Eclipse构建普通的MapReduce项目
jdk安装后好后配置相关JAVA_HOME环境变量,并将bin目录配置到path
2. 下载hadoop-2.7.1.tar.gz,并且解压到你的路径下D:\XXXX\workspace\hadoop-2.7.1
https://dist.apache.org/repos/dist/release/hadoop/common/hadoop-2.7.1/hadoop-2.7.1.tar.gz
3. 下载hadoop2x-eclipse-plugin
https://github.com/winghc/hadoop2x-eclipse-plugin
4. 下载hadoop-common-2.7.1.bin.zip,并解压
将hadoop.dll和winutils.exe文件分别放到D:\XXXX\workspace\hadoop-2.7.1\bin
和C:\Windows\System32目录下
5. 解压hadoop2x-eclipse-plugin ,把hadoop-eclipse-plugin-2.6.0.jar拷贝至eclipse的plugins目录下,然后重启eclipse
6. 打开菜单Window--Preference--Hadoop Map/Reduce进行配置,如下图所示:
7. 显示Hadoop连接配置窗口:Window--Show View--Other-MapReduce Tools,如下图所示:
8. 配置连接Hadoop,如下图所示:
查看是否连接成功,能看到如下信息,则表示连接成功:
9. 配置hadoop环境变量
添加环境变量HADOOP_HOME=D:\XXX\workspace\hadoop-2.7.1
追加环境变量path内容:%HADOOP_HOME%/bin
10.创建一个Map/Reduce Project
新建项目 File--New--Other--Map/Reduce Project 命名为MR1,
然后创建类com.hadoop.worldcount.MyWordCount
package com.hadoop.worldcount;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class MyWordCount {
public static class TokenizerMapper extends Mapper {
/**
* Mapper中的map方法:
* void map(K1 key, V1 value, Context context)
* 映射一个单个的输入k/v对到一个中间的k/v对
* 输出对不需要和输入对是相同的类型,输入对可以映射到0个或多个输出对。
* Context:收集Mapper输出的对。
* Context的write(k, v)方法:增加一个(k,v)对到context
* 程序员主要编写Map和Reduce函数.这个Map函数使用StringTokenizer函数对字符串进行分隔,通过write方法把单词存入word中
* write方法存入(单词,1)这样的二元组到context中
*/
@Override
protected void map(LongWritable key, Text value, Mapper.Context context)
throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
context.write(new Text(itr.nextToken()), new IntWritable(1));
}
}
}
public static class IntSumReducer extends Reducer {
/**
* Reducer类中的reduce方法:
* void reduce(Text key, Iterable values, Context context)
* 中k/v来自于map函数中的context,可能经过了进一步处理(combiner),同样通过context输出
*/
@Override
protected void reduce(Text key, Iterable values,
Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
context.write(key, new IntWritable(sum));
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
/**
* Configuration:map/reduce的j配置类,向hadoop框架描述map-reduce执行的工作
*/
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "myWordCount"); //设置一个用户定义的job名称
job.setJarByClass(MyWordCount.class);
job.setMapperClass(TokenizerMapper.class); //为job设置Mapper类
job.setCombinerClass(IntSumReducer.class); //为job设置Combiner类
job.setReducerClass(IntSumReducer.class); //为job设置Reducer类
job.setOutputKeyClass(Text.class); //为job的输出数据设置Key类
job.setOutputValueClass(IntWritable.class); //为job输出设置value类
FileInputFormat.addInputPath(job, new Path("hdfs://192.168.24.203:9000/user/world.txt"));
FileOutputFormat.setOutputPath(job, new Path("hdfs://192.168.24.203:9000/user/out"));
System.exit(job.waitForCompletion(true) ?0 : 1); //运行job
}
}
创建log4j.properties文件
在src目录下创建log4j.properties文件,内容如下
log4j.rootLogger=debug,stdout,R
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%5p - %m%n
log4j.appender.R=org.apache.log4j.RollingFileAppender
log4j.appender.R.File=mapreduce_test.log
log4j.appender.R.MaxFileSize=1MB
log4j.appender.R.MaxBackupIndex=1
log4j.appender.R.layout=org.apache.log4j.PatternLayout
log4j.appender.R.layout.ConversionPattern=%p %t %c - %m%n
log4j.logger.com.codefutures=DEBUG
11.
百度到的一下错误解决方法
常见错误及解决办法
1.错误:java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
错误原因:未正确配置环境变量
解决办法:配置环境变量HADOOP_HOME为D:\hadoop-2.7.1,另在Path变量后添加;%HADOOP_HOME%\bin
2.错误:Could not locate executable D:\hadoop-2.7.1\bin\winutils.exe in the Hadoop binaries.
错误原因:本地Hadoop运行目录的bin目录下中没有winutils.exe或者32位/64位版本不匹配
解决办法:下载相应的winutils.exe和hadoop.dll放到Hadoop运行目录的bin文件夹下,注意选择正确的32位/64位版本
3.错误:Exception in thread "main" java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z
错误原因:本地Hadoop运行目录的bin目录下中没有hadoop.dll或者32位/64位版本不匹配
解决办法:下载相应的hadoop.dll放到Hadoop运行目录的bin文件夹下,注意选择正确的32位/64位版本
4.错误:DEBUG org.apache.hadoop.util.NativeCodeLoader - Failed to load native-hadoop with error: java.lang.UnsatisfiedLinkError: HADOOP_HOME\bin\hadoop.dll: Can't load AMD 64-bit .dll on a IA 32-bit platform
错误原因:本地Hadoop运行目录的bin目录下中没有hadoop.dll版本不匹配,有32位和64位版
解决办法:下载正确的32位/64位版本的hadoop.dll放到Hadoop运行目录的bin文件夹下
5.错误:org.apache.hadoop.security.AccessControlException: org.apache.hadoop.security .AccessControlException: Permission denied: user=Administrator, access=WRITE, inode="hadoop": hadoop:supergroup:rwxr-xr-x
解决办法:其实这个错误的原因很容易看出来,用户在hadoop上执行写操作时被权限系统拒绝。有以下几种解决办法,可以分别试一试。
1)在系统的环境变量里面,添加一个的用户变量:HADOOP_USER_NAME,它的值为HADOOP环境下的用户名,比如hadoop(修改完重启eclipse,不然可能不生效)
2)将当前Windows系统的登录帐号修改为hadoop环境下的用户名,比如hadoop。
3)使用HDFS的命令行接口修改相应目录的权限: 比如要上传的文件路径为hdfs://djt002:9000/user/xxx.txt,则使用hadoop fs -chmod 777 /user 修改权限。 如果要上传的文件路径为hdfs://djt002:9000/java/xxx.txt,则要使用hadoop fs -chmod 777 /java或者hadoop fs -chmod 777 / 修改权限,此时需要先在HDFS里面建立Java目录。
4)关闭hadoop环境下的防火墙。
6.错误:Exception in thread "main" java.lang.UnsatisfiedLinkError: org.apache.hadoop.util.NativeCrc32.nativeComputeChunkedSumsByteArray(II[BI[BIILjava/lang/String;JZ)V
解决办法 :下载正确的32位/64位版本的hadoop.dll和winutils.exe拷贝到C:\Windows\System32目录下即可。
如果还有问题怎么办?
我们可以通过以下步骤来排查:
1)首先确保Windows下,系统位数、jdk位数、hadoop安装包位数保持一致,否则肯定会报错。 比如,64位的Windows系统,需要安装64位的jdk以及下载64位的hadoop安装包(课程中有下载)。
如果不知道hadoop位数是否正确,可以双击下面的文件。
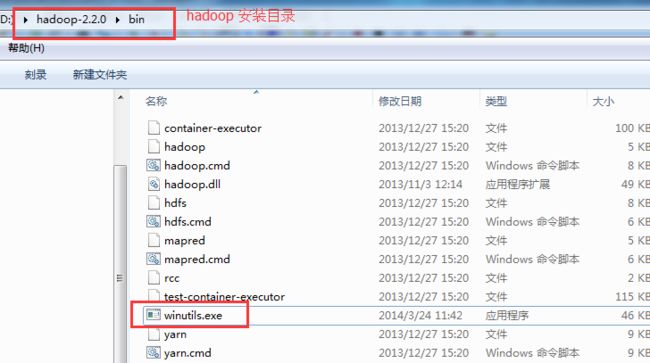
如果不出错,说明文件没有问题。如果hadoop的bin目录下没有hadoop.dll、winutils.exe这两个文件,在课程中下载。
2)确保jdk以及hadoop的环境变量配置正确(前面已经讲解)
3)确保Linux下的防火墙已经关闭。
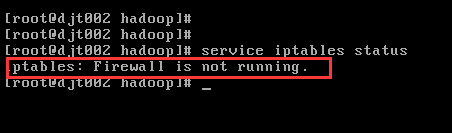
4)如果出现Eclipse访问不了hdfs,可以按照上面第5个问题的解决办法。
5)检查C:\Windows\System32目录下是否存在hadoop.dll和winutils.exe文件。
6)如果以上方法还是有错误,可能是系统或者Eclipse版本的原因造成的,最糟糕的情况可能需要换一个干净的Windows系统了。