Pandas数据分析⑥——数据分析实例(货品送达率与合格率/返修率/拒收率)
Pandas系列目录如下:
Pandas数据分析①——数据读取(CSV/TXT/JSON)
Pandas数据分析②——数据清洗(重复值/缺失值/异常值)
Pandas数据分析③——数据规整1(索引和列名调整/数据内容调整/排序)
Pandas数据分析④——数据规整2(数据拼接/透视)
Pandas数据分析⑤——数据分组与函数使用(Groupby/Agg/Apply/mean/sum/count)
Pandas数据分析⑦——数据分析实例2(泰坦尼克号生存率分析)
数据是某企业销售的6种商品的送货及用户反馈数据,主要想要了解:
1、各月份、各区域、各货品的送货情况,哪一块是是急需要改进的
2、各货品在不同区域的反馈数据,看下每个商品的最佳市场和最差市场
3、各货品在不同区域的销售情况,看下哪块市场应该加强,哪块市场需要减少投资
4、分析下商品的送达情况与反馈情况是否有相关性?
详细分析如下(想要数据集的可以在评论区戳我喔~)
一、数据清洗
① 重复值、缺失值、格式调整
data = pd.read_csv('data.csv',encoding='gbk',header=0)
print(data.info())
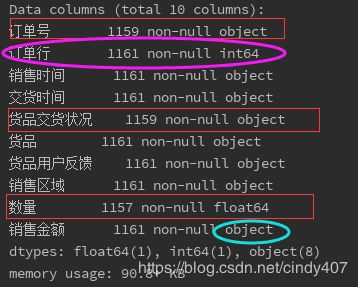
通过info()可以查看数据的轮廓,包括有10列,每1列的名字,数据量,格式等,从中可以明显看出:
①订单号,货品交货情况,数量这3列是有缺失值,但最多缺失4行,数据量较小,直接删除不会影响整体分析
②订单行这1列对分析无关紧要,可以删除
③销售金额格式不对,要改成float
# 删除重复值,这个虽然没有看出来,但是必须要在其它处理前处理掉
print(data.duplicated().value_counts())
data.drop_duplicates(keep='first',inplace=True)
# 删除缺失值
data.dropna(how='any',inplace=True)
# 去掉“订单行”列
data.drop(columns=['订单行'],inplace=True,axis=1)
data = data.reset_index(drop=True)
print(data.head())

# 修改销售金额格式
print(data.销售金额.head()) # 数据单位不一致,且数据中有逗号隔开,不适合分析

def data_deal(number):
if number.find('万元')!=-1:
data = float(number[:number.find('万元')].replace(',',''))*10000
else:
data = number.replace('元','')
data = float(data.replace(',',''))
return data
data['销售金额'] = data['销售金额'].map(data_deal)

② 异常值处理
print(data.describe())

通过describe()可以对连续变量进行统计描述分析,从结果可以看出
①销售金额存在等于0的,属于异常,要删除
②数量和销售金额的标准差都在均值的8倍以上,,结合最大值和75%分位数可知,存在部分较大的值导致数据左偏非常严重,可以通过describe(percentiles)参数再细致地看下较大值的分布情况
data = data[data['销售金额'] != 0 ]
print(data.describe(percentiles=np.linspace(0.98,0.9999,15)))
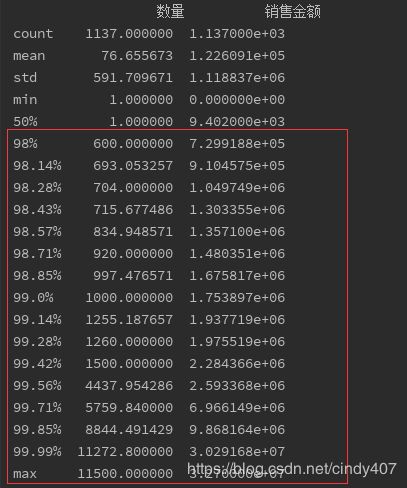
从98%以上分位数可看出,数量是不断增加,销售额也随数量不断增加,在电商行业,确实存在这样的帕累托效应,20%的大户可能会贡献80%的份额,因此这部分不算异常数据,在进行与数量和金额无关的分析时可以保留,有关时可以剔除掉不看,至此数据清洗完毕
二、数据规整
由于后续会有关于不同月份的分析,因此要增加一项辅助列:月份
# 增加辅助列:
data['月份'] = data['销售时间'].apply(lambda x: int(x[x.find('/',0)+1: x.find('/',5)]))
print(data.head())

三、数据分析
① 各月份、各区域、各货品的送货情况,哪一块是是急需要改进的
# 月份
data['货品交货状况'] = data['货品交货状况'].str.strip()
data1 = data.groupby(['月份','货品交货状况']).size().unstack()
print(data1)
data1['按时交货率'] = data1['按时交货']/data1.sum(axis=1)
print(data1.sort_index())

从按时交货率看,16年Q4普通要低于Q3,猜测可能是气候原因
# 销售区域
data1 = data.groupby(['销售区域','货品交货状况']).size().unstack()
print(data1)
data1['按时交货率'] = data1['按时交货']/data1.sum(axis=1)
print(data1.sort_values('按时交货率',ascending=False))
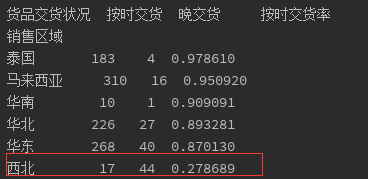
海外送货相对麻烦,但是按时交货率却高于国内,从国内看,西北存在最突出的送货延迟问题,急需解决
# 货品
data1 = data.groupby(['货品','货品交货状况']).size().unstack()
print(data1)
data1['按时交货率'] = data1['按时交货']/data1.sum(axis=1)
print(data1.sort_values('按时交货率',ascending=False))

货品4晚交货的情况最为严重,其余还相对较好
# 货品和销售区域结合
data1 = data.groupby(['货品','销售区域','货品交货状况']).size().unstack()
print(data1)
data1['按时交货率'] = data1['按时交货']/data1.sum(axis=1)
print(data1.sort_values('按时交货率',ascending=False))
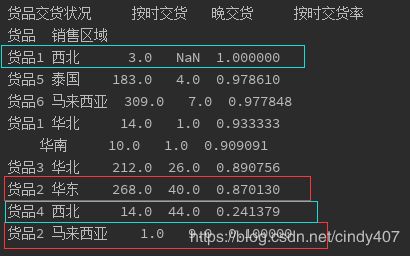
结合销售区域和货品一起看,销售区域送货最差的为西北,主要送的货品有货品1和货品4,主要是货品4的送货较晚所致;货品送货最差的是货品2,主要送往华东和马来西亚,主要是马来西亚的送货较晚所致;因此,要重点解决货品4送往西北、货品2送往马来西亚的问题
② 各货品在不同月份、不同区域的销售情况,看下哪块市场应该加强,哪块市场需要减少投资
# 不同月份
data1 = data.groupby(['月份','货品'])['数量'].sum().unstack()
print(data1)
# 解决不能显示中文的问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['font.serif'] = ['SimHei']
data1.plot()
plt.show()

货品2在10月和12月销售量暴增,其余货品销售量都趋于稳定,后面会看下货品2是否开发了新市场
# 不同区域
data1 = data.groupby(['销售区域','货品'])['数量'].sum().unstack()
print(data1)

从销售区域看,每种货品都是集中在1到3个区域销售,货品1是销售区域最多的,达到3个,货品2次之,2个,其余货品都是1个区域;
# 不同月份和区域
data1 = data.groupby(['月份','销售区域','货品'])['数量'].sum().unstack()
print(data1['货品2'])
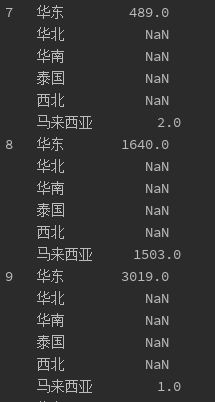

重点看了下销售数量有较大变动的货品2, 发现其在10月和12月的销售增长并非是开拓了新市场,而是在原有的华东地区增加了销量,猜测可能是对货品2在华东地区加大了营销推广所致。同时也证明货品2在华东地区还有较大的市场空间,适合加大投入
③各货品在不同区域的反馈数据,看下每个商品的最佳市场和最差市场
data['货品用户反馈'] = data['货品用户反馈'].str.strip()
data1 = data.groupby(['货品','销售区域'])['货品用户反馈'].value_counts().unstack()
data1['拒货率'] = data1['拒货']/data1.sum(axis=1)
data1['返修率'] = data1['返修']/data1.sum(axis=1)
data1['合格率'] = data1['质量合格']/data1.sum(axis=1)
print(data1.sort_values(['合格率','返修率', '拒货率'],ascending=False))

货品3,5,6的合格率均较高,货品1,2,4较差。
<>货品4在西北的拒收率是最高的,结合上述对货品按时收获率的分析可知,货品4送往西北的按时送货率倒数第2,说明主要是货物延误导致较高的拒收率,鉴于货品2目前仅在西北销售,建议找到延误的核心原因,予以改进;
<>货品2在马来西亚返修率是最高的,结合按时收货率看,货品2在马来西亚的延误也是比较严重的,因此说明也是延误导致的返修率;但基于货品2主要的销售地区是华东且在10月和12月有较高的涨幅,可以考虑增大华东的投资,减少马来西亚的投入。
④分析下商品的送达情况与反馈情况是否有相关性?
data1 = data.groupby(['货品','货品交货状况']).size().unstack()
data1['按时交货率'] = data1['按时交货']/data1.sum(axis=1)
print(data1)
data['货品用户反馈'] = data['货品用户反馈'].str.strip()
data2 = data.groupby(['货品'])['货品用户反馈'].value_counts().unstack()
data2['拒货率'] = data2['拒货']/data2.sum(axis=1)
data2['返修率'] = data2['返修']/data2.sum(axis=1)
data2['合格率'] = data2['质量合格']/data2.sum(axis=1)
print(data2)
# 将两个表合并
data = pd.merge(data1,data2,on='货品',how='inner')
print(data)
plt.figure()
# 用散点图观察相关性
plt.scatter(data['按时交货率'],data['合格率'])
plt.scatter(data['按时交货率'],data['返修率'])
plt.scatter(data['按时交货率'],data['拒货率'])
plt.legend(loc='center left')
plt.show()

从图上可看出,按时交货率与合格率基本成正相关关系,而返修率和拒货率与按时到货没有太明显的关系,除非按时到货率特别特别低时,才会导致返修率较高;因此保证及时的到货率是最重要的,而对于返修率和拒收率较高的,可以具体从返修的问题或者拒收的原因去寻找答案!
总结一下:
1、重点解决货品4送往西北、货品2送往马来西亚延误严重的问题
2、可加大货品2在西北地区的销售投入,减少在马来西亚的投入
3、按时送达可以提升合格率,因此加大物流投入, 能提升合格率,也就相对减少了拒收和返修率
喜欢的请点个赞喔~~