【机器学习】K邻近算法
K邻近算法
K邻近算法
1.什么是K邻近孙算法
2.scikit-learn中的机器学习算法封装
3.训练数据集,测试数据集
4.分类准确度
5.超参数
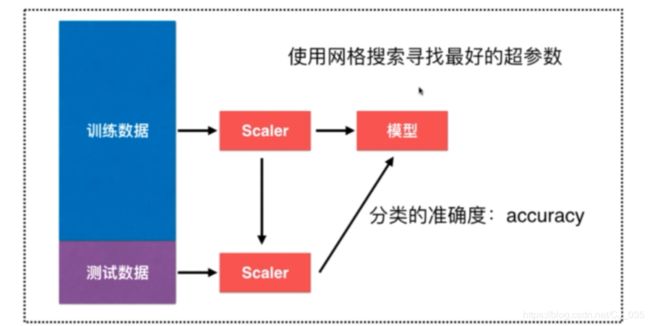
6.网格搜索与k近邻算法中更多超参数
7.数据归一化
8.scikit-learn中的Scaler
9.K邻近算法的缺点
1.什么是K邻近孙算法


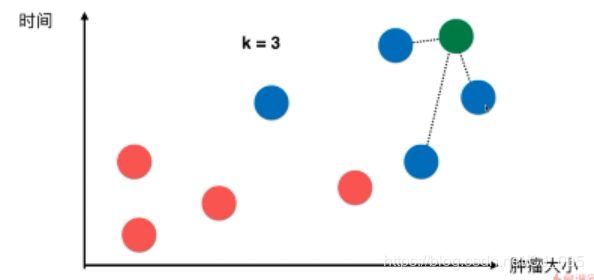

##KNN的过程
import numpy as np
import matplotlib.pyplot as plt
raw_data_x = [[3.39, 2.33],
[3.11, 1.78],
[1.34, 3.36],
[3.58, 3.36],
[2.28, 2.86],
[7.42, 4.69],
[5.74, 3.53],
[9.17, 2.51],
[7.79, 3.42],
[7.93, 0.79]
]
raw_data_y = [0,0,0,0,0,1,1,1,1,1]
X_train = np.array(raw_data_x)
y_train = np.array(raw_data_y)
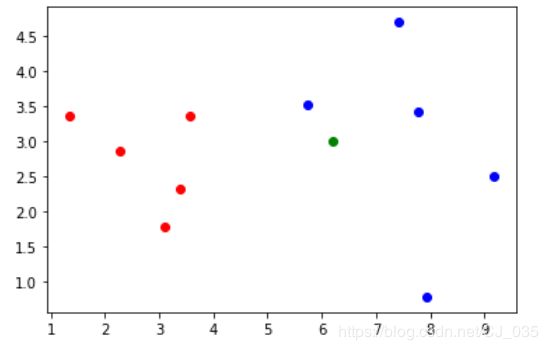
x = np.array([6.2, 3.0])
plt.scatter(X_train[y_train==0, 0], X_train[y_train==0, 1], color = "red")
plt.scatter(X_train[y_train==1, 0], X_train[y_train==1, 1], color = "blue")
plt.scatter(x[0], x[1], color = "g")
plt.show()
from math import sqrt
distances = []
for x_train in X_train:
d = sqrt(np.sum((x_train - x) ** 2))
distances.append(d)
nearest = np.argsort(distances)
k = 6
topK_y = [y_train[i] for i in nearest[:k]]
from collections import Counter
Counter(topK_y)
votes = Counter(topK_y)
votes.most_common(1)[0][0]
predict_y = votes.most_common(1)[0][0]
predicate_y

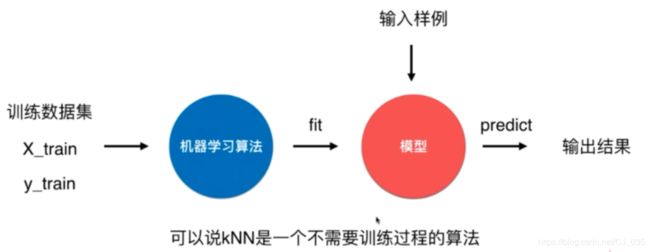
2.scikit-learn中的机器学习算法封装

import numpy as np
import matplotlib.pyplot as plt
raw_data_x = [[3.39, 2.33],
[3.11, 1.78],
[1.34, 3.36],
[3.58, 3.36],
[2.28, 2.86],
[7.42, 4.69],
[5.74, 3.53],
[9.17, 2.51],
[7.79, 3.42],
[7.93, 0.79]
]
raw_data_y = [0,0,0,0,0,1,1,1,1,1]
X_train = np.array(raw_data_x)
y_train = np.array(raw_data_y)
x = np.array([6.2, 3.0])
from sklearn.neighbors import KNeighborsClassifier
KNN_classifier = KNeighborsClassifier()
KNN_classifier.fit(X_train, y_train)
X_predict = x.reshape(1,-1) #需要传入一个矩阵,即对于多组数据,预测出多组值
KNN_classifier.predict(X_predict)
3.训练数据集,测试数据集
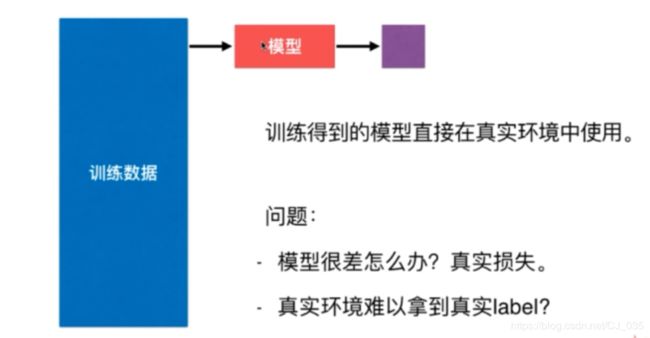
用所有的原始数据作为训练集,训练出模型,就直接使用的话,这样是不恰当的
因为模型训练出来很差的话,而我们又无法直接改进,只能干巴巴的使用,会造成很大的影响

import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
iris = datasets.load_iris()
#数据集内包含 3 类共 150 条记录,每类各 50 个数据,
#每条记录都有 4 项特征:花萼长度、花萼宽度、花瓣长度、花瓣宽度
#可以通过这4个特征预测鸢尾花卉属于
#(iris-setosa, iris-versicolour, iris-virginica)中的哪一品种。
X = iris.data
y = iris.target
##train_test_split
##随机化数据集
shuffle_indexes = np.random.permutation(len(X))
#shuffle_indexes
test_ratio = 0.2
test_size = int(len(X) * test_ratio)
test_size
test_indexes = shuffle_indexes[:test_size]
train_indexes = shuffle_indexes[test_size:]
X_train = X[train_indexes]
y_train = y[train_indexes]
X_test = X[test_indexes]
y_test = y[test_indexes]
##使用自己的算法进行测试
import numpy as np
from math import sqrt
from collections import Counter
class KNNClassifier:
def __init__(self, k):
"""初始化kNN分类器"""
assert k >= 1, "k must be valid"
self.k = k
self._X_train = None
self._y_train = None
def _accuracy_score(y_true, y_predict):
"""计算y_true和y_predict之间的准确率"""
assert len(y_true) == len(y_predict), \
"the size of y_true must be equal to the size of y_predict"
return np.sum(y_true == y_predict) / len(y_true)
def fit(self, X_train, y_train):
"""根据训练数据集X_train和y_train训练kNN分类器"""
assert X_train.shape[0] == y_train.shape[0], \
"the size of X_train must be equal to the size of y_train"
assert self.k <= X_train.shape[0], \
"the size of X_train must be at least k."
self._X_train = X_train
self._y_train = y_train
return self
def predict(self, X_predict):
"""给定待预测数据集X_predict,返回表示X_predict的结果向量"""
assert self._X_train is not None and self._y_train is not None, \
"must fit before predict!"
assert X_predict.shape[1] == self._X_train.shape[1], \
"the feature number of X_predict must be equal to X_train"
y_predict = [self._predict(x) for x in X_predict]
return np.array(y_predict)
def _predict(self, x):
"""给定单个待预测数据x,返回x的预测结果值"""
assert x.shape[0] == self._X_train.shape[1], \
"the feature number of x must be equal to X_train"
distances = [sqrt(np.sum((x_train - x) ** 2))
for x_train in self._X_train]
nearest = np.argsort(distances)
topK_y = [self._y_train[i] for i in nearest[:self.k]]
votes = Counter(topK_y)
return votes.most_common(1)[0][0]
def score(self, X_test, y_test):
"""根据测试数据集 X_test 和 y_test 确定当前模型的准确度"""
y_predict = self.predict(X_test)
return self._accuracy_score(y_test, y_predict)
def __repr__(self):
return "KNN(k=%d)" % self.k
my_knn_clf = KNNClassifier(k=3)
my_knn_clf.fit(X_train, y_train)
y_predict = my_knn_clf.predict(X_test)
sum( y_predict == y_test)
sum(y_predict == y_test)/len(y_test)
#sklearn中的train_test_split
from sklearn .model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 666)
print(X_train.shape)
print(y_train.shape)4.分类准确度
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
from sklearn import datasets
digits = datasets.load_digits()
digits.keys()
X = digits.data
y = digits.target
X.shape #X总共有1797个样本,每个样本代表一个手写数字字,
#每个手写数字由一连串的数字组成,即像素点,8x8为一张图像是一个手写数字
y.shape
#可视化8x8的数字,将原来一行64列的数字转化
some_digit = X[666]
some_digit_image = some_digit.reshape(8, 8)
plt.imshow(some_digit_image, cmap = matplotlib.cm.binary)
plt.show()
def train_test_split(X, y, test_ratio=0.2, seed=None):
"""将数据 X 和 y 按照test_ratio分割成X_train, X_test, y_train, y_test"""
assert X.shape[0] == y.shape[0], \
"the size of X must be equal to the size of y"
assert 0.0 <= test_ratio <= 1.0, \
"test_ration must be valid"
if seed:
np.random.seed(seed)
shuffled_indexes = np.random.permutation(len(X))
test_size = int(len(X) * test_ratio)
test_indexes = shuffled_indexes[:test_size]
train_indexes = shuffled_indexes[test_size:]
X_train = X[train_indexes]
y_train = y[train_indexes]
X_test = X[test_indexes]
y_test = y[test_indexes]
return X_train, X_test, y_train, y_test
X_train, X_test, y_train, y_test = train_test_split(X, y, test_ratio = 0.2, seed = 666)
import numpy as np
from math import sqrt
from collections import Counter
class KNNClassifier:
def __init__(self, k):
"""初始化kNN分类器"""
assert k >= 1, "k must be valid"
self.k = k
self._X_train = None
self._y_train = None
def _accuracy_score(y_true, y_predict):
"""计算y_true和y_predict之间的准确率"""
assert len(y_true) == len(y_predict), \
"the size of y_true must be equal to the size of y_predict"
return np.sum(y_true == y_predict) / len(y_true)
def fit(self, X_train, y_train):
"""根据训练数据集X_train和y_train训练kNN分类器"""
assert X_train.shape[0] == y_train.shape[0], \
"the size of X_train must be equal to the size of y_train"
assert self.k <= X_train.shape[0], \
"the size of X_train must be at least k."
self._X_train = X_train
self._y_train = y_train
return self
def predict(self, X_predict):
"""给定待预测数据集X_predict,返回表示X_predict的结果向量"""
assert self._X_train is not None and self._y_train is not None, \
"must fit before predict!"
assert X_predict.shape[1] == self._X_train.shape[1], \
"the feature number of X_predict must be equal to X_train"
y_predict = [self._predict(x) for x in X_predict]
return np.array(y_predict)
def _predict(self, x):
"""给定单个待预测数据x,返回x的预测结果值"""
assert x.shape[0] == self._X_train.shape[1], \
"the feature number of x must be equal to X_train"
distances = [sqrt(np.sum((x_train - x) ** 2))
for x_train in self._X_train]
nearest = np.argsort(distances)
topK_y = [self._y_train[i] for i in nearest[:self.k]]
votes = Counter(topK_y)
return votes.most_common(1)[0][0]
def score(self, X_test, y_test):
"""根据测试数据集 X_test 和 y_test 确定当前模型的准确度"""
y_predict = self.predict(X_test)
return self._accuracy_score(y_test, y_predict)
def __repr__(self):
return "KNN(k=%d)" % self.k
my_knn_clf = KNNClassifier(k=4)
my_knn_clf.fit(X_train, y_train)
y_predict = my_knn_clf.predict(X_test)
sum(y_predict == y_test) / len(y_test)5.超参数
超参数和模型参数


##超参数
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
from sklearn import datasets
digits = datasets.load_digits()
X = digits.data
y = digits.target
from sklearn .model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 666)
from sklearn.neighbors import KNeighborsClassifier
KNN_classifier = KNeighborsClassifier()
KNN_classifier.fit(X_train, y_train)
KNN_classifier.score(X_test, y_test)
##寻找最好的K
best_score = 0.0
best_k = -1
for k in range(1,11):
KNN_clf = KNeighborsClassifier(n_neighbors=k)
KNN_clf.fit(X_train, y_train)
score = KNN_clf.score(X_test, y_test)
if(score > best_score):
best_k = k
best_score = score
print(best_k)
print(best_score)
##引入距离
best_method = ""
best_score = 0.0
best_k = -1
for method in ["uniform", "distance"]:
for k in range(1,11):
KNN_clf = KNeighborsClassifier(n_neighbors=k, weight = method)
KNN_clf.fit(X_train, y_train)
score = KNN_clf.score(X_test, y_test)
if(score > best_score):
best_k = k
best_score = score
best_method = method
print(best_method)
print(best_k)
print(best_score)



##搜索明可夫斯基距离相应的p
%%time
best_p = -1
best_score = 0.0
best_k = -1
for p in range(1,6):
for k in range(1,11):
KNN_clf = KNeighborsClassifier(n_neighbors=k, weights="distance")
KNN_clf.fit(X_train, y_train)
score = KNN_clf.score(X_test, y_test)
if(score > best_score):
best_k = k
best_score = score
best_p = p
print(best_p)
print(best_k)
print(best_score)6.网格搜索与k近邻算法中更多超参数
## 寻找最好的K
best_score = 0.0
best_k = -1
for k in range(1,11):
KNN_clf = KNeighborsClassifier(n_neighbors=k)
KNN_clf.fit(X_train, y_train)
score = KNN_clf.score(X_test, y_test)
if(score > best_score):
best_k = k
best_score = score
print(best_k)
print(best_score)
##引入距离
best_method = ""
best_score = 0.0
best_k = -1
for method in ["uniform", "distance"]:
for k in range(1,11):
KNN_clf = KNeighborsClassifier(n_neighbors=k, weights = method)
KNN_clf.fit(X_train, y_train)
score = KNN_clf.score(X_test, y_test)
if(score > best_score):
best_k = k
best_score = score
best_method = method
print(best_method)
print(best_k)
print(best_score)
##搜索明可夫斯基距离相应的p
%%time
best_p = -1
best_score = 0.0
best_k = -1
for p in range(1,6):
for k in range(1,11):
KNN_clf = KNeighborsClassifier(n_neighbors=k, weights="distance")
KNN_clf.fit(X_train, y_train)
score = KNN_clf.score(X_test, y_test)
if(score > best_score):
best_k = k
best_score = score
best_p = p
print(best_p)
print(best_k)
print(best_score)
##网格搜索
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
from sklearn import datasets
digits = datasets.load_digits()
X = digits.data
y = digits.target
from sklearn .model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 666)
from sklearn.neighbors import KNeighborsClassifier
KNN_classifier = KNeighborsClassifier()
KNN_classifier.fit(X_train, y_train)
KNN_classifier.score(X_test, y_test)
##Grid Search
param_grid = [
{
'weights':['uniform'],
'n_neighbors':[i for i in range(1, 11)]
},
{
'weights':['distance'],
'n_neighbors':[i for i in range(1, 11)],
'p':[i for i in range(1, 6)]
}
]##网格搜索找到了最佳分类器,包含其对应的参数
knn_clf = KNeighborsClassifier()
from sklearn.model_selection import GridSearchCV
grid_search = GridSearchCV(knn_clf, param_grid)#CV的交叉验证,会相对与之前不同
%%time
grid_search.fit(X_train, y_train)
grid_search.best_estimator_
grid_search.best_score_
grid_search.best_params_
knn_clf = grid_search.best_estimator_
knn_clf.predict(X_test)
knn_clf.score(X_test, y_test)
%%time
grid_search = GridSearchCV(knn_clf, param_grid, n_jobs=-1, verbose=2)
grid_search.fit(X_train, y_train)
'''
其实GridSearch这个类的超参数还有metric_params, metrics等。此外还有一些帮助我们更好理解网格搜索的参数,比如n_jobs表示计算机用多少个核进行。如果为-1表示使用全部的核。比如在搜索的过程中能够显示一些日志信息,verbose,这个值越大输出的值越详细,一般取2就够用了。
'''
7.数据归一化



数据归一化的目的,就是将数据的所有特征都映射到同一尺度上,这样可以避免由于量纲的不同使数据的某些特征形成主导作用。
均值方差归一化的特点是,可以将数据归一化到均值为0方差为1的分布中,不容易受到异常值(outlier)影响
##最值归一化
import numpy as np
import matplotlib.pyplot as plt
X = np.random.randint(0, 100, (50,2))
X = np.array(X, dtype = float)
for i in range(0,2):
X[:, i] = (X[:, i] - np.min(X[:, i])) / (np.max(X[:, i]) - np.min(X[:, i]))
plt.scatter(X[:, 0], X[:, 1])
plt.show()
np.mean(X[:, 0])
np.mean(X[:, 1])
np.std(X[:, 0])
np.std(X[:, 1])
##均值方差归一化
X2 = np.random.randint(0, 100, (50, 2))
X2 = np.array(X2, dtype = float)
X2[:, 0] = (X2[:, 0] - np.mean(X2[:, 0])) / np.std(X2[:, 0])
X2[:, 1] = (X2[:, 1] - np.mean(X2[:, 0])) / np.std(X2[:, 1])
plt.scatter(X2[:, 0], X2[:, 1])
plt.show()
np.mean(X[:, 0])
np.mean(X[:, 1])
np.std(X[:, 0])
np.std(X[:, 1])
8.scikit-learn中的Scaler

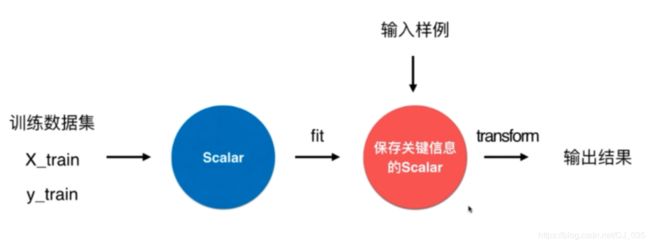
对于单个数据而言,无法得到一个X_mean和X_std,因此在考虑的时候都是以训练数据集的X_mean和X_std作为标准
###Scikit-learn中的Scalar
import numpy as np
from sklearn import datasets
iris = datasets.load_iris()
X = iris.data
y = iris.target
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 666)
##scikit-learn中的StandardScaler
from sklearn.preprocessing import StandardScaler
standardScaler = StandardScaler()
standardScaler.fit(X_train)
standardScaler.mean_ #均值
standardScaler.scale_ #方差
X_train = standardScaler.transform(X_train)
X_test_standard = standardScaler.transform(X_test)
from sklearn.neighbors import KNeighborsClassifier
knn_clf = KNeighborsClassifier(n_neighbors=3)
knn_clf.fit(X_train, y_train)
knn_clf.score(X_test_standard, y_test)9.K邻近算法的缺点:
1.效率低下,如果训练集有m个样本,n个特征,那么预测一个新的数据就需要O(m*n),可用树结构优化,KD-Tree,Ball-Tree等
2.高度数据相关,对数据的敏感度很高
3.预测的结果具有不可解释性
4.维数灾难,对于同一个点,在不同的维度下,结果不同,解决:降维