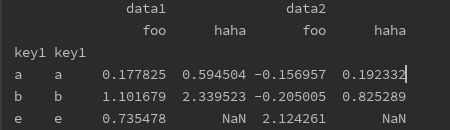
print(df.groupby(['key1', 'key1']).agg([('foo', 'mean'), ('haha', 'std')])) # 可以用元组修改函数名
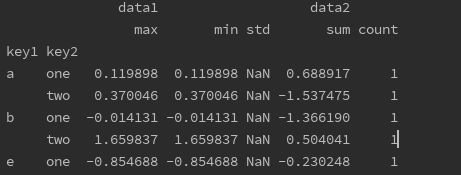
print(df.groupby(['key1', 'key2']).agg({'data1': ['max','min', 'std'],
'data2': ['sum', 'count']})) # 可以对不同的列使用不同的函数
三、Groupby与Apply
apply与agg相同点在于,都可以对分组后的结果进行运算,区别在于agg只能对单列,apply可以对多列进行;其次apply可以使用匿名函数,agg不行
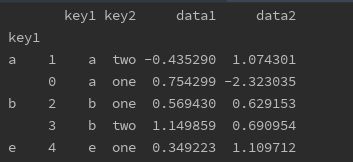
def top(df, n=2, column='data1'):
return df.sort_values(by=column)[-n:] # 自建函数
print(df.groupby('key1').apply(top))
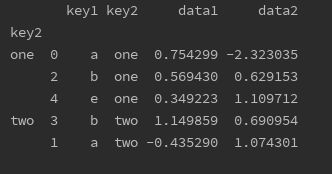
print(df.groupby('key2').apply(top, n=3, column='data2'))
四、Group by与pd.cut/pd.qcut
pd.qcut是等样本数, pd.cut是等值区间分,groupby和pd.cut和pd.qcut结合使用,可以对等值或等样本数分组后的结果进行分析
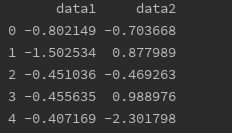
frame = pd.DataFrame({'data1':np.random.randn(1000),
'data2': np.random.randn(1000)})
print(frame)
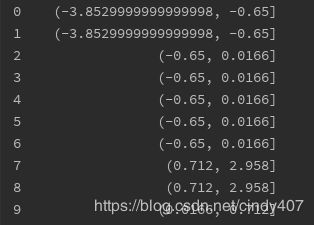
quariles = pd.cut(frame.data1, 4)
print(quariles[:10])
quriles_1 = pd.qcut(frame.data1,4)
print(quriles_1[:10])

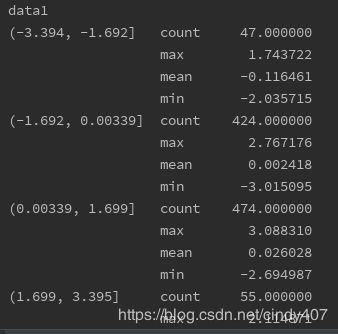
def get(group):
return {'min':group.min(), 'max':group.max(), 'count': group.count(), 'mean': group.mean()}
print(frame.data2.groupby(quariles).apply(get))
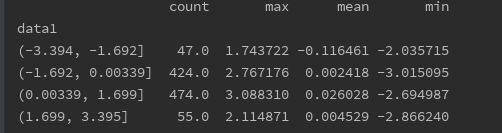
print(frame.data2.groupby(quariles).apply(get).unstack())
q = pd.qcut(frame.data1, 10, labels=False) # 去掉分组数值lable,采用默认的0开始的索引
print(df.data2.groupby(q).apply(get).unstack())
其余pandas系列如下,目前共有SQL\EXCLE\PANADS三个系列,后续还会继续出Numpy, matplotlib和机器学习相关,感兴趣地可以关注喔~~
Pandas数据分析①——数据读取(CSV/TXT/JSON)
https://blog.csdn.net/cindy407/article/details/90747049
Pandas数据分析②——数据清洗(重复值/缺失值/异常值)
https://blog.csdn.net/cindy407/article/details/90762774
Pandas数据分析③——数据规整1(索引和列名调整/数据内容调整/排序)
https://blog.csdn.net/cindy407/article/details/90896448
Pandas数据分析④——数据规整2(数据拼接/透视)
https://blog.csdn.net/cindy407/article/details/90896302