机器学习实战——线性回归和局部加权线性回归(含python中复制的四种情形!)
IDE:PyCharm Edu 4.02
环境:Adaconda3 python3.6
注:本程序相比原书中的程序区别,主要区别在于函数验证和绘图部分。
一、一般线性回归(最小二乘法OLS)
回归系数求解公式:
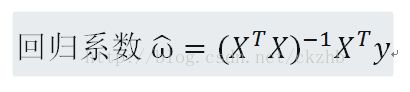
说明:X矩阵中每一行是一个样本,y是列向量。只有逆矩阵存在的时候使用,必须在代码中进行判断。
from numpy import *
import matplotlib.pyplot as plt
# 自适应数据加载函数
# 不必指定特征数目,
def loadDataSet(fileName): #general function to parse tab -delimited floats
numFeat = len(open(fileName).readline().split('\t'))-1 #get number of fields
dataMat = [];labelMat = []
with open(fileName) as fr:
for line in fr.readlines():
lineArr = []
curLine = line.strip().split('\t')
for i in range(numFeat):
lineArr.append(float(curLine[i]))
dataMat.append(lineArr)
labelMat.append(float(curLine[-1]))
return dataMat,labelMat # 返回列表
# xMat:每一行是一个样本
def standRegres(xArr,yArr):
xMat = mat(xArr)
yMat = mat(yArr).T
xTx = xMat.T * xMat
if linalg.det(xTx)==0.0: #判断是否可逆
print('This matrix is singular,cannot do inverse')
return
ws = xTx.I * (xMat.T * yMat)
return ws #返回矩阵
x,y = loadDataSet('ex0.txt') # 文件中第一列全为1
def test(x,y):
# 绘制散点图
xMat = array(x)
yMat = array(y)
ws1 = standRegres(x,y)
fig = plt.figure(1)
ax = fig.add_subplot(111)
ax.scatter(xMat[:,1],yMat.transpose())
# 绘制拟合曲线
# 排序后在画拟合直线??
y_fit = dot(xMat,ws1) # 矩阵乘法
# 计算相关序列
print(corrcoef(y_fit.transpose(),yMat))
ax.plot(xMat[:,1],y_fit,c='r')
plt.show()
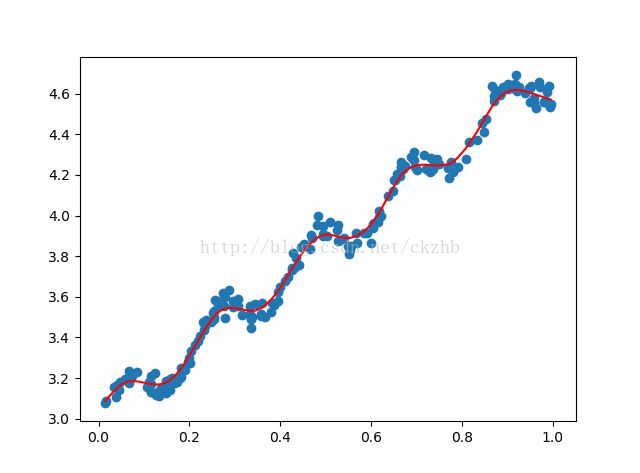
#print(test(x,y))二、局部线性加权回归LWLR
线性回归的一个问题是欠拟合,考虑加入一些偏差,降低预测的均方误差。
LWLR方法对待预测的每个点赋予一定的权重,在这样的一个子集上基于最小均方差来进行普通的回归。
因此,会增加计算量,它对每个点做预测时都必须使用整个数据集。
权重常采用“核”函数的方式进行加权,本程序使用高斯核。
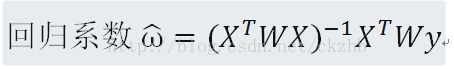
说明:等号右边的W表示权重系数。
# 数据加载函数同上
# 局部线性加权回归
# k:高斯核参数
def lwlr(testPoint,xArr,yArr,k=1.0):
xMat = mat(xArr)
yMat = mat(yArr).T
m = shape(xMat)[0]
weights = mat(eye(m))
for j in range(m):
diffMat = testPoint - xMat[j,:]
weights[j,j] = exp(diffMat*diffMat.T/(-2.0*k**2))
xTx = xMat.T * (weights * xMat)
if linalg.det(xTx) == 0.0:
print('This matrix is singular,cannot do inverse')
return
ws = xTx.I * (xMat.T * (weights * yMat))
return testPoint*ws
#print(lwlr(x[0],x,y,1.0))
def lwlrTest(testArr,xArr,yArr,k=1.0):
#获取所有数据的估计值
xMat = mat(xArr)
yMat = mat(yArr)
m,n = shape(xMat)
y_fit = zeros(m)
for i in range(m):
y_fit[i] = lwlr(testArr[i],xArr,yArr,k)
# 绘制散点图
fig = plt.figure(1)
ax = fig.add_subplot(111)
ax.scatter(xMat[:,1].flatten().getA(),yMat.getA()) #必须是数组的形式
# 绘制拟合曲线
# 排序后再画拟合直线
srtIndex = xMat[:,1].argsort(axis=0)
xSort = xMat[srtIndex][:,0,:]
ySort = y_fit[srtIndex]
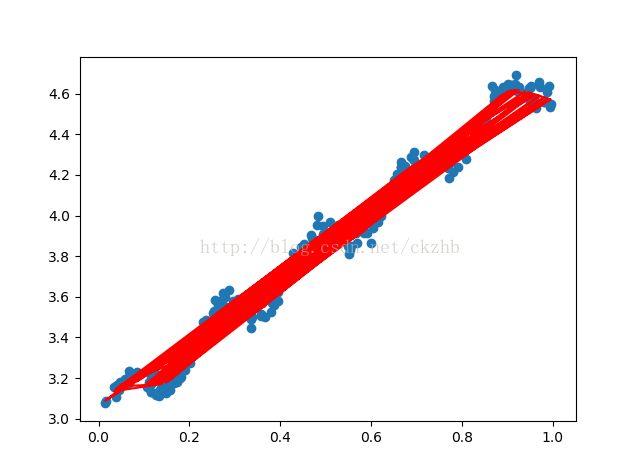
#ax.plot(xMat[:,1],y_fit,c='r') #未排序,曲线明显出错
ax.plot(xSort[:,1],ySort,c='r')
plt.show()
return y_fit
print(lwlrTest(x,x,y,0.03))注解:
1、绘制图形时报错:Masked arrays must be 1-D
解决:scatter()中参数必须是1-D的array,但plot()总参数可以是矩阵。
ax.scatter(xMat[:,1].flatten().getA(),yMat.getA()) #必须是数组的形式解释:http://blog.csdn.net/qq_18433441/article/details/54916991
numpy的flatten()可以将二维矩阵变为一维的矩阵,但此时依然是矩阵类型。
from numpy import *
a=[[1,2,3],[4,5,6]]
mat1 = mat(a)
mat2 = mat1.flatten() #依然是matrix类型
mat3 = mat2.getA() # array类型
print(a)
print(mat1)
print(mat2,type(mat2))
print(mat3,type(mat3))2、copy()方法、引用
具体解释:http://blog.csdn.net/qq_32907349/article/details/52190796
情形一:原对象整体改变
结果:引用后对象和copy()后对象不随原对象而改变
from numpy import *
b1=array([1,2,3,4,5,6])
b2=b1
b3=b1.copy()
b1=b1*2
print(b1)
print(b2)
print(b3)
[ 2 4 6 8 10 12]
[1 2 3 4 5 6]
[1 2 3 4 5 6]情形二:原对象部分元素改变
结果:引用对象随原对象改变,copy()后的对象不变
from numpy import *
b1=array([1,2,3,4,5,6])
b2=b1
b3=b1.copy()
b1[0]=100
print(b1)
print(b2)
print(b3)
[100 2 3 4 5 6]
[100 2 3 4 5 6]
[1 2 3 4 5 6]情形三:原对象中有子对象情形
结果:子对象变化时,引用后对象和copy()后对象均随原对象而改变。但是,非子对象变化的结果同上。
(1)非子对象改变
b1=[1,2,[3,4]]
b2=b1
b3=b1.copy()
b1[0]=100
print(b1)
print(b2)
print(b3)
[100, 2, [3, 4]]
[100, 2, [3, 4]]
[1, 2, [3, 4]]
b1=[1,2,[3,4]]
b2=b1
b3=b1.copy()
#b1[0]=100
b1[2][0] = 100
print(b1)
print(b2)
print(b3)
[1, 2, [100, 4]]
[1, 2, [100, 4]]
[1, 2, [100, 4]]提示:array()中元素类型必须一致。
比如array([1,2,[3,4]]) 错误
情形四:完全复制
copy库函数之deepcopy(),list无deepcopy属性,因此list.deepcopy()错误!
import copy
b1=[1,2,[3,4]]
b2=b1
b3=b1.copy()
b4=copy.deepcopy(b1)
#b1[0]=100
b1[2][0] = 100
print(b1)
print(b2)
print(b3)
print(b4)
[1, 2, [100, 4]]
[1, 2, [100, 4]]
[1, 2, [100, 4]]
[1, 2, [3, 4]]3、问题:拟合曲线绘制前必须先对数据线进行排序,否则易出错!!!
未排序绘制的拟合曲线:
排序后再绘制拟合曲线: